Can LLMs Cook Jamaican Couscous? A Study of Cultural Novelty in Recipe Generation
作者: F. Carichon, R. Rampa, G. Farnadi
分类: cs.AI
发布日期: 2026-02-11
备注: 14 pages, 12 figures, conference
💡 一句话要点
研究表明大型语言模型在食谱生成中未能有效进行文化适应,与人类表现存在显著差异。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文化适应 食谱生成 跨文化内容创作 文化偏见 GlobalFusion数据集 文化距离
📋 核心要点
- 现有大型语言模型在生成文化内容时存在文化偏见,可能导致刻板印象和文化同质化。
- 该研究通过分析LLM生成的跨文化食谱,评估其文化适应能力,并与人类食谱进行对比。
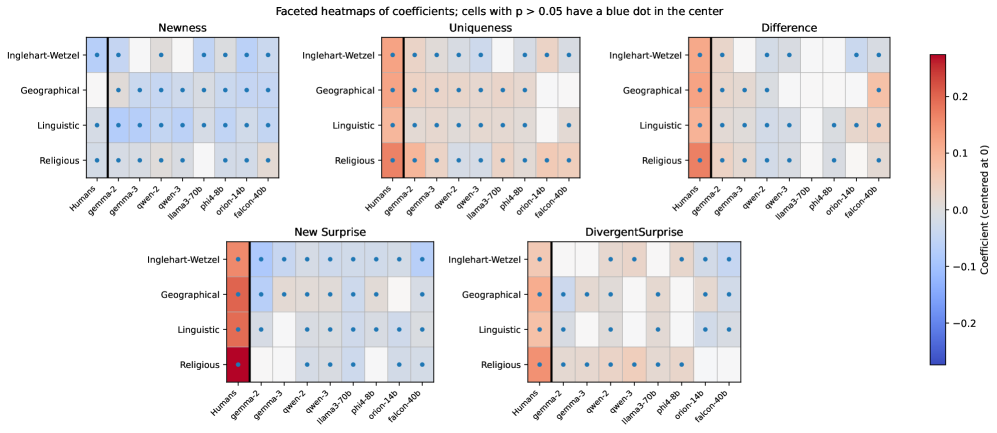
- 实验表明LLM生成的食谱未能有效进行文化适应,其差异与文化距离无关,文化信息保存较弱。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于生成和塑造文化内容,从叙事写作到艺术创作。虽然这些模型展示了令人印象深刻的流畅性和生成能力,但先前的工作表明,它们也表现出系统性的文化偏见,引发了对刻板印象、同质化和文化特定表达形式的抹杀的担忧。理解LLMs是否能够有意义地与主流文化之外的多元文化保持一致仍然是一个关键挑战。本文通过烹饪食谱这一视角研究了LLMs中的文化适应性,食谱是一个文化、传统和创造力紧密交织的领域。我们基于 extit{GlobalFusion}数据集,该数据集根据已建立的文化距离度量标准配对了来自不同国家的人类食谱。使用相同的国家对,我们使用多个LLMs生成了文化适应的食谱,从而可以直接比较人类和LLM在跨文化内容创作中的行为。我们的分析表明,LLMs未能产生具有文化代表性的改编。与人类不同,它们生成的食谱的差异与文化距离无关。我们进一步解释了这种差距。我们表明,文化信息在内部模型表示中保存较弱,模型通过误解创造力和传统等概念来夸大其作品的新颖性,并且它们未能识别适应及其相关国家,也未能将其植根于具有文化意义的要素(如成分)中。这些发现突出了当前LLMs在面向文化的生成方面的根本局限性,并对其在文化敏感型应用中的使用具有重要意义。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在生成食谱时,能否有效地进行文化适应。现有方法,即直接使用LLMs生成食谱,存在无法准确捕捉和表达不同文化之间细微差异的痛点,可能导致生成的食谱缺乏文化代表性,甚至产生文化刻板印象。
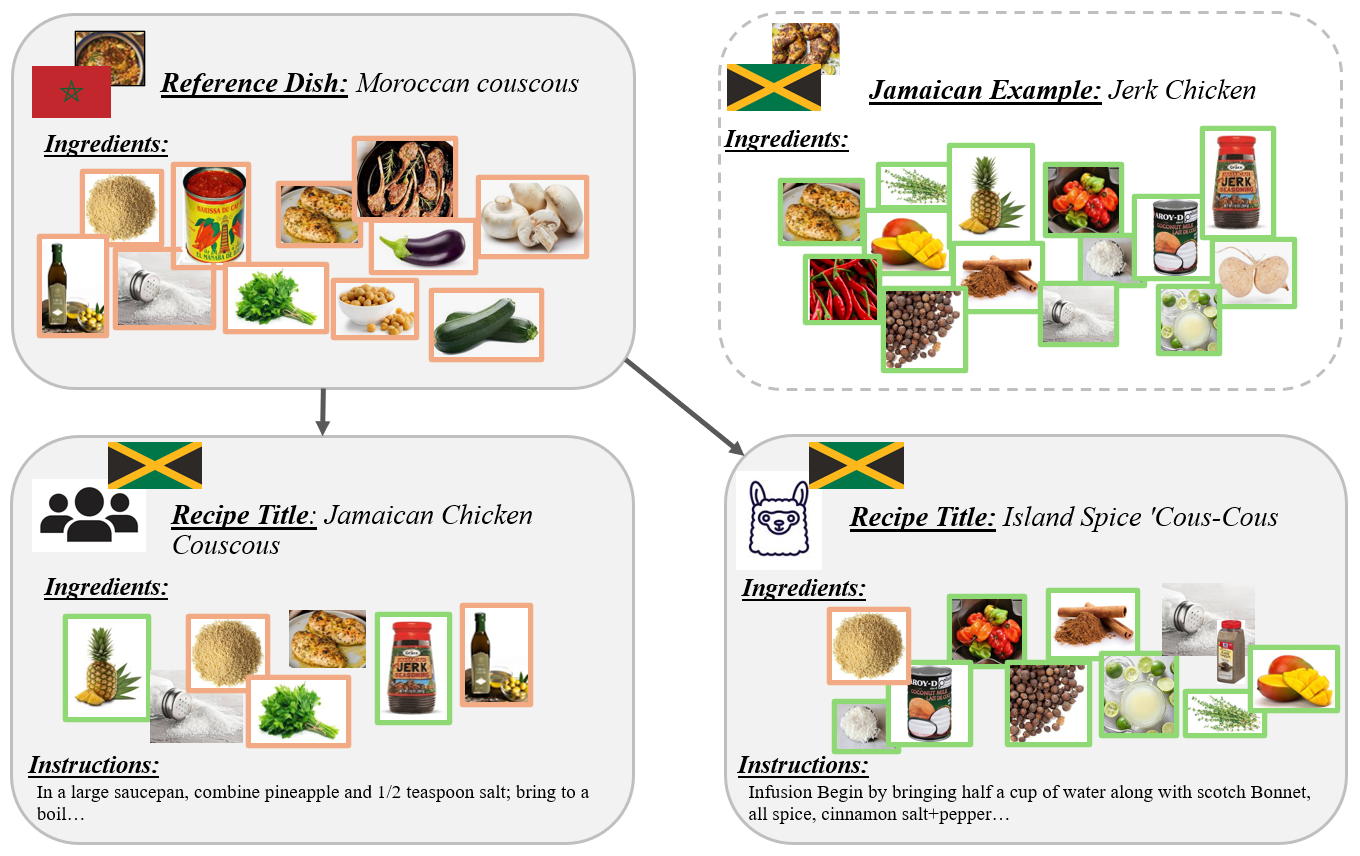
核心思路:论文的核心思路是通过比较LLMs和人类在跨文化食谱生成中的行为,评估LLMs的文化适应能力。具体来说,研究者使用 extit{GlobalFusion}数据集,该数据集包含了根据文化距离配对的不同国家的人类食谱,然后使用LLMs生成相应的跨文化食谱,并分析LLMs生成的食谱与人类食谱之间的差异。
技术框架:研究的整体框架包括以下几个步骤:1) 选择 extit{GlobalFusion}数据集,该数据集包含不同国家的人类食谱,并根据文化距离进行了配对。2) 使用多个LLMs(具体模型未知)生成跨文化食谱,即给定一个国家的食谱,要求LLM生成另一个国家的类似食谱。3) 分析LLMs生成的食谱与原始食谱以及人类生成的食谱之间的差异,评估LLMs的文化适应能力。4) 探究LLMs未能有效进行文化适应的原因,例如文化信息在模型内部表示中的保存情况,以及模型对创造力、传统等概念的理解。
关键创新:论文的关键创新在于其研究视角,即通过分析LLMs在食谱生成中的文化适应能力,来评估LLMs在文化内容生成方面的局限性。与以往的研究主要关注LLMs的生成能力和流畅性不同,该研究更加关注LLMs对文化信息的理解和表达能力。
关键设计:论文的关键设计包括:1) 使用 extit{GlobalFusion}数据集,该数据集提供了用于评估文化距离的基准。2) 使用多个LLMs进行实验,以提高结果的可靠性。3) 分析LLMs生成的食谱与人类食谱之间的差异,并探究LLMs未能有效进行文化适应的原因。具体的参数设置、损失函数、网络结构等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
