P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
作者: Yun Luo, Futing Wang, Qianjia Cheng, Fangchen Yu, Haodi Lei, Jianhao Yan, Chenxi Li, Jiacheng Chen, Yufeng Zhao, Haiyuan Wan, Yuchen Zhang, Shenghe Zheng, Junchi Yao, Qingyang Zhang, Haonan He, Wenxuan Zeng, Li Sheng, Chengxing Xie, Yuxin Zuo, Yizhuo Li, Yulun Wu, Rui Huang, Dongzhan Zhou, Kai Chen, Yu Qiao, Lei Bai, Yu Cheng, Ning Ding, Bowen Zhou, Peng Ye, Ganqu Cui
分类: cs.AI
发布日期: 2026-02-10
💡 一句话要点
提出P1-VL视觉语言模型,解决物理奥赛中视觉感知与科学推理的桥梁问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 物理奥赛 科学推理 课程强化学习 Agentic Augmentation 多模态学习 物理智能
📋 核心要点
- 现有大语言模型在科学推理方面面临挑战,尤其是在需要结合视觉信息进行物理学推理时。
- P1-VL通过课程强化学习和Agentic Augmentation,提升模型在物理问题上的推理能力和准确性。
- P1-VL在HiPhO基准测试中取得优异成绩,超越现有开源模型,并在STEM领域展现出良好的泛化能力。
📝 摘要(中文)
本文提出了P1-VL系列开源视觉语言模型,旨在弥合符号操作与科学级推理之间的差距,尤其是在物理学领域。物理学要求模型与宇宙法则保持一致,这需要多模态感知将抽象逻辑与现实联系起来。针对物理奥赛中图表包含重要约束(如边界条件和空间对称性)的问题,P1-VL结合了课程强化学习(通过难度递增稳定训练后过程)和Agentic Augmentation(在推理时进行迭代自验证)。在HiPhO基准测试中,P1-VL-235B-A22B模型获得了12枚金牌,并在开源模型中取得了最优性能。该模型在全球排名第二,仅次于Gemini-3-Pro。P1-VL在STEM基准测试中也表现出卓越的科学推理能力和泛化性。通过开源P1-VL,为通用物理智能奠定了基础,以更好地将视觉感知与抽象物理定律对齐,从而促进机器科学发现。
🔬 方法详解
问题定义:论文旨在解决物理奥赛题目中,视觉信息(如图表)对于理解和解决问题至关重要,而现有的大语言模型难以有效利用这些视觉信息进行科学推理的问题。现有方法主要依赖符号操作,缺乏将抽象逻辑与物理现实联系起来的能力,无法处理图表中隐含的边界条件和空间对称性等约束。
