Kunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
作者: Bojian Hou, Xiaolong Liu, Xiaoyi Liu, Jiaqi Xu, Yasmine Badr, Mengyue Hang, Sudhanshu Chanpuriya, Junqing Zhou, Yuhang Yang, Han Xu, Qiuling Suo, Laming Chen, Yuxi Hu, Jiasheng Zhang, Huaqing Xiong, Yuzhen Huang, Chao Chen, Yue Dong, Yi Yang, Shuo Chang, Xiaorui Gan, Wenlin Chen, Santanu Kolay, Darren Liu, Jade Nie, Chunzhi Yang, Jiyan Yang, Huayu Li
分类: cs.IR, cs.AI
发布日期: 2026-02-10
备注: 10 pages, 4 figures
💡 一句话要点
Kunlun:通过统一架构设计,为大规模推荐系统建立可预测的扩展法则。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 扩展法则 模型效率 资源分配 注意力机制
📋 核心要点
- 大规模推荐系统缺乏可预测的扩展法则,导致资源分配困难,现有方法在处理用户历史和上下文特征时效率低下。
- Kunlun架构通过优化模型效率和资源分配来解决扩展性问题,包括底层优化和高层创新,以提高模型FLOPs利用率。
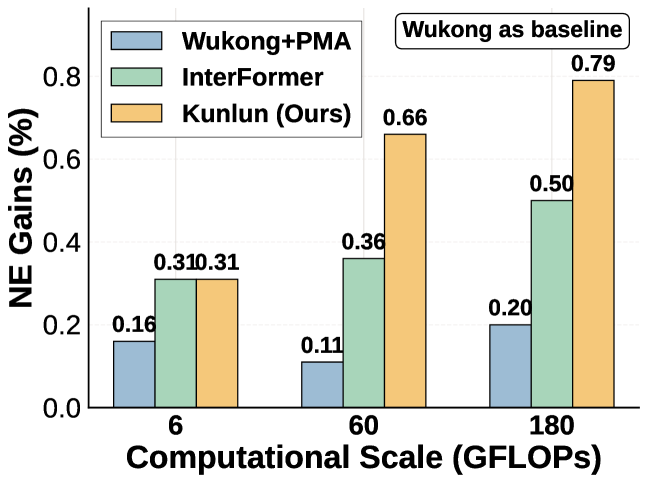
- Kunlun在NVIDIA B200 GPU上将MFU从17%提高到37%,扩展效率翻倍,并在Meta Ads模型中产生显著的生产影响。
📝 摘要(中文)
为大规模推荐系统设计和分配资源,需要推导出模型性能与计算投入之间可预测的扩展法则。虽然这种法则已在大语言模型中建立,但对于推荐系统,特别是那些处理用户历史和上下文特征的系统,仍然具有挑战性。我们发现扩展效率低下是可预测的幂律扩展的主要障碍,这源于模型FLOPs利用率(MFU)低的低效模块和次优的资源分配。我们提出了Kunlun,一种可扩展的架构,系统地提高了模型效率和资源分配。我们的底层优化包括广义点积注意力(GDPA)、分层种子池化(HSP)和滑动窗口注意力。我们的高层创新包括计算跳过(CompSkip)和事件级个性化。这些进步将NVIDIA B200 GPU上的MFU从17%提高到37%,并将扩展效率提高到超过最先进方法的两倍。Kunlun现已部署在主要的Meta Ads模型中,产生了显著的生产影响。
