SWE-AGI: Benchmarking Specification-Driven Software Construction with MoonBit in the Era of Autonomous Agents
作者: Zhirui Zhang, Hongbo Zhang, Haoxiang Fei, Zhiyuan Bao, Yubin Chen, Zhengyu Lei, Ziyue Liu, Yixuan Sun, Mingkun Xiao, Zihang Ye, Yu Zhang, Hongcheng Zhu, Yuxiang Wen, Heung-Yeung Shum
分类: cs.SE, cs.AI, cs.CL
发布日期: 2026-02-10
备注: 20 pages, 3 figures
💡 一句话要点
SWE-AGI:利用MoonBit评估自主Agent在规范驱动下构建软件的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主Agent 软件构建 规范驱动 大型语言模型 MoonBit 基准测试 代码阅读 软件工程
📋 核心要点
- 现有大型语言模型在自主构建生产级软件方面能力不足,缺乏系统性的评估基准。
- SWE-AGI基准测试通过MoonBit语言,要求Agent根据规范实现复杂软件,侧重架构推理而非代码检索。
- 实验表明,GPT-5.3-codex在SWE-AGI上表现最佳,但随着任务难度增加,性能显著下降,代码阅读成为瓶颈。
📝 摘要(中文)
尽管大型语言模型(LLMs)展现了令人印象深刻的编码能力,但它们在明确规范驱动下自主构建生产规模软件的能力仍然是一个悬而未决的问题。我们推出了SWE-AGI,这是一个开源基准,用于评估用MoonBit编写的软件系统的端到端、规范驱动的构建。SWE-AGI任务要求基于LLM的Agent严格根据权威标准和RFC,在固定的API框架下实现解析器、解释器、二进制解码器和SAT求解器。每个任务涉及实现1,000-10,000行核心逻辑,相当于经验丰富的开发人员数周或数月的工程工作量。通过利用新兴的MoonBit生态系统,SWE-AGI最大限度地减少了数据泄露,迫使Agent依赖于长期的架构推理,而不是代码检索。在最先进的模型中,gpt-5.3-codex表现最佳(解决了22个任务中的19个,86.4%),优于claude-opus-4.6(15/22,68.2%),而kimi-2.5在开源模型中表现最强。随着任务难度的增加,性能急剧下降,尤其是在需要大量规范的复杂系统上。行为分析进一步表明,随着代码库规模的扩大,代码阅读而非编写成为AI辅助开发的主要瓶颈。总的来说,虽然规范驱动的自主软件工程越来越可行,但在它能够可靠地支持生产规模的开发之前,仍然存在巨大的挑战。
🔬 方法详解
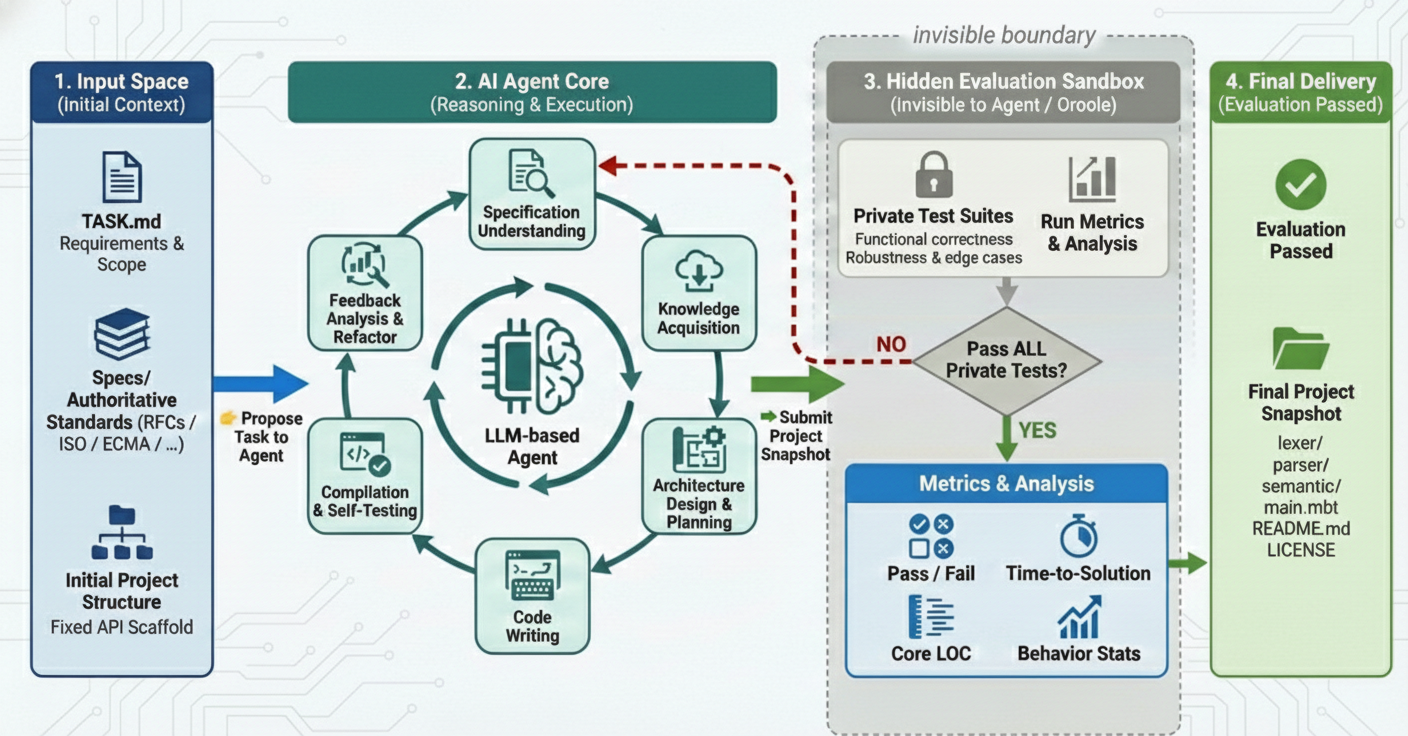
问题定义:论文旨在评估大型语言模型(LLMs)在规范驱动下自主构建生产规模软件的能力。现有方法依赖于代码检索,容易出现数据泄露,并且缺乏对长期架构推理能力的考察。此外,缺乏一个专门针对端到端软件构建的基准测试。
核心思路:论文的核心思路是创建一个新的基准测试SWE-AGI,该基准测试使用MoonBit语言,并要求LLM Agent严格按照规范构建软件系统。通过使用MoonBit,可以最大限度地减少数据泄露,并迫使Agent依赖于长期的架构推理。这样设计的目的是更真实地反映实际软件开发中遇到的挑战。
技术框架:SWE-AGI基准测试包含一系列任务,每个任务都要求Agent实现一个特定的软件组件,例如解析器、解释器、二进制解码器或SAT求解器。Agent需要根据权威标准和RFC,在给定的API框架下编写代码。评估过程是端到端的,即Agent需要从头开始构建整个软件组件。基准测试还包括用于评估Agent性能的指标,例如代码的正确性和效率。
关键创新:SWE-AGI的关键创新在于它使用MoonBit语言,并侧重于规范驱动的软件构建。与传统的代码检索方法相比,这种方法更具挑战性,并且更真实地反映了实际软件开发中遇到的挑战。此外,SWE-AGI是一个端到端的基准测试,可以评估Agent在整个软件构建过程中的性能。