核心思路:论文的核心思路是构建一个能够有效融合视觉信息和语言信息的视觉语言模型(VLM),并通过课程强化学习和Agentic Augmentation来提升模型的推理能力。通过课程强化学习,模型可以逐步学习解决更复杂的物理问题,而Agentic Augmentation则允许模型在推理过程中进行自我验证,从而提高答案的准确性。
技术框架:P1-VL的技术框架主要包含以下几个部分:1) 一个视觉编码器,用于提取图表中的视觉特征;2) 一个语言模型,用于处理题目文本和生成答案;3) 一个多模态融合模块,用于将视觉特征和语言信息融合在一起;4) 课程强化学习模块,用于逐步提升模型的学习难度;5) Agentic Augmentation模块,用于在推理过程中进行自我验证。整体流程是,首先使用视觉编码器和语言模型分别提取视觉特征和语言信息,然后使用多模态融合模块将它们融合在一起,接着使用课程强化学习模块训练模型,最后使用Agentic Augmentation模块进行推理。
关键创新:论文的关键创新点在于:1) 提出了P1-VL,一个专门为解决物理奥赛问题而设计的视觉语言模型;2) 结合了课程强化学习和Agentic Augmentation,有效地提升了模型的推理能力和准确性;3) 在HiPhO基准测试中取得了优异的成绩,证明了P1-VL的有效性。与现有方法相比,P1-VL能够更好地利用视觉信息进行科学推理,并且具有更强的泛化能力。
关键设计:关于课程强化学习,采用了难度递增的方式,逐步增加训练样本的难度,以稳定训练过程。Agentic Augmentation的具体实现未知,但其核心思想是在推理过程中,模型可以进行多次自我验证,从而提高答案的准确性。模型的具体网络结构和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
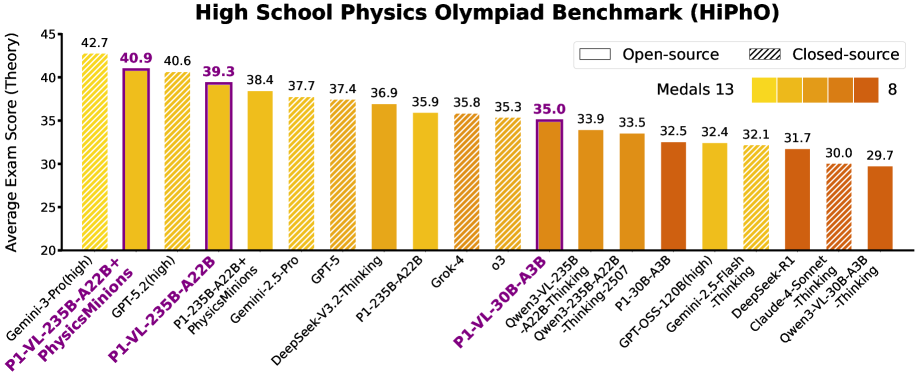

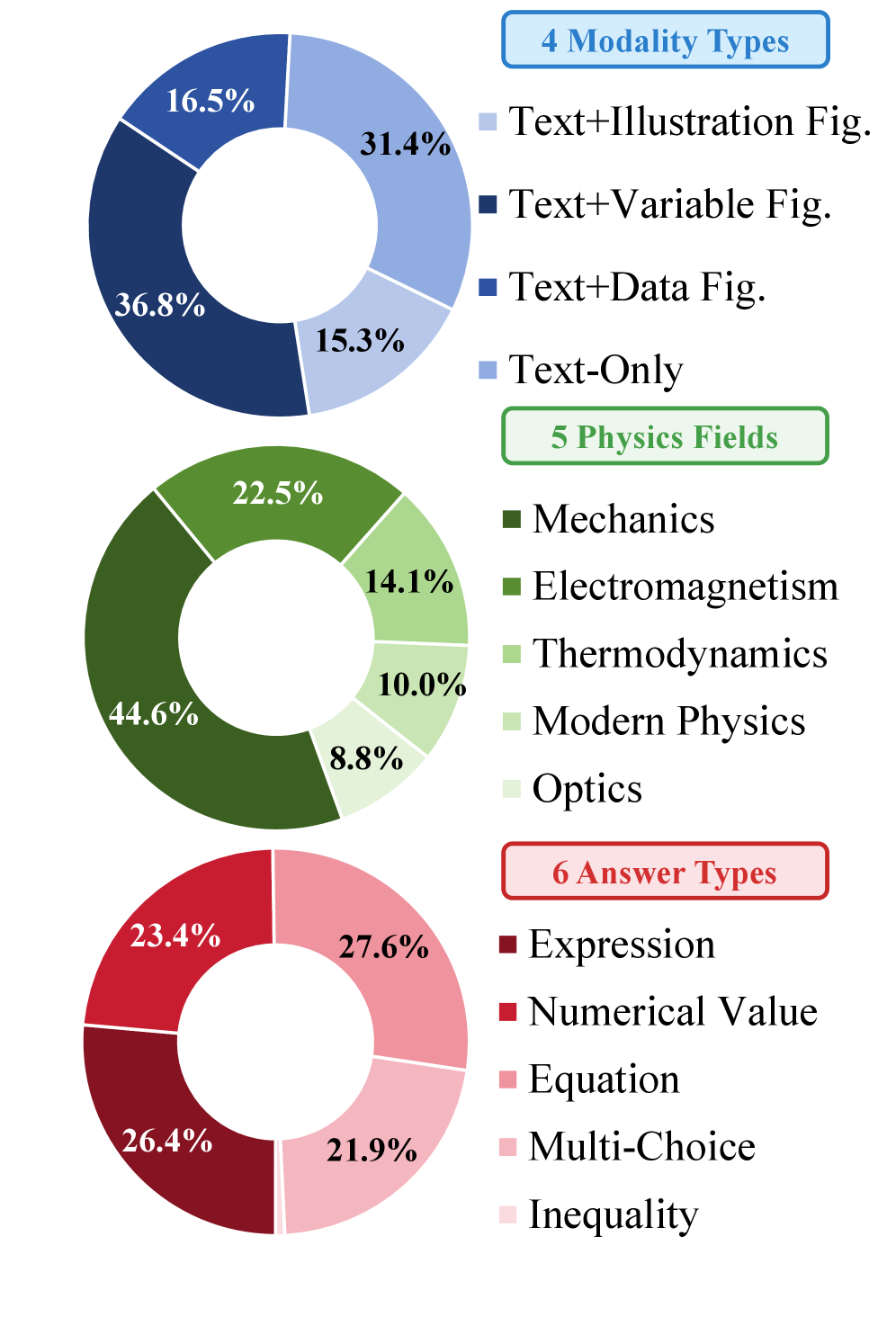
📊 实验亮点
P1-VL-235B-A22B在HiPhO基准测试中获得了12枚金牌,成为首个在该基准上取得如此成就的开源视觉语言模型。在开源模型中取得了state-of-the-art的性能。经过Agentic Augmentation增强的系统在全球排名第二,仅次于Gemini-3-Pro。此外,P1-VL在STEM基准测试中也表现出卓越的科学推理能力和泛化性,显著优于基线模型。
🎯 应用场景
P1-VL的应用场景广泛,包括但不限于:物理学教育、自动化科学发现、机器人感知与控制、以及需要结合视觉信息进行复杂推理的领域。该研究的实际价值在于提供了一个强大的工具,可以帮助人们更好地理解和解决物理问题,并促进机器科学发现。未来,P1-VL有望应用于更广泛的科学领域,并推动人工智能技术的发展。
📄 摘要(原文)
The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.