To Think or Not To Think, That is The Question for Large Reasoning Models in Theory of Mind Tasks
作者: Nanxu Gong, Haotian Li, Sixun Dong, Jianxun Lian, Yanjie Fu, Xing Xie
分类: cs.AI, cs.CL
发布日期: 2026-02-11
💡 一句话要点
研究表明大型推理模型在心理理论任务中表现不稳定,需开发专用能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心理理论 大型语言模型 社会认知 推理能力 自适应推理
📋 核心要点
- 现有大型推理模型在形式推理任务表现出色,但在社会认知推理(心理理论)任务中表现不佳。
- 通过对比推理模型与非推理模型在心理理论基准上的表现,揭示推理模型在特定情况下反而表现更差。
- 提出了自适应推理和捷径预防两种干预方法,验证并缓解了推理模型在心理理论任务中的问题。
📝 摘要(中文)
心理理论(ToM)评估模型推断隐藏心理状态(如信念、欲望和意图)的能力,这对于自然社交互动至关重要。尽管大型推理模型(LRM)的最新进展推动了数学和编码中的逐步推理,但这种优势是否能转移到社会认知技能上仍未得到充分探索。本文对九个先进的大型语言模型(LLM)进行了系统研究,比较了推理模型和非推理模型在三个代表性的ToM基准上的表现。结果表明,推理模型并不总是优于非推理模型,有时甚至表现更差。细粒度分析揭示了三个见解。首先,慢思考会崩溃:随着响应变长,准确率显著下降,更大的推理预算会损害性能。其次,适度和自适应的推理有益于性能:约束推理长度可以减轻失败,而不同的成功模式表明动态适应的必要性。第三,选项匹配捷径:当删除多项选择选项时,推理模型会显著改进,表明依赖于选项匹配而不是真正的演绎。我们还设计了两种干预方法:慢到快(S2F)自适应推理和思考到匹配(T2M)捷径预防,以进一步验证和缓解这些问题。总而言之,我们的研究强调了LRM在形式推理(例如,数学、代码)方面的进步不能完全转移到ToM(一种典型的社会推理任务)上。我们得出结论,实现稳健的ToM需要开发超越现有推理方法的独特能力。
🔬 方法详解
问题定义:论文旨在研究大型推理模型(LRMs)在心理理论(ToM)任务中的表现。现有方法,即直接应用在形式推理(如数学、代码)中表现良好的LRMs,在ToM任务中存在表现不稳定甚至下降的问题。痛点在于LRMs可能依赖于表面线索或捷径,而非真正的心理状态推理。
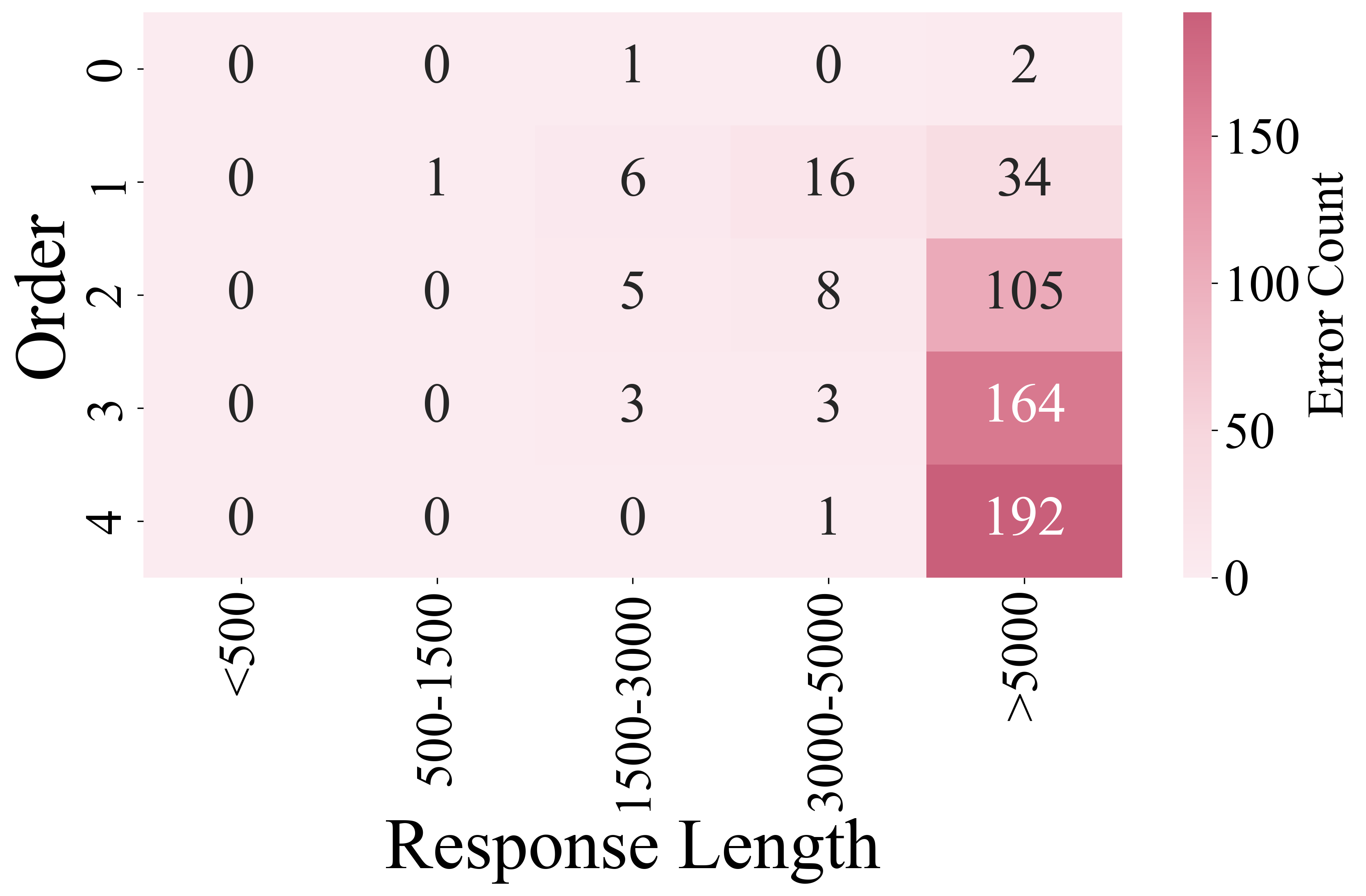
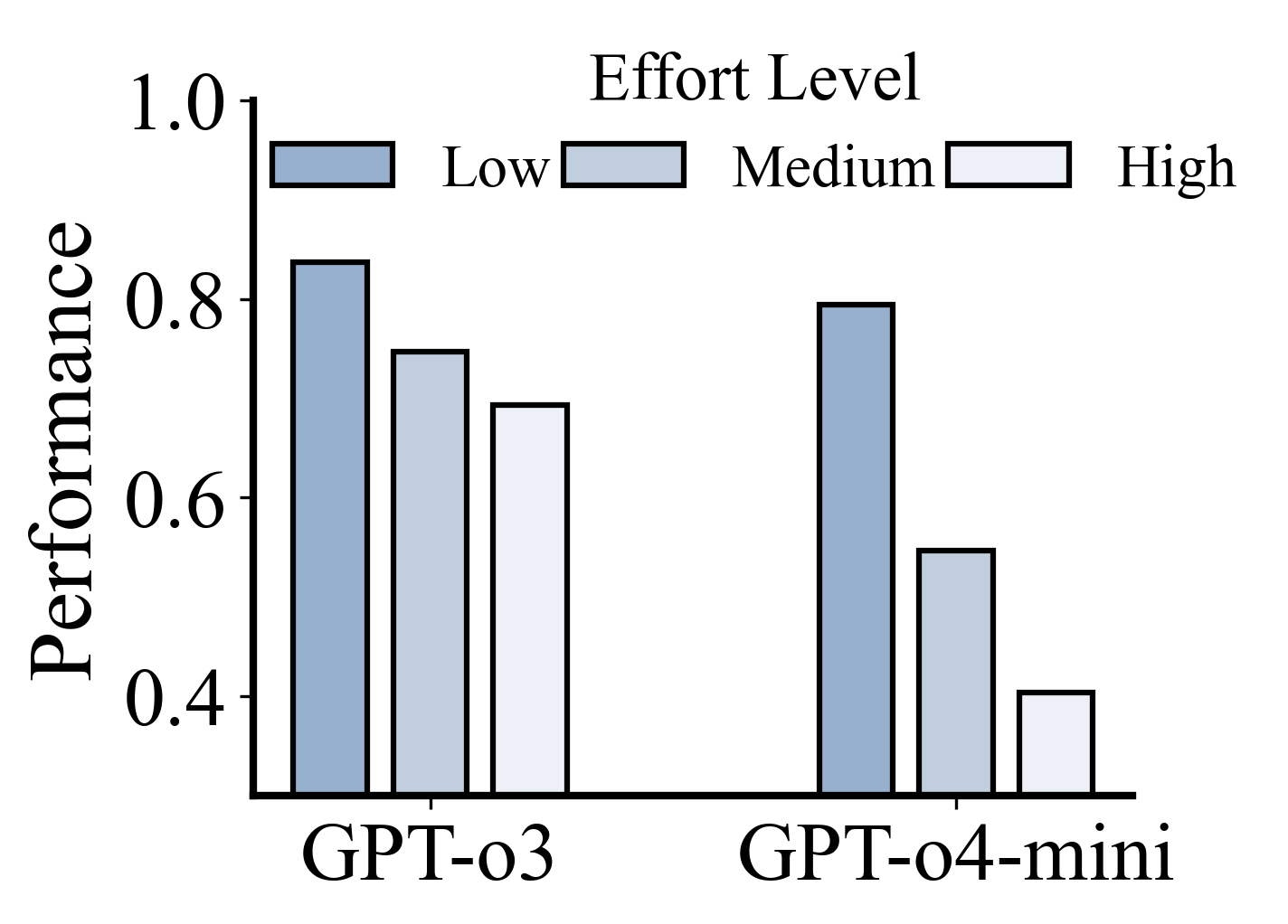
核心思路:论文的核心思路是通过对比实验,分析LRMs在ToM任务中的推理过程,揭示其失败的原因,并提出干预措施。通过细粒度分析,发现LRMs存在“慢思考崩溃”、“选项匹配捷径”等问题。基于此,提出了自适应推理和捷径预防策略。
