Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
作者: Zhaoyang Wang, Canwen Xu, Boyi Liu, Yite Wang, Siwei Han, Zhewei Yao, Huaxiu Yao, Yuxiong He
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-02-10
备注: 41 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出Agent World Model,用于大规模智能体强化学习的无限合成环境
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 智能体 强化学习 合成环境 世界模型 工具使用
📋 核心要点
- 现有智能体训练受限于缺乏多样且可靠的环境,难以扩展到复杂任务。
- 提出Agent World Model (AWM),一个全合成环境生成流程,提供代码驱动、数据库支持的可靠环境。
- 实验表明,在AWM生成的合成环境中训练的智能体,具有更强的分布外泛化能力。
📝 摘要(中文)
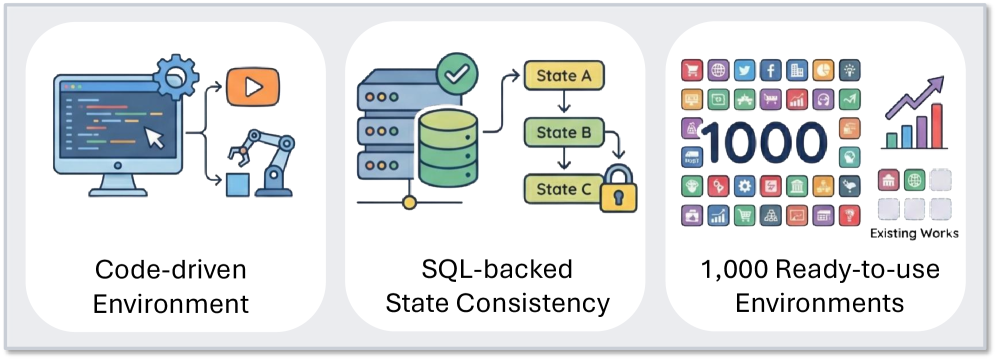
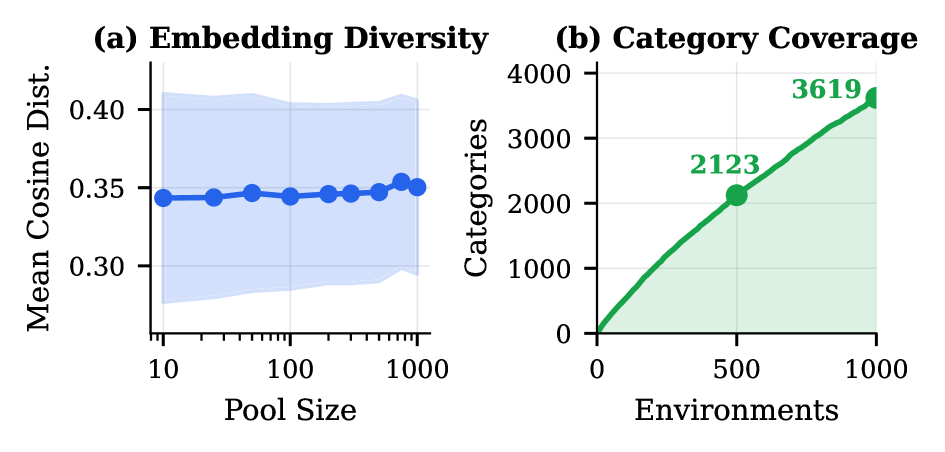
本文提出Agent World Model (AWM),一个完全合成的环境生成流程,旨在解决智能体训练中环境多样性和可靠性不足的问题。该流程能够生成覆盖日常场景的1000个环境,每个环境平均包含35个工具,智能体可以与这些工具进行交互并获得高质量的观测。这些环境由代码驱动并由数据库支持,与大型语言模型模拟的环境相比,提供了更可靠和一致的状态转换。此外,与从真实环境中收集轨迹相比,它们能够实现更高效的智能体交互。为了验证该资源的有效性,我们进行了大规模的智能体强化学习,用于多轮工具使用。由于完全可执行的环境和可访问的数据库状态,我们还可以设计可靠的奖励函数。在三个基准测试上的实验表明,仅在合成环境中训练,而非特定于基准测试的环境中训练,可以产生强大的分布外泛化能力。
🔬 方法详解
问题定义:现有智能体训练方法面临的主要问题是缺乏足够多样且可靠的环境。使用大型语言模型(LLM)模拟环境存在状态转换不一致和不可靠的问题,而从真实环境中收集轨迹则效率低下。这限制了智能体在复杂任务中的训练和泛化能力。
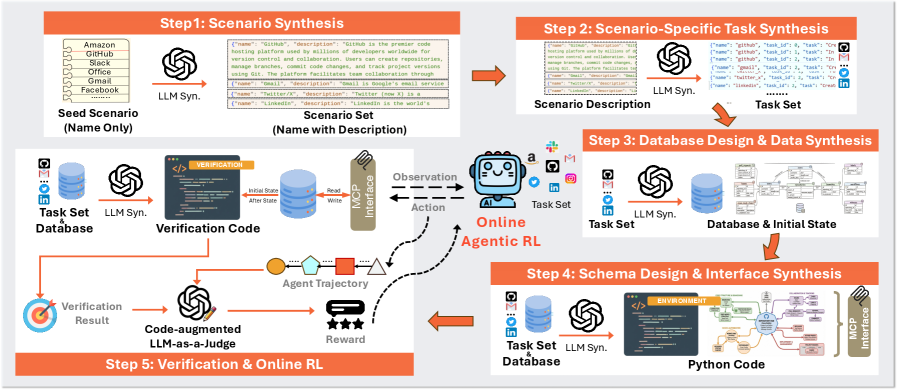
核心思路:本文的核心思路是构建一个完全合成的环境生成流程,即Agent World Model (AWM)。AWM通过代码驱动和数据库支持的方式生成环境,从而保证了环境状态转换的可靠性和一致性。同时,合成环境可以大规模生成,提供丰富的训练数据,并支持高效的智能体交互。
技术框架:AWM的技术框架主要包含以下几个阶段:1) 环境生成:使用代码和数据库生成多样化的环境,每个环境包含多个工具和可交互的对象。2) 智能体交互:智能体在合成环境中与工具进行交互,并获得观测。3) 奖励函数设计:基于可执行环境和可访问的数据库状态,设计可靠的奖励函数,引导智能体学习。4) 强化学习训练:使用强化学习算法在合成环境中训练智能体。
关键创新:AWM最重要的技术创新点在于其完全合成的环境生成方式。与传统的基于LLM的环境模拟方法相比,AWM通过代码驱动和数据库支持,保证了环境状态转换的可靠性和一致性。此外,AWM可以大规模生成环境,提供丰富的训练数据,并支持高效的智能体交互。
