Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics
作者: Leheng Sheng, Wenchang Ma, Ruixin Hong, Xiang Wang, An Zhang, Tat-Seng Chua
分类: cs.AI, cs.LG
发布日期: 2026-02-11
备注: 21 pages
💡 一句话要点
提出RLCER,利用自进化规则增强思维链推理,无需人工标注。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链推理 强化学习 自进化规则 大型语言模型 奖励模型
📋 核心要点
- 现有CoT奖励方法依赖人工标注,成本高昂且难以适应CoT分布的演变。
- RLCER通过自进化规则奖励CoT,无需人工标注,实现自主CoT奖励。
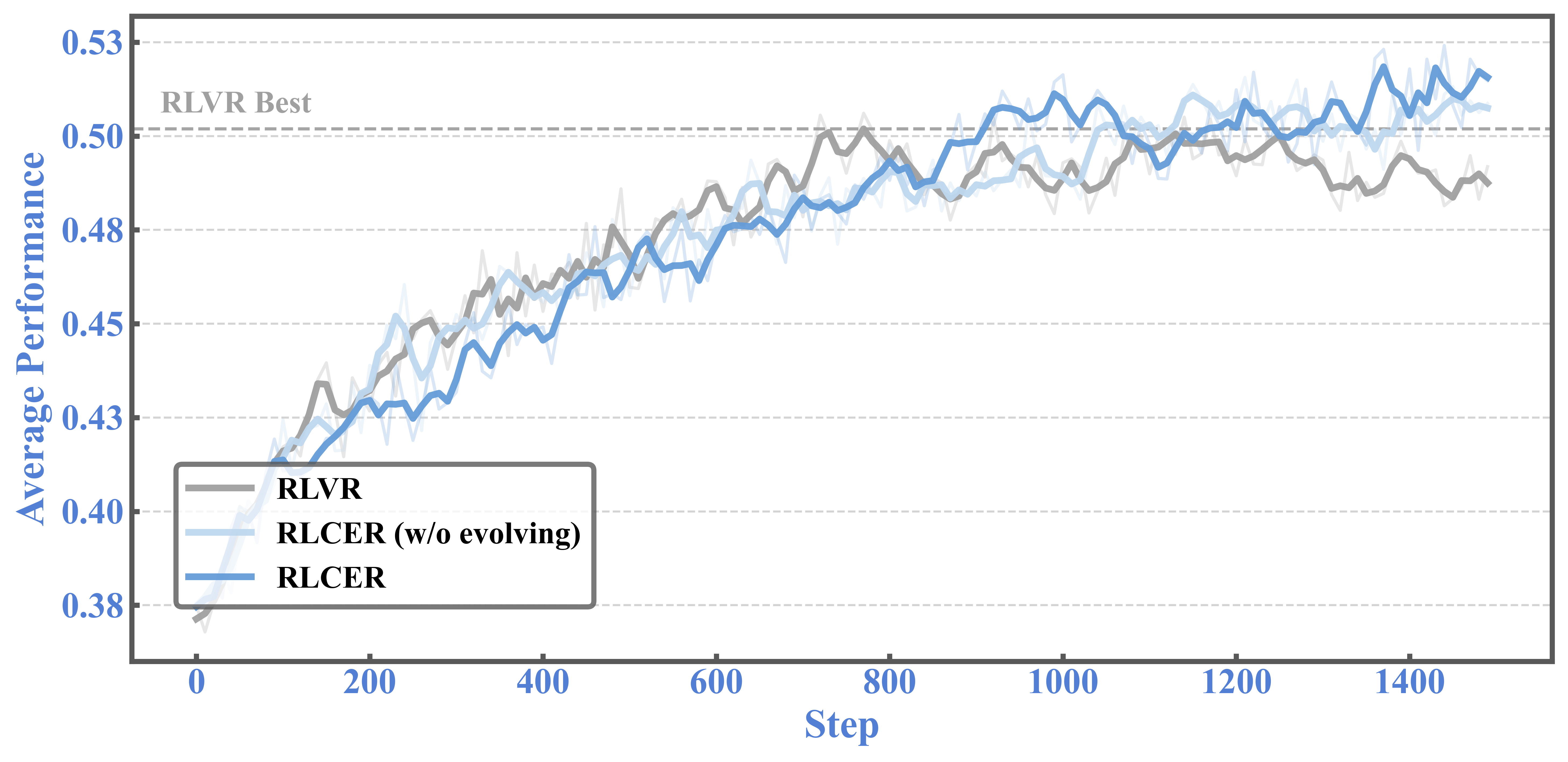
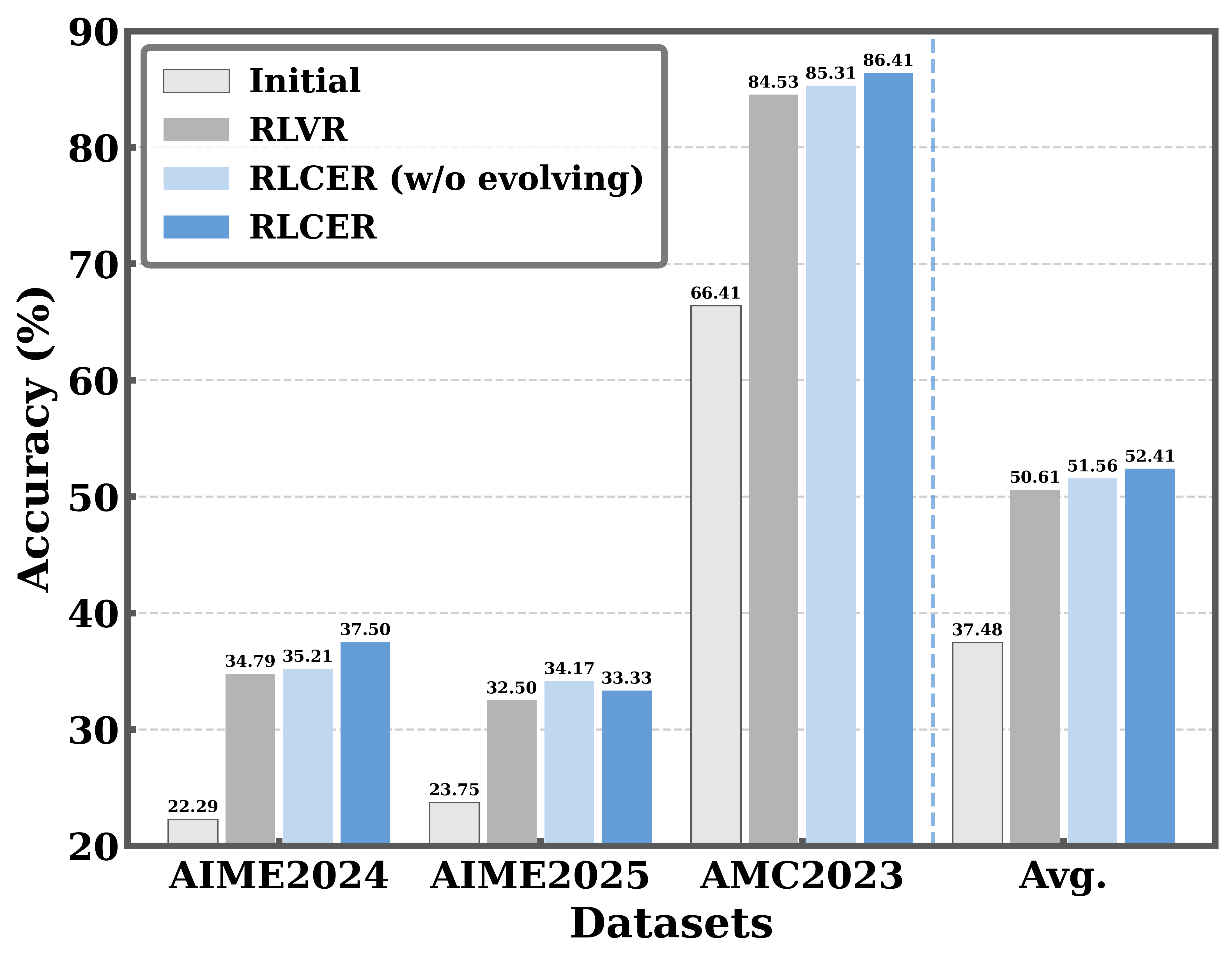
- 实验表明,RLCER优于以结果为中心的RLVR,且自进化规则可提升推理性能。
📝 摘要(中文)
尽管思维链(CoT)在大型语言模型(LLM)推理中起着关键作用,但直接奖励CoT是困难的:训练奖励模型需要大量的人工标注工作,并且静态奖励模型难以适应不断演变的CoT分布和奖励黑客攻击。这些挑战促使我们寻求一种自主的CoT奖励方法,该方法不需要人工标注工作并且可以逐步演变。受到最近的自进化训练方法的启发,我们提出了RLCER(通过自进化规则进行CoT监督的强化学习),它通过使用自提出和自进化的规则来奖励CoT,从而增强了以结果为中心的RLVR。