技术框架:论文主要采用实验研究方法。首先,选择九个先进的LLMs,包括推理模型和非推理模型。然后,在三个代表性的ToM基准上进行测试。接着,对实验结果进行细粒度分析,识别问题。最后,设计两种干预方法(Slow-to-Fast自适应推理和Think-to-Match捷径预防)来验证和缓解问题。整体流程是:模型选择 -> 基准测试 -> 结果分析 -> 干预设计 -> 实验验证。
关键创新:论文的关键创新在于揭示了LRMs在ToM任务中存在的局限性,并提出了相应的干预措施。具体来说,发现了“慢思考崩溃”和“选项匹配捷径”两种现象,这表明LRMs在社会认知推理中可能存在过度依赖表面信息或不当推理策略的问题。提出的自适应推理和捷径预防策略旨在引导模型进行更深入、更真实的心理状态推理。
关键设计:论文的关键设计包括:1) 选择具有代表性的ToM基准,以全面评估LRMs的ToM能力;2) 设计细粒度分析方法,例如分析响应长度与准确率的关系,以及移除选项后的性能变化,以揭示LRMs的推理过程;3) 设计Slow-to-Fast自适应推理策略,允许模型根据任务难度动态调整推理步数;4) 设计Think-to-Match捷径预防策略,通过修改输入提示,减少模型对选项匹配的依赖。
🖼️ 关键图片

📊 实验亮点
实验结果表明,推理模型在ToM任务中并不总是优于非推理模型,有时甚至表现更差。细粒度分析发现,随着响应长度增加,准确率显著下降(慢思考崩溃)。移除选项后,推理模型性能显著提升,表明存在选项匹配捷径。通过提出的自适应推理和捷径预防策略,可以有效提升LRMs在ToM任务中的表现。
🎯 应用场景
该研究成果可应用于提升AI在社交互动中的智能水平,例如在人机对话、智能助手、社交机器人等领域。通过改进AI的心理理论能力,可以使其更好地理解人类意图、预测行为,从而实现更自然、更有效的沟通与协作。未来的研究可以进一步探索更有效的心理理论建模方法,并将其应用于更复杂的社会情境。
📄 摘要(原文)
Theory of Mind (ToM) assesses whether models can infer hidden mental states such as beliefs, desires, and intentions, which is essential for natural social interaction. Although recent progress in Large Reasoning Models (LRMs) has boosted step-by-step inference in mathematics and coding, it is still underexplored whether this benefit transfers to socio-cognitive skills. We present a systematic study of nine advanced Large Language Models (LLMs), comparing reasoning models with non-reasoning models on three representative ToM benchmarks. The results show that reasoning models do not consistently outperform non-reasoning models and sometimes perform worse. A fine-grained analysis reveals three insights. First, slow thinking collapses: accuracy significantly drops as responses grow longer, and larger reasoning budgets hurt performance. Second, moderate and adaptive reasoning benefits performance: constraining reasoning length mitigates failure, while distinct success patterns demonstrate the necessity of dynamic adaptation. Third, option matching shortcut: when multiple choice options are removed, reasoning models improve markedly, indicating reliance on option matching rather than genuine deduction. We also design two intervention approaches: Slow-to-Fast (S2F) adaptive reasoning and Think-to-Match (T2M) shortcut prevention to further verify and mitigate the problems. With all results, our study highlights the advancement of LRMs in formal reasoning (e.g., math, code) cannot be fully transferred to ToM, a typical task in social reasoning. We conclude that achieving robust ToM requires developing unique capabilities beyond existing reasoning methods.