See, Plan, Snap: Evaluating Multimodal GUI Agents in Scratch
作者: Xingyi Zhang, Yulei Ye, Kaifeng Huang, Wenhao Li, Xiangfeng Wang
分类: cs.AI
发布日期: 2026-02-11
💡 一句话要点
提出 ScratchWorld 基准测试,评估多模态 GUI 智能体在 Scratch 中的编程能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI 智能体 多模态学习 基准测试 Scratch 低代码教育 程序构建 视觉运动控制
📋 核心要点
- 现有的低代码教育中,基于 Block 的编程环境(如 Scratch)至关重要,但 AI 智能体通过 GUI 构建程序的能力评估不足。
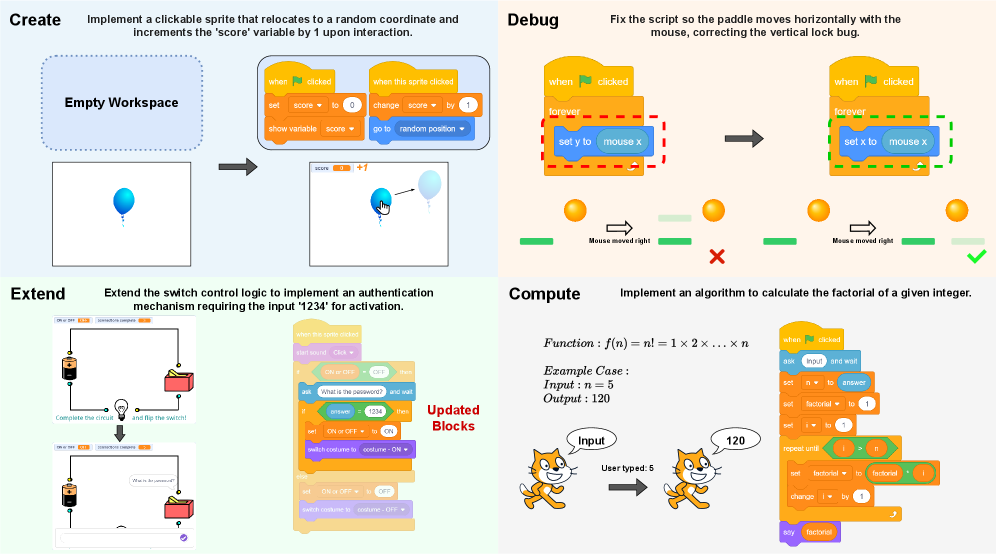
- 论文构建 ScratchWorld 基准,通过 Use-Modify-Create 框架,提供不同难度和类型的编程任务,评估智能体的编程能力。
- 实验表明,现有模型在 ScratchWorld 上表现出显著的推理-行动差距,尤其是在细粒度 GUI 操作方面面临挑战。
📝 摘要(中文)
本文提出了 ScratchWorld,一个用于评估多模态 GUI 智能体在 Scratch 中构建程序能力的基准测试。ScratchWorld 基于 Use-Modify-Create 教学框架,包含 83 个精心设计的任务,涵盖 Create、Debug、Extend 和 Compute 四个不同的问题类别。为了严格诊断智能体失败的原因,该基准测试采用两种互补的交互模式:primitive 模式需要细粒度的拖放操作,以直接评估视觉运动控制;composite 模式使用高级语义 API,将程序推理与 GUI 执行分离。为了确保可靠的评估,本文提出了一种基于执行的评估协议,通过浏览器环境中的运行时测试来验证构建的 Scratch 程序的功能正确性。对最先进的多模态语言模型和 GUI 智能体进行的大量实验表明,存在显著的推理-行动差距,突显了在细粒度 GUI 操作中持续存在的挑战,即使智能体具有强大的规划能力。
🔬 方法详解
问题定义:现有方法缺乏对 AI 智能体在图形用户界面(GUI)中构建程序能力的有效评估,尤其是在低代码教育领域常用的 Scratch 等 Block-based 编程环境中。现有的评估方法可能无法充分衡量智能体在视觉运动控制、程序推理和 GUI 执行方面的综合能力。
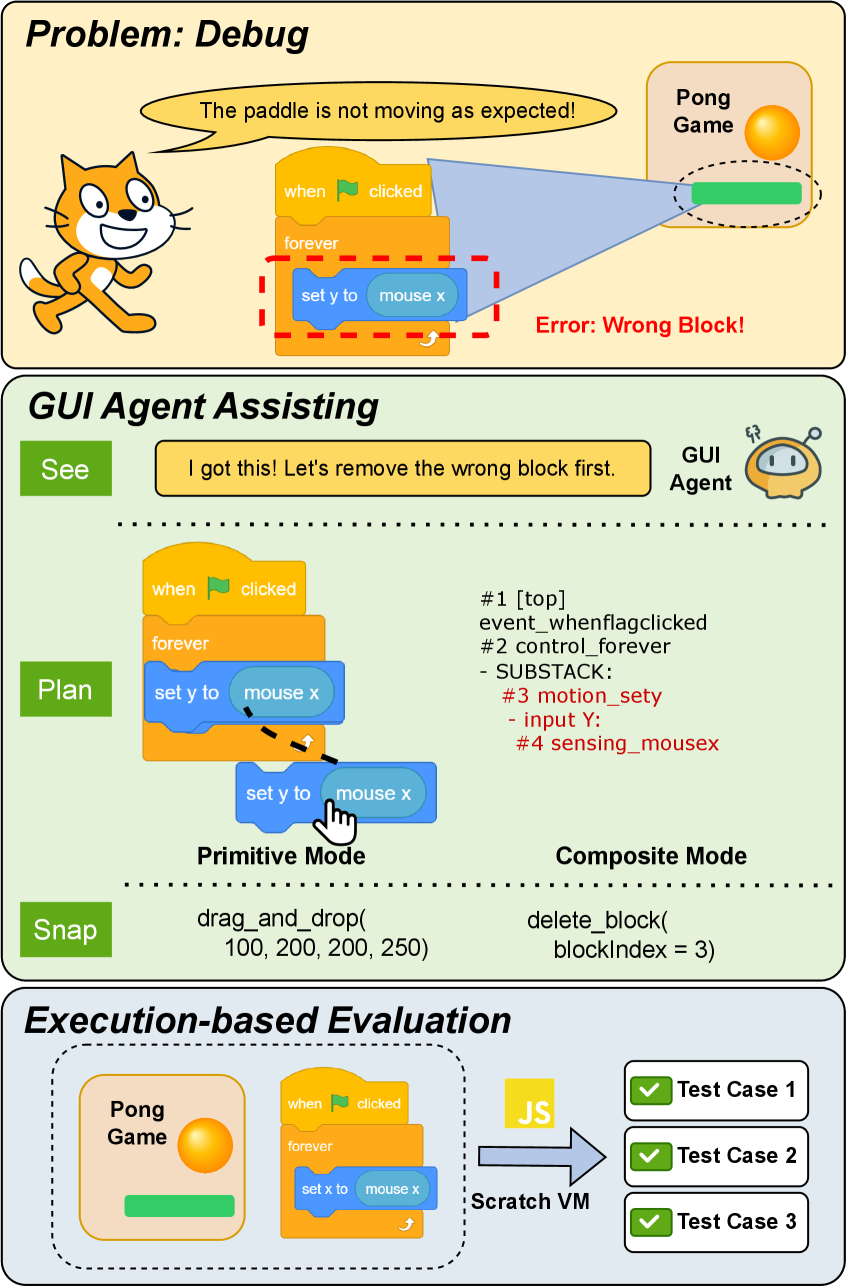
核心思路:论文的核心思路是构建一个专门针对 Scratch 环境的基准测试 ScratchWorld,该基准测试能够提供多样化的编程任务,并采用不同的交互模式来解耦程序推理和 GUI 执行,从而更全面地评估智能体的编程能力。通过提供细粒度的拖放操作和高级语义 API,可以更精确地诊断智能体失败的原因。
技术框架:ScratchWorld 包含 83 个任务,分为 Create、Debug、Extend 和 Compute 四个类别。它支持两种交互模式:primitive 模式(细粒度拖放操作)和 composite 模式(高级语义 API)。评估协议基于执行结果,通过在浏览器环境中运行测试用例来验证程序的正确性。整体流程包括:智能体接收任务描述,根据任务需求选择合适的交互模式,生成 Scratch 程序,然后通过执行评估协议来验证程序的正确性。
关键创新:ScratchWorld 的关键创新在于其针对 Scratch 环境的定制化设计,以及其提供的两种互补的交互模式。primitive 模式可以评估智能体的视觉运动控制能力,而 composite 模式可以专注于程序推理。此外,基于执行的评估协议能够更准确地评估程序的实际功能。