我们表明,即使没有结果奖励,自提出和自进化的规则也能提供可靠的CoT监督信号,使RLCER优于以结果为中心的RLVR。此外,当用作提示中的提示时,这些自提出的规则进一步提高了推理时的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中,对思维链(CoT)进行有效奖励的难题。现有方法,如训练奖励模型,需要大量人工标注,成本高昂。此外,静态奖励模型难以适应CoT分布的动态变化,容易受到奖励黑客攻击,导致模型性能下降。
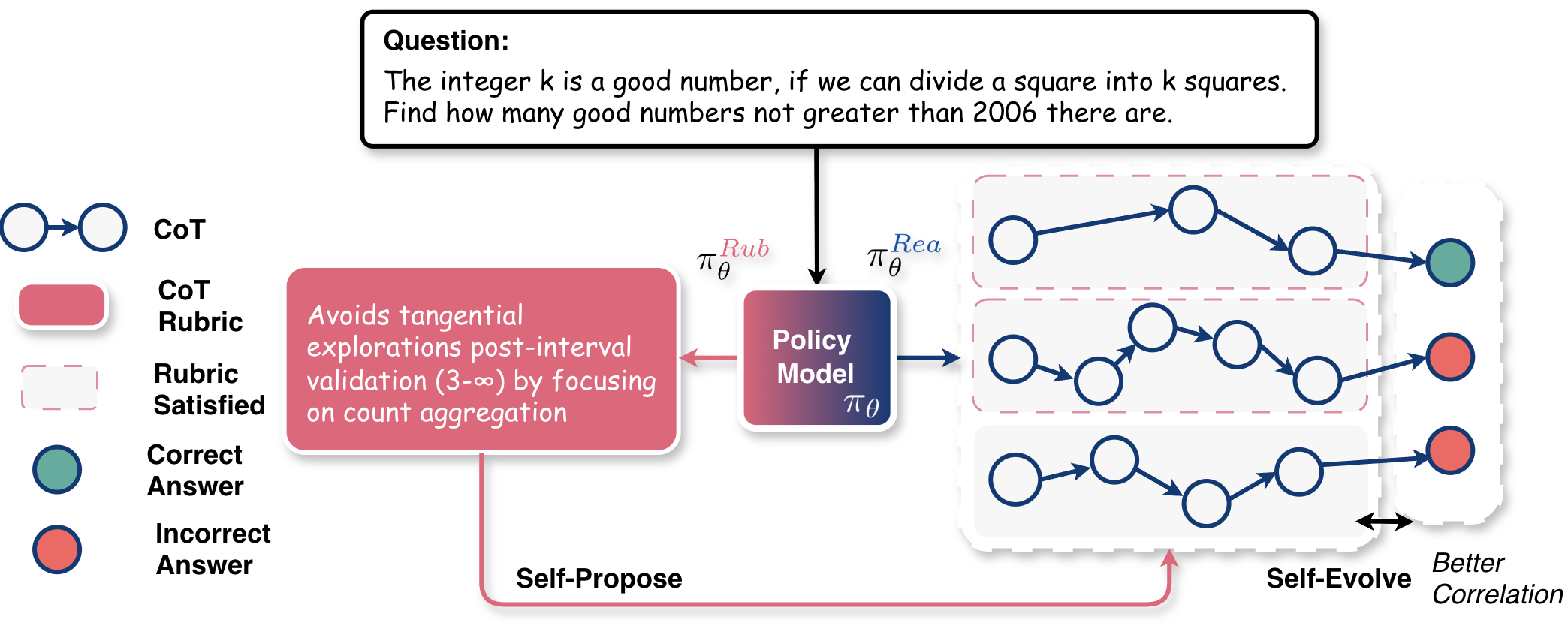
核心思路:论文的核心思路是利用自进化规则来奖励CoT,从而避免人工标注的需要。通过让模型自动生成和演化规则,可以更好地适应CoT分布的变化,并减少奖励黑客的风险。这种方法旨在实现一种自主、可扩展的CoT奖励机制。
技术框架:RLCER(Reinforcement Learning with CoT Supervision via Self-Evolving Rubrics)框架主要包含以下几个阶段:1) 模型生成CoT推理过程;2) 模型基于自身生成的规则对CoT进行评估和奖励;3) 基于奖励信号,使用强化学习算法更新模型参数,优化CoT生成策略;4) 模型根据CoT的质量和奖励反馈,不断演化和改进自身的评估规则。
关键创新:RLCER的关键创新在于引入了自进化规则的概念,用于CoT的奖励。与传统的静态奖励模型或依赖人工标注的奖励模型不同,RLCER能够自动生成和演化规则,从而更好地适应CoT分布的变化,并减少人工干预。这种自适应的奖励机制是RLCER的核心优势。