🔬 方法详解
问题定义:现有大规模推荐系统在扩展时面临效率瓶颈,难以建立模型性能与计算资源投入之间的可预测关系。特别是在处理用户历史和上下文特征时,现有模型的FLOPs利用率(MFU)较低,资源分配不合理,导致扩展效率低下,无法充分利用硬件资源。
核心思路:Kunlun的核心思路是通过统一的架构设计,系统性地提高模型效率和资源分配,从而建立可预测的扩展法则。通过底层优化提高模块效率,通过高层创新优化资源分配,最终提升整体的扩展性能。
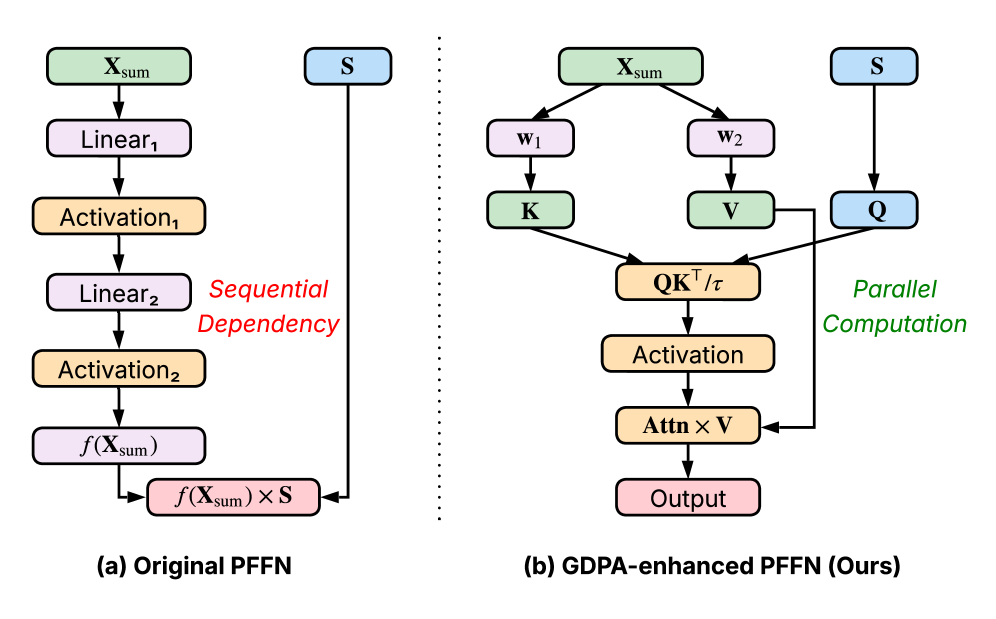
技术框架:Kunlun架构包含底层优化和高层创新两个主要部分。底层优化包括:1) 广义点积注意力(GDPA),用于更高效的注意力计算;2) 分层种子池化(HSP),用于减少序列长度;3) 滑动窗口注意力,用于处理长序列数据。高层创新包括:1) 计算跳过(CompSkip),用于动态地跳过不必要的计算;2) 事件级个性化,用于更好地捕捉用户行为的细粒度信息。
关键创新:Kunlun的关键创新在于其系统性的优化方法,既关注底层模块的效率提升,又关注高层架构的资源分配。通过GDPA、HSP和滑动窗口注意力等底层优化,提高了模型的计算效率。通过CompSkip和事件级个性化等高层创新,实现了更智能的资源分配和更精细的用户建模。与现有方法相比,Kunlun更加注重整体的扩展效率,而非仅仅关注单个模块的性能。
关键设计:GDPA通过优化注意力计算方式,减少了计算量。HSP通过分层池化,降低了序列长度,从而减少了计算复杂度。滑动窗口注意力通过限制注意力范围,提高了长序列处理效率。CompSkip基于一定的策略动态决定是否跳过某些计算,从而节省计算资源。事件级个性化通过更细粒度的用户行为建模,提高了推荐的准确性。具体的参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
Kunlun在NVIDIA B200 GPU上将模型FLOPs利用率(MFU)从17%提高到37%,显著提升了硬件利用率。与现有最先进的方法相比,Kunlun的扩展效率提高了一倍,表明其在处理大规模数据时具有更强的扩展能力。Kunlun已成功部署在Meta Ads模型中,并产生了显著的生产影响,验证了其在实际应用中的有效性。
🎯 应用场景
Kunlun架构可广泛应用于大规模推荐系统,尤其是在广告推荐、电商推荐等领域。通过提高模型效率和资源利用率,可以降低计算成本,提升推荐效果,从而带来更高的商业价值。未来,该架构有望推广到其他需要处理大规模数据和复杂模型的应用场景,例如自然语言处理、计算机视觉等。
📄 摘要(原文)
Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.