关键设计:SWE-AGI任务的设计考虑了难度和多样性。任务的难度范围从简单到复杂,并且涵盖了各种不同的软件组件。每个任务都包含一个详细的规范,描述了Agent需要实现的功能。此外,SWE-AGI还提供了一个API框架,Agent可以使用该框架来构建软件组件。评估指标包括代码的正确性、效率和可读性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-5.3-codex在SWE-AGI基准测试中取得了最佳性能,解决了22个任务中的19个(86.4%),优于Claude-opus-4.6(68.2%)。开源模型Kimi-2.5表现也相对较好。然而,随着任务难度的增加,所有模型的性能都显著下降,尤其是在需要大量规范的复杂系统上。行为分析表明,代码阅读而非编写成为AI辅助开发的主要瓶颈。
🎯 应用场景
该研究成果可应用于评估和提升AI在软件开发领域的自主能力,推动自动化软件工程的发展。通过SWE-AGI基准,可以更有效地训练和评估LLM Agent,使其能够更好地理解和执行软件规范,从而提高软件开发的效率和质量。未来,该研究有望促进AI在复杂软件系统构建中的应用。
📄 摘要(原文)
Although large language models (LLMs) have demonstrated impressive coding capabilities, their ability to autonomously build production-scale software from explicit specifications remains an open question. We introduce SWE-AGI, an open-source benchmark for evaluating end-to-end, specification-driven construction of software systems written in MoonBit. SWE-AGI tasks require LLM-based agents to implement parsers, interpreters, binary decoders, and SAT solvers strictly from authoritative standards and RFCs under a fixed API scaffold. Each task involves implementing 1,000-10,000 lines of core logic, corresponding to weeks or months of engineering effort for an experienced human developer. By leveraging the nascent MoonBit ecosystem, SWE-AGI minimizes data leakage, forcing agents to rely on long-horizon architectural reasoning rather than code retrieval. Across frontier models, gpt-5.3-codex achieves the best overall performance (solving 19/22 tasks, 86.4%), outperforming claude-opus-4.6 (15/22, 68.2%), and kimi-2.5 exhibits the strongest performance among open-source models. Performance degrades sharply with increasing task difficulty, particularly on hard, specification-intensive systems. Behavioral analysis further reveals that as codebases scale, code reading, rather than writing, becomes the dominant bottleneck in AI-assisted development. Overall, while specification-driven autonomous software engineering is increasingly viable, substantial challenges remain before it can reliably support production-scale development.