Autoregressive Direct Preference Optimization
作者: Masanari Oi, Mahiro Ukai, Masahiro Kaneko, Naoaki Okazaki, Nakamasa Inoue
分类: cs.AI
发布日期: 2026-02-10
💡 一句话要点
提出自回归直接偏好优化(ADPO),提升大语言模型对齐人类偏好的效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接偏好优化 自回归模型 大型语言模型 人类偏好对齐 Bradley-Terry模型
📋 核心要点
- 现有DPO方法在对齐LLM时,仅在目标函数推导后才考虑自回归特性,可能限制了其优化潜力。
- ADPO通过在应用BT模型前显式引入自回归假设,重新构建DPO,更有效地利用了LLM的自回归特性。
- 理论分析表明,ADPO需要考虑token长度和反馈长度两种度量,为DPO算法设计提供了新视角。
📝 摘要(中文)
直接偏好优化(DPO)已成为一种有前景的将大型语言模型(LLM)与人类偏好对齐的方法。然而,广泛依赖于响应级别的Bradley-Terry (BT)模型可能会限制其全部潜力,因为参考模型和可学习模型仅在推导目标函数后才被假定为自回归模型。受此限制的推动,我们重新审视了DPO的理论基础,并提出了一种新的公式,该公式在应用BT模型之前显式地引入了自回归假设。通过重新制定和扩展DPO,我们推导出一种新的变体,称为自回归DPO (ADPO),它将自回归建模显式地集成到偏好优化框架中。在不违反理论基础的前提下,导出的损失函数采用了一种优雅的形式:它将DPO目标中的求和运算移到log-sigmoid函数之外。此外,通过对ADPO的理论分析,我们表明在设计基于DPO的算法时,需要考虑两种长度度量:token长度μ和反馈长度μ'。据我们所知,我们是第一个明确区分这两种度量并分析它们对LLM中偏好优化的影响的人。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法在将大型语言模型(LLM)与人类偏好对齐时,虽然取得了显著进展,但其理论基础存在局限性。DPO通常依赖于响应级别的Bradley-Terry (BT)模型,该模型仅在推导出目标函数之后才将参考模型和可学习模型视为自回归模型。这种延迟考虑自回归特性的方式可能无法充分利用LLM的内在优势,从而限制了DPO的优化效率和最终性能。
核心思路:ADPO的核心思路是在应用Bradley-Terry (BT)模型之前,就显式地将自回归假设融入到偏好优化框架中。通过提前考虑自回归特性,ADPO能够更准确地建模LLM的生成过程,并更有效地利用LLM的内在优势。这种方法旨在克服传统DPO方法的局限性,从而提高LLM与人类偏好对齐的效率和质量。
技术框架:ADPO通过重新审视DPO的理论基础,并提出一种新的公式来实现其核心思路。该公式在应用BT模型之前显式地引入了自回归假设。具体而言,ADPO通过重新制定和扩展DPO,推导出一种新的变体,称为自回归DPO (ADPO)。ADPO的关键在于将DPO目标中的求和运算移到log-sigmoid函数之外,从而在损失函数层面体现自回归特性。
关键创新:ADPO最重要的技术创新点在于它显式地将自回归建模集成到偏好优化框架中。与传统的DPO方法不同,ADPO在应用BT模型之前就考虑了LLM的自回归特性。这种提前考虑自回归特性的方式能够更准确地建模LLM的生成过程,并更有效地利用LLM的内在优势。此外,ADPO还明确区分了token长度和反馈长度两种度量,并分析了它们对LLM中偏好优化的影响。
关键设计:ADPO的关键设计在于其损失函数的形式。通过将DPO目标中的求和运算移到log-sigmoid函数之外,ADPO的损失函数能够更有效地利用LLM的自回归特性。此外,ADPO还引入了token长度μ和反馈长度μ'两种度量,用于指导DPO算法的设计。这些度量可以帮助研究人员更好地理解LLM的生成过程,并设计出更有效的偏好优化算法。