关键设计:AWM的关键设计包括:1) 环境的表示方式:使用代码和数据库来描述环境的状态和状态转换规则。2) 工具的定义:定义了多种工具,并为每个工具设计了相应的交互接口。3) 奖励函数的设计:基于环境的状态和智能体的行为,设计了可靠的奖励函数,引导智能体学习。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在AWM生成的合成环境中训练的智能体,在三个基准测试上表现出强大的分布外泛化能力。与在特定于基准测试的环境中训练的智能体相比,AWM训练的智能体在未见过的环境中表现更好,证明了其有效性。
🎯 应用场景
该研究成果可广泛应用于机器人、游戏AI、自动化工具使用等领域。通过在合成环境中进行训练,可以降低智能体训练的成本和风险,并提高智能体的泛化能力。未来,该技术有望推动智能体在现实世界中的应用。
📄 摘要(原文)
Recent advances in large language model (LLM) have empowered autonomous agents to perform complex tasks that require multi-turn interactions with tools and environments. However, scaling such agent training is limited by the lack of diverse and reliable environments. In this paper, we propose Agent World Model (AWM), a fully synthetic environment generation pipeline. Using this pipeline, we scale to 1,000 environments covering everyday scenarios, in which agents can interact with rich toolsets (35 tools per environment on average) and obtain high-quality observations. Notably, these environments are code-driven and backed by databases, providing more reliable and consistent state transitions than environments simulated by LLMs. Moreover, they enable more efficient agent interaction compared with collecting trajectories from realistic environments. To demonstrate the effectiveness of this resource, we perform large-scale reinforcement learning for multi-turn tool-use agents. Thanks to the fully executable environments and accessible database states, we can also design reliable reward functions. Experiments on three benchmarks show that training exclusively in synthetic environments, rather than benchmark-specific ones, yields strong out-of-distribution generalization. The code is available at https://github.com/Snowflake-Labs/agent-world-model.