关键设计:RLCER的关键设计包括:1) 如何设计规则生成和演化机制,使其能够有效地捕捉CoT的质量;2) 如何将自进化规则与强化学习算法相结合,以优化CoT生成策略;3) 如何平衡规则的探索和利用,避免规则陷入局部最优。具体的损失函数和网络结构等细节,论文中可能未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
RLCER在实验中表现出优于以结果为中心的RLVR的性能,证明了自进化规则在CoT监督中的有效性。即使在没有结果奖励的情况下,RLCER也能提供可靠的CoT监督信号。此外,将自提出的规则作为提示,可以进一步提高推理时的性能。具体的性能提升幅度,论文中可能未给出详细数据,属于未知信息。
🎯 应用场景
RLCER可应用于各种需要复杂推理能力的自然语言处理任务,如问答系统、文本摘要、机器翻译等。通过提升LLM的推理能力,可以提高这些应用在准确性、可靠性和可解释性方面的性能。该研究还有助于开发更智能、更自主的AI系统,减少对人工标注的依赖。
📄 摘要(原文)
Despite chain-of-thought (CoT) playing crucial roles in LLM reasoning, directly rewarding it is difficult: training a reward model demands heavy human labeling efforts, and static RMs struggle with evolving CoT distributions and reward hacking. These challenges motivate us to seek an autonomous CoT rewarding approach that requires no human annotation efforts and can evolve gradually. Inspired by recent self-evolving training methods, we propose \textbf{RLCER} (\textbf{R}einforcement \textbf{L}earning with \textbf{C}oT Supervision via Self-\textbf{E}volving \textbf{R}ubrics), which enhances the outcome-centric RLVR by rewarding CoTs with self-proposed and self-evolving rubrics. We show that self-proposed and self-evolving rubrics provide reliable CoT supervision signals even without outcome rewards, enabling RLCER to outperform outcome-centric RLVR. Moreover, when used as in-prompt hints, these self-proposed rubrics further improve inference-time performance.