Efficient Unsupervised Environment Design through Hierarchical Policy Representation Learning
作者: Dexun Li, Sidney Tio, Pradeep Varakantham
分类: cs.AI
发布日期: 2026-02-10
💡 一句话要点
提出基于分层策略表示学习的高效无监督环境设计方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督环境设计 分层强化学习 策略表示学习 自动课程生成 生成模型
📋 核心要点
- 现有无监督环境设计方法依赖随机过程生成环境,在资源受限场景下效率低下。
- 论文提出分层MDP框架,教师智能体利用学生策略表示生成训练环境,提升效率。
- 实验表明,该方法优于基线,且在单episode中所需师生交互更少,适用于训练机会有限的场景。
📝 摘要(中文)
无监督环境设计(UED)已成为通过自动课程生成来开发通用智能体的一种有前景的方法。流行的UED方法侧重于开放性,其中教师算法依赖于随机过程来无限生成有用的环境。这种假设在资源受限的场景中变得不切实际,因为在这些场景中,师生交互的机会有限。为了解决这个问题,我们引入了一个用于环境设计的分层马尔可夫决策过程(MDP)框架。我们的框架的特点是,教师智能体利用从已发现的评估环境中获得的学生的策略表示,从而能够根据学生的能力生成训练环境。为了提高效率,我们结合了一个生成模型,该模型使用合成数据来扩充教师的训练数据集,从而减少了对师生交互的需求。在多个领域的实验中,我们表明我们的方法优于基线方法,同时在单个episode中需要更少的师生交互。结果表明了我们的方法在训练机会有限的环境中的适用性。
🔬 方法详解
问题定义:论文旨在解决资源受限场景下,无监督环境设计(UED)方法效率低下的问题。现有UED方法依赖随机过程生成环境,需要大量的师生交互,在计算资源或交互次数受限的情况下难以有效训练智能体。因此,如何高效地生成对学生智能体有益的训练环境是核心挑战。
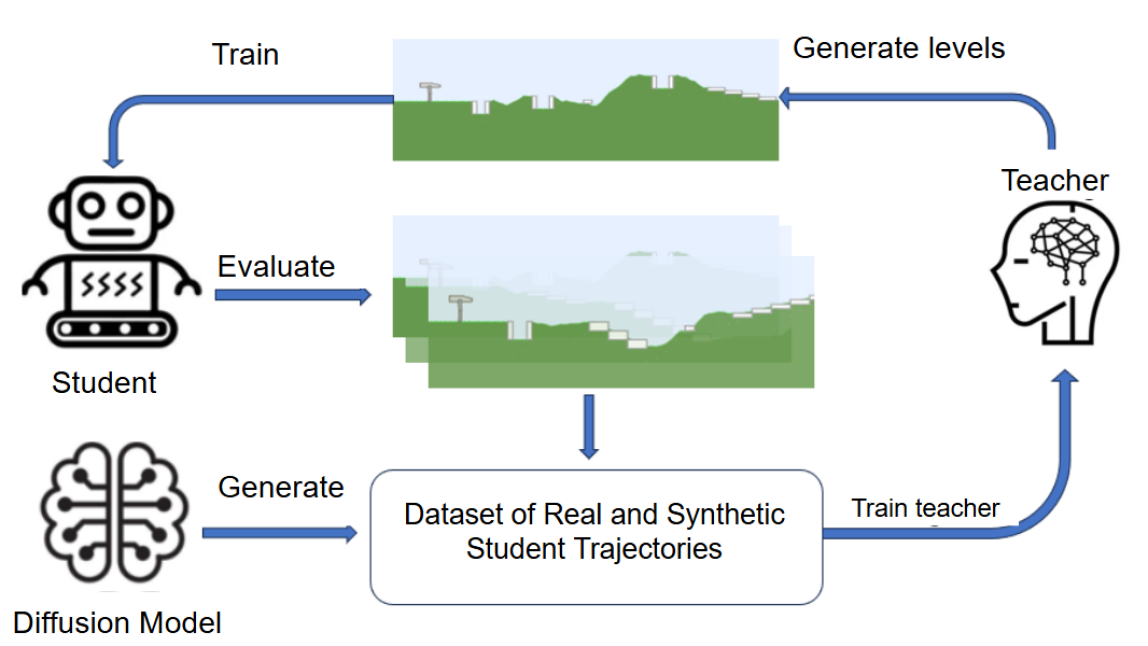
核心思路:论文的核心思路是利用学生智能体在已探索环境中的策略表示,指导教师智能体生成新的训练环境。通过分析学生智能体的能力,教师智能体可以更有针对性地设计环境,避免无效的探索,从而提高训练效率。此外,引入生成模型来扩充教师的训练数据,减少对真实师生交互的依赖。
技术框架:整体框架是一个分层MDP。上层是教师智能体,负责生成环境;下层是学生智能体,负责在环境中学习。教师智能体根据学生智能体在先前环境中的表现(策略表示)来选择新的环境参数。为了加速教师智能体的学习,使用生成模型生成合成数据,模拟师生交互的结果。整个流程迭代进行,不断优化环境设计和学生智能体的策略。
关键创新:论文的关键创新在于利用学生策略表示来指导环境设计。传统方法通常依赖随机或启发式方法,缺乏对学生智能体能力的感知。通过分析学生策略,教师智能体可以更有效地生成具有挑战性但又可学习的环境,实现更高效的课程学习。此外,生成模型的使用进一步减少了对真实交互的依赖,提高了算法的实用性。
关键设计:论文中,学生策略表示的具体形式(例如,策略参数、Q值等)需要根据具体任务进行选择。生成模型的设计也至关重要,需要能够准确模拟师生交互的结果。损失函数的设计需要平衡环境的难度和可学习性,避免生成过于简单或过于困难的环境。此外,教师智能体的探索策略也需要仔细设计,以保证环境的多样性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个领域优于基线方法,显著减少了师生交互次数。具体而言,在某些任务中,该方法能够在更少的episode内达到与基线方法相当甚至更高的性能。这表明该方法能够更有效地利用有限的训练资源,提高无监督环境设计的效率。
🎯 应用场景
该研究成果可应用于机器人自主探索、游戏AI训练、强化学习算法的自动化调参等领域。通过自动生成合适的训练环境,可以降低人工干预成本,加速智能体的学习过程,并提升智能体的泛化能力。未来,该方法有望应用于更复杂的现实世界场景,例如自动驾驶、智能制造等。
📄 摘要(原文)
Unsupervised Environment Design (UED) has emerged as a promising approach to developing general-purpose agents through automated curriculum generation. Popular UED methods focus on Open-Endedness, where teacher algorithms rely on stochastic processes for infinite generation of useful environments. This assumption becomes impractical in resource-constrained scenarios where teacher-student interaction opportunities are limited. To address this challenge, we introduce a hierarchical Markov Decision Process (MDP) framework for environment design. Our framework features a teacher agent that leverages student policy representations derived from discovered evaluation environments, enabling it to generate training environments based on the student's capabilities. To improve efficiency, we incorporate a generative model that augments the teacher's training dataset with synthetic data, reducing the need for teacher-student interactions. In experiments across several domains, we show that our method outperforms baseline approaches while requiring fewer teacher-student interactions in a single episode. The results suggest the applicability of our approach in settings where training opportunities are limited.