🖼️ 关键图片

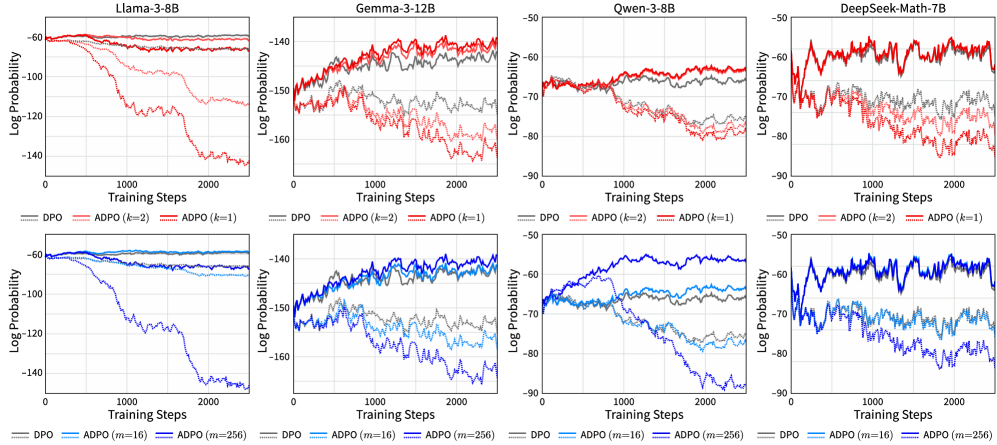
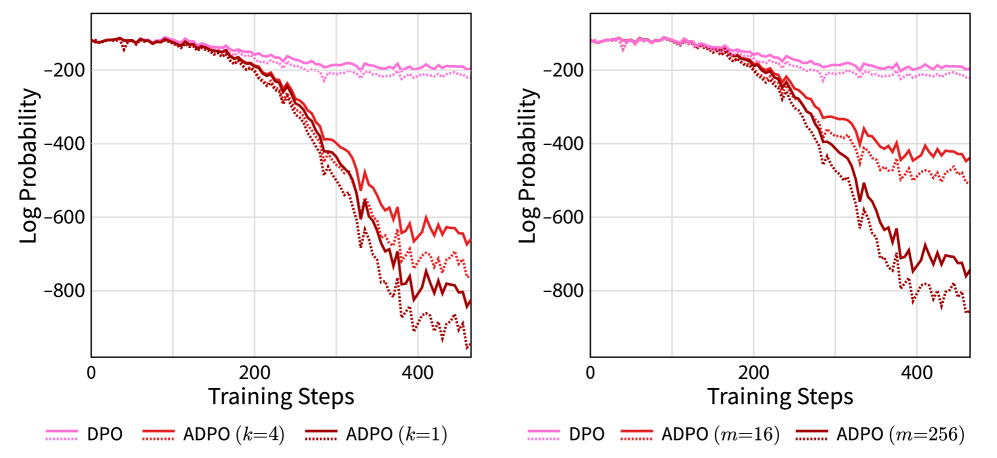
📊 实验亮点
论文通过理论分析和实验验证了ADPO的有效性。虽然摘要中没有明确给出具体的性能数据和提升幅度,但强调了ADPO在理论上的创新性和对DPO算法设计的指导意义,暗示了ADPO在实际应用中具有潜在的性能提升。
🎯 应用场景
ADPO可应用于各种需要将大型语言模型与人类偏好对齐的场景,例如对话系统、文本生成、代码生成等。通过提高对齐效率和质量,ADPO有助于开发更安全、更可靠、更符合人类价值观的LLM应用,提升用户体验。
📄 摘要(原文)
Direct preference optimization (DPO) has emerged as a promising approach for aligning large language models (LLMs) with human preferences. However, the widespread reliance on the response-level Bradley-Terry (BT) model may limit its full potential, as the reference and learnable models are assumed to be autoregressive only after deriving the objective function. Motivated by this limitation, we revisit the theoretical foundations of DPO and propose a novel formulation that explicitly introduces the autoregressive assumption prior to applying the BT model. By reformulating and extending DPO, we derive a novel variant, termed Autoregressive DPO (ADPO), that explicitly integrates autoregressive modeling into the preference optimization framework. Without violating the theoretical foundations, the derived loss takes an elegant form: it shifts the summation operation in the DPO objective outside the log-sigmoid function. Furthermore, through theoretical analysis of ADPO, we show that there exist two length measures to be considered when designing DPO-based algorithms: the token length $μ$ and the feedback length $μ$'. To the best of our knowledge, we are the first to explicitly distinguish these two measures and analyze their implications for preference optimization in LLMs.