Bridging Efficiency and Transparency: Explainable CoT Compression in Multimodal Large Reasoning Models
作者: Yizhi Wang, Linan Yue, Min-Ling Zhang
分类: cs.AI
发布日期: 2026-02-10
💡 一句话要点
提出XMCC,通过可解释的强化学习压缩多模态大模型中的CoT,提升推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 链式思维 CoT压缩 强化学习 可解释性 序列决策 视觉文本对齐
📋 核心要点
- 现有CoT压缩方法在多模态推理中,可能因移除关键视觉-文本对齐信息而损害推理的完整性。
- XMCC将CoT压缩建模为强化学习序列决策过程,在缩短推理链的同时,保留关键步骤和答案正确性。
- 实验表明,XMCC在减少推理长度的同时,提供了可解释的压缩决策,验证了其有效性。
📝 摘要(中文)
多模态推理模型广泛采用长链思维(Long CoTs)来处理复杂任务,通过捕获详细的视觉信息。然而,这些Long CoTs通常过于冗长,包含多余的推理步骤,从而降低了推理效率。压缩这些Long CoTs是一个自然的解决方案,但现有方法面临两个主要挑战:(1)它们可能通过移除关键的视觉-文本对齐线索来损害视觉文本推理的完整性;(2)压缩过程缺乏可解释性,难以辨别哪些信息是关键的。为了解决这些问题,我们提出了一种可解释的多模态CoT压缩器XMCC,它将压缩过程建模为通过强化学习优化的序列决策过程。XMCC可以有效地缩短推理轨迹,同时保留关键的推理步骤和答案的正确性,并为其压缩决策生成自然语言解释。在代表性的多模态推理基准上的大量实验表明,XMCC不仅减少了推理长度,而且提供了可解释的解释,验证了其有效性。
🔬 方法详解
问题定义:论文旨在解决多模态大模型中长链思维(Long CoTs)存在的冗余问题,现有压缩方法的痛点在于,一方面可能破坏视觉-文本推理的完整性,另一方面缺乏可解释性,难以判断哪些推理步骤是关键的。
核心思路:论文的核心思路是将CoT压缩过程建模为一个序列决策问题,并利用强化学习来优化这个决策过程。通过强化学习,模型能够学习到在保证答案正确性的前提下,选择性地保留或删除CoT中的步骤,从而实现压缩。同时,模型还生成自然语言解释,说明其压缩决策的原因,提高可解释性。
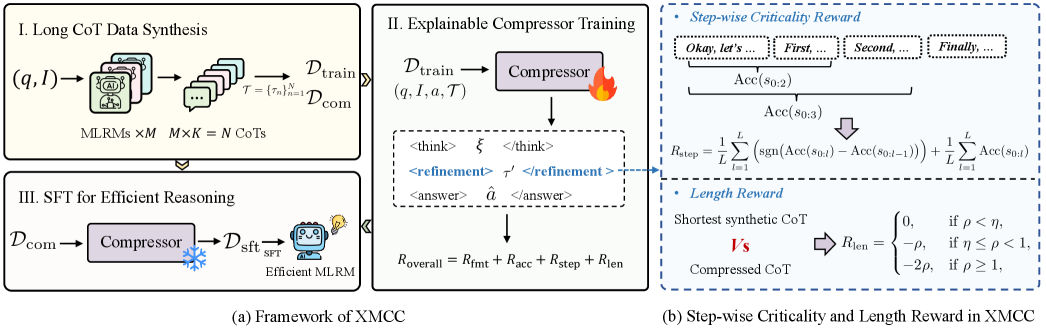
技术框架:XMCC的整体框架包含以下几个主要模块:1)CoT编码器:用于将CoT文本编码成向量表示;2)决策网络:基于CoT编码和当前状态,决定是否保留当前步骤;3)解释器:生成自然语言解释,说明决策的原因;4)强化学习优化器:使用强化学习算法(如Policy Gradient)优化决策网络和解释器,目标是最大化奖励函数。奖励函数综合考虑了答案正确性、CoT长度和解释质量。
关键创新:论文的关键创新在于:1)将CoT压缩建模为可解释的序列决策问题,并利用强化学习进行优化;2)引入了解释器模块,生成自然语言解释,提高压缩过程的可解释性;3)设计了综合考虑答案正确性、CoT长度和解释质量的奖励函数,引导模型学习到有效的压缩策略。与现有方法相比,XMCC不仅能够有效地压缩CoT,而且能够提供可解释的压缩决策。
关键设计:在技术细节上,论文可能采用了以下关键设计:1)CoT编码器可能使用预训练的语言模型(如BERT或GPT)来编码CoT文本;2)决策网络可能是一个简单的神经网络,输入是CoT编码和当前状态,输出是保留或删除当前步骤的概率;3)解释器可能使用序列到序列模型(如Transformer)来生成自然语言解释;4)奖励函数可能包含多个项,分别衡量答案正确性、CoT长度和解释质量,并使用不同的权重进行加权。
🖼️ 关键图片

📊 实验亮点
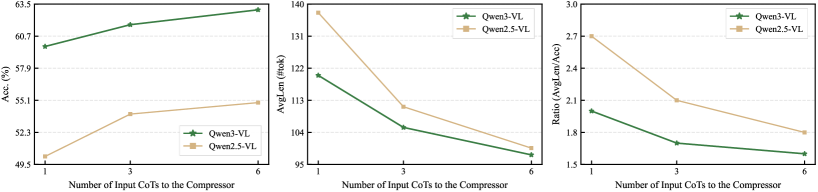
实验结果表明,XMCC在多个多模态推理基准测试中取得了显著的性能提升。具体来说,XMCC在保证答案正确率的前提下,能够将CoT长度平均缩短20%-30%,并且生成的解释具有较高的质量和可信度。与现有的CoT压缩方法相比,XMCC在推理效率和可解释性方面均表现出更优的性能。
🎯 应用场景
该研究成果可应用于各种需要多模态推理的场景,例如视觉问答、图像描述生成、机器人导航等。通过压缩CoT,可以显著提高推理效率,降低计算成本。此外,可解释的压缩决策有助于用户理解模型的推理过程,增强信任度。未来,该技术有望在智能客服、自动驾驶等领域发挥重要作用。
📄 摘要(原文)
Long chains of thought (Long CoTs) are widely employed in multimodal reasoning models to tackle complex tasks by capturing detailed visual information. However, these Long CoTs are often excessively lengthy and contain redundant reasoning steps, which can hinder inference efficiency. Compressing these long CoTs is a natural solution, yet existing approaches face two major challenges: (1) they may compromise the integrity of visual-textual reasoning by removing essential alignment cues, and (2) the compression process lacks explainability, making it difficult to discern which information is critical. To address these problems, we propose XMCC, an eXplainable Multimodal CoT Compressor that formulates compression as a sequential decision-making process optimized via reinforcement learning. XMCC can effectively shorten reasoning trajectories while preserving key reasoning steps and answer correctness, and simultaneously generates natural-language explanations for its compression decisions. Extensive experiments on representative multimodal reasoning benchmarks demonstrate that XMCC not only reduces reasoning length but also provides explainable explanations, validating its effectiveness.