MERIT Feedback Elicits Better Bargaining in LLM Negotiators
作者: Jihwan Oh, Murad Aghazada, Yooju Shin, Se-Young Yun, Taehyeon Kim
分类: cs.AI
发布日期: 2026-02-11
备注: Preprint. arXiv admin note: substantial text overlap with arXiv:2505.22998
💡 一句话要点
提出基于效用反馈的框架,提升LLM谈判者在复杂场景下的议价能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 谈判策略 效用理论 人机交互 强化学习
📋 核心要点
- 现有LLM在谈判场景中缺乏足够的战略深度,难以适应复杂的人为因素,导致谈判效果不佳。
- 论文提出以效用反馈为中心的框架,通过经济学指标和人类偏好数据,提升LLM的议价能力。
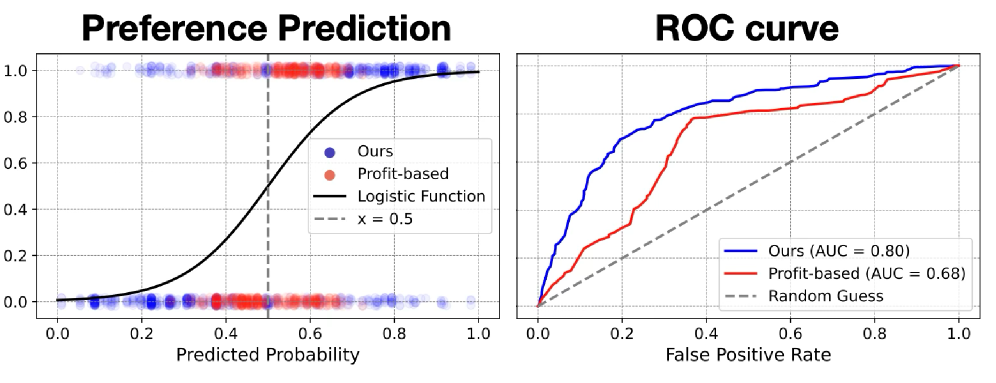
- 实验表明,该机制能显著提高谈判性能,使LLM展现出更深层次的战略行为和更强的对手意识。
📝 摘要(中文)
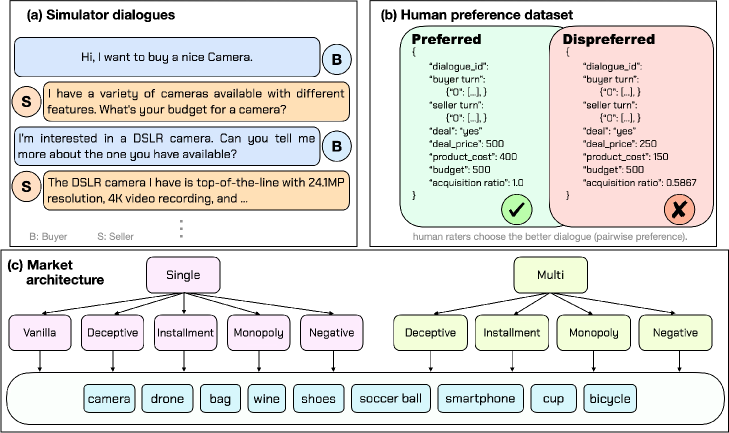
大型语言模型(LLM)在谈判中表现不佳,因为它们缺乏战略深度,难以适应复杂的人为因素。为了解决这个问题,论文提出了一个以效用反馈为中心的框架。主要贡献包括:(i) AgoraBench,一个新的基准测试,涵盖九个具有挑战性的设置(例如,欺骗、垄断),支持多样化的策略建模;(ii) 从效用理论中推导出的、与人类对齐的、经济上有根据的指标,通过代理效用、谈判能力和获取比率来衡量谈判与人类偏好的一致性;(iii) 一个人为偏好数据集,以及通过提示和微调来增强LLM议价能力的学习流程。实验结果表明,基线LLM策略通常与人类偏好不同,而论文提出的机制显著提高了谈判性能,产生了更深层次的战略行为和更强的对手意识。
🔬 方法详解
问题定义:论文旨在解决LLM在复杂谈判场景中表现不佳的问题。现有方法的痛点在于LLM缺乏足够的战略深度,难以理解和适应人类的偏好和行为,导致谈判结果与人类期望存在偏差。特别是在欺骗、垄断等复杂场景下,LLM的弱点更加明显。
核心思路:论文的核心思路是通过效用反馈来引导LLM的学习和决策。效用反馈基于经济学理论,能够量化谈判结果对参与者的价值,并与人类偏好对齐。通过让人类对LLM的谈判结果进行评价,并将这些评价作为反馈信号,可以帮助LLM更好地理解人类的偏好,并学习更有效的谈判策略。
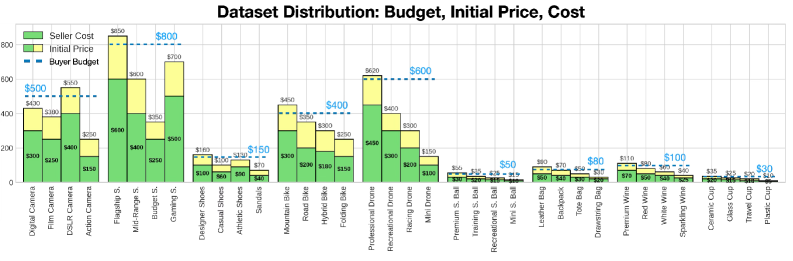
技术框架:整体框架包含三个主要部分:1) AgoraBench基准测试,用于评估LLM在不同谈判场景下的表现;2) 基于效用理论的评估指标,包括代理效用、谈判能力和获取比率,用于量化谈判结果的质量;3) 人类偏好数据集和学习流程,用于通过提示和微调来增强LLM的议价能力。学习流程利用人类对谈判结果的偏好作为监督信号,训练LLM学习更符合人类期望的谈判策略。
关键创新:论文的关键创新在于将经济学中的效用理论引入到LLM的谈判研究中,并构建了一个以效用反馈为中心的学习框架。与传统的基于规则或模仿学习的方法不同,该框架能够直接优化LLM的谈判结果,使其更符合人类的偏好。此外,AgoraBench基准测试的提出也为LLM谈判研究提供了一个更具挑战性和多样性的评估平台。
