A Behavioral Fingerprint for Large Language Models: Provenance Tracking via Refusal Vectors
作者: Zhenyu Xu, Victor S. Sheng
分类: cs.CR, cs.AI
发布日期: 2026-02-10
💡 一句话要点
提出基于拒绝向量的行为指纹方法,用于追踪大型语言模型的知识产权。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识产权保护 行为指纹 拒绝向量 模型溯源
📋 核心要点
- 现有LLM知识产权保护方法不足,难以有效应对模型微调、合并等攻击,溯源能力弱。
- 利用LLM安全对齐产生的行为模式,提取拒绝向量作为模型指纹,实现模型家族的精准溯源。
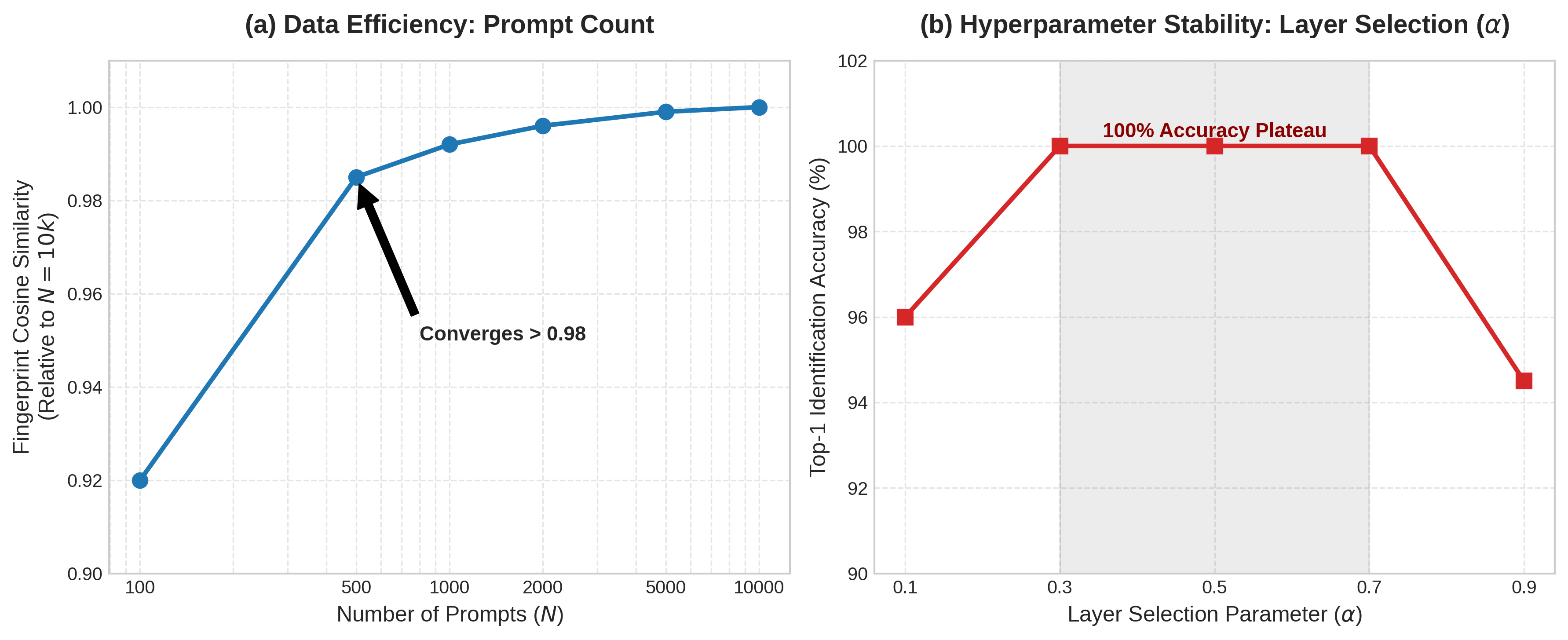
- 实验证明该指纹对多种攻击具有鲁棒性,并在大规模识别任务中达到100%准确率,为LLM知识产权保护提供有效方案。
📝 摘要(中文)
由于未经授权的衍生模型大量涌现,保护大型语言模型(LLM)的知识产权是一项关键挑战。本文提出了一种新颖的指纹识别框架,该框架利用安全对齐所引发的行为模式,应用拒绝向量的概念进行LLM溯源追踪。这些向量从模型处理有害与无害提示时的内部表征的方向模式中提取,作为鲁棒的行为指纹。本文的贡献在于围绕这一概念开发了一个指纹识别系统,并对它在知识产权保护方面的有效性进行了广泛验证。实验表明,这些行为指纹对于常见的修改(包括微调、合并和量化)具有高度的鲁棒性。不同独立训练的模型家族之间的余弦相似度较低,表明指纹对于每个模型家族都是唯一的。在一个包含76个衍生模型的大规模识别任务中,该方法在识别正确的基模型家族方面实现了100%的准确率。此外,本文还分析了指纹在对抗对齐破坏攻击下的行为,发现虽然性能显著下降,但仍然存在可检测的痕迹。最后,本文提出了一个理论框架,利用局部敏感哈希和零知识证明,将这种私有指纹转换为公开可验证且保护隐私的工件。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)知识产权保护的问题。现有方法难以有效追踪和识别未经授权的衍生模型,尤其是在模型经过微调、合并或量化等修改后,溯源变得更加困难。现有的水印方法容易被移除,且无法抵抗模型修改。
核心思路:论文的核心思路是利用LLM在安全对齐过程中产生的独特行为模式,即模型在处理有害和无害提示时,其内部表征会呈现出不同的方向性。通过提取这些方向性差异,形成拒绝向量,作为模型的行为指纹。这种指纹具有鲁棒性,能够抵抗常见的模型修改。
技术框架:该指纹识别框架主要包含以下几个阶段:1) 提示生成:构建包含有害和无害提示的提示集。2) 向量提取:将提示输入目标LLM,提取模型内部表征,计算有害和无害提示之间的向量差异,得到拒绝向量。3) 指纹存储:将拒绝向量作为模型的指纹进行存储。4) 模型识别:对于待识别的模型,重复上述步骤提取其指纹,然后与已知模型指纹进行比较,通过计算余弦相似度等指标,判断其所属的模型家族。