关键设计:任务设计基于 Use-Modify-Create 教学框架,涵盖不同难度和类型的编程任务。两种交互模式的设计允许对智能体的不同能力进行解耦评估。评估协议通过预定义的测试用例来验证程序的正确性,并提供详细的错误报告。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有的多模态语言模型和 GUI 智能体在 ScratchWorld 上表现出显著的推理-行动差距。即使智能体具有强大的规划能力,在细粒度 GUI 操作方面仍然面临挑战。具体性能数据未在摘要中给出,但强调了现有方法在 ScratchWorld 上的不足。
🎯 应用场景
该研究成果可应用于低代码教育领域,帮助开发更智能的编程辅助工具,提升学生的编程学习体验。同时,该基准测试也可用于评估和改进多模态 GUI 智能体的性能,推动 AI 在自动化软件开发、人机交互等领域的应用。
📄 摘要(原文)
Block-based programming environments such as Scratch play a central role in low-code education, yet evaluating the capabilities of AI agents to construct programs through Graphical User Interfaces (GUIs) remains underexplored. We introduce ScratchWorld, a benchmark for evaluating multimodal GUI agents on program-by-construction tasks in Scratch. Grounded in the Use-Modify-Create pedagogical framework, ScratchWorld comprises 83 curated tasks spanning four distinct problem categories: Create, Debug, Extend, and Compute. To rigorously diagnose the source of agent failures, the benchmark employs two complementary interaction modes: primitive mode requires fine-grained drag-and-drop manipulation to directly assess visuomotor control, while composite mode uses high-level semantic APIs to disentangle program reasoning from GUI execution. To ensure reliable assessment, we propose an execution-based evaluation protocol that validates the functional correctness of the constructed Scratch programs through runtime tests within the browser environment. Extensive experiments across state-of-the-art multimodal language models and GUI agents reveal a substantial reasoning--acting gap, highlighting persistent challenges in fine-grained GUI manipulation despite strong planning capabilities.