关键设计:在学习流程中,论文采用了提示和微调两种方法来增强LLM的议价能力。提示方法通过向LLM提供关于人类偏好的信息,引导其生成更符合人类期望的谈判策略。微调方法则利用人类偏好数据集,通过监督学习的方式,训练LLM学习更有效的谈判策略。具体的损失函数设计未知,但推测是基于人类偏好排序的损失函数,例如pairwise ranking loss。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的机制能够显著提高LLM的谈判性能。在AgoraBench基准测试中,经过效用反馈训练的LLM在多个指标上都优于基线模型,展现出更深层次的战略行为和更强的对手意识。具体的性能提升幅度未知,但论文强调了该机制在复杂谈判场景下的有效性。
🎯 应用场景
该研究成果可应用于智能客服、商务谈判、供应链管理等领域。通过提升LLM的谈判能力,可以实现更高效、更公平的资源分配和利益协商。未来,该技术有望应用于人机协作的谈判场景,例如辅助人类进行复杂的商业谈判,或在自动化交易系统中实现更智能的议价策略。
📄 摘要(原文)
Bargaining is often regarded as a logical arena rather than an art or a matter of intuition, yet Large Language Models (LLMs) still struggle to navigate it due to limited strategic depth and difficulty adapting to complex human factors. Current benchmarks rarely capture this limitation. To bridge this gap, we present an utility feedback centric framework. Our contributions are: (i) AgoraBench, a new benchmark spanning nine challenging settings (e.g., deception, monopoly) that supports diverse strategy modeling; (ii) human-aligned, economically grounded metrics derived from utility theory. This is operationalized via agent utility, negotiation power, and acquisition ratio that implicitly measure how well the negotiation aligns with human preference and (iii) a human preference grounded dataset with learning pipeline that strengthens LLMs' bargaining ability through both prompting and finetuning. Empirical results indicate that baseline LLM strategies often diverge from human preferences, while our mechanism substantially improves negotiation performance, yielding deeper strategic behavior and stronger opponent awareness.