关键创新:该方法最重要的技术创新点在于利用了LLM安全对齐过程中的行为模式,将拒绝向量作为模型的指纹。与传统的水印方法不同,这种行为指纹并非显式地嵌入到模型参数中,而是隐含在模型的行为中,因此更难被移除,且对模型修改具有更强的鲁棒性。此外,论文还提出了将私有指纹转换为公开可验证的隐私保护工件的理论框架。
关键设计:在提示生成方面,需要精心设计有害和无害提示,以确保能够有效激发模型内部表征的差异。在向量提取方面,需要选择合适的模型层和激活函数,以获得最具代表性的内部表征。在相似度计算方面,可以使用余弦相似度等指标来衡量指纹之间的相似程度。论文还探讨了使用局部敏感哈希和零知识证明来实现隐私保护的指纹验证。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法提取的行为指纹对微调、合并和量化等常见模型修改具有高度的鲁棒性。在包含76个衍生模型的大规模识别任务中,该方法能够以100%的准确率识别出正确的基模型家族。即使在对抗对齐破坏攻击下,该指纹仍然能够保留可检测的痕迹。
🎯 应用场景
该研究成果可应用于大型语言模型的知识产权保护,帮助模型开发者追踪和识别未经授权的衍生模型,维护自身权益。此外,该方法还可以用于评估模型的安全性,检测模型是否存在对齐问题。未来,该技术有望应用于更广泛的AI模型版权保护领域。
📄 摘要(原文)
Protecting the intellectual property of large language models (LLMs) is a critical challenge due to the proliferation of unauthorized derivative models. We introduce a novel fingerprinting framework that leverages the behavioral patterns induced by safety alignment, applying the concept of refusal vectors for LLM provenance tracking. These vectors, extracted from directional patterns in a model's internal representations when processing harmful versus harmless prompts, serve as robust behavioral fingerprints. Our contribution lies in developing a fingerprinting system around this concept and conducting extensive validation of its effectiveness for IP protection. We demonstrate that these behavioral fingerprints are highly robust against common modifications, including finetunes, merges, and quantization