研究表明,LLMs生成的食谱的差异与文化距离无关,这与人类的表现形成鲜明对比。此外,研究还发现文化信息在LLM内部表示中保存较弱,模型对创造力和传统等概念存在误解,并且未能将适应与相关国家联系起来,也未能将其植根于具有文化意义的要素中。这些发现揭示了当前LLMs在文化内容生成方面的根本局限性。
🎯 应用场景
该研究成果可应用于改进LLM在文化内容生成方面的能力,例如生成更具文化代表性的文本、图像和音乐。此外,该研究还可以帮助人们更好地理解LLM的局限性,避免在文化敏感型应用中过度依赖LLM,从而减少文化刻板印象和文化同质化的风险。未来的研究可以探索如何将文化知识融入LLM的训练过程中,以提高其文化适应能力。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used to generate and shape cultural content, ranging from narrative writing to artistic production. While these models demonstrate impressive fluency and generative capacity, prior work has shown that they also exhibit systematic cultural biases, raising concerns about stereotyping, homogenization, and the erasure of culturally specific forms of expression. Understanding whether LLMs can meaningfully align with diverse cultures beyond the dominant ones remains a critical challenge. In this paper, we study cultural adaptation in LLMs through the lens of cooking recipes, a domain in which culture, tradition, and creativity are tightly intertwined. We build on the \textit{GlobalFusion} dataset, which pairs human recipes from different countries according to established measures of cultural distance. Using the same country pairs, we generate culturally adapted recipes with multiple LLMs, enabling a direct comparison between human and LLM behavior in cross-cultural content creation. Our analysis shows that LLMs fail to produce culturally representative adaptations. Unlike humans, the divergence of their generated recipes does not correlate with cultural distance. We further provide explanations for this gap. We show that cultural information is weakly preserved in internal model representations, that models inflate novelty in their production by misunderstanding notions such as creativity and tradition, and that they fail to identify adaptation with its associated countries and to ground it in culturally salient elements such as ingredients. These findings highlight fundamental limitations of current LLMs for culturally oriented generation and have important implications for their use in culturally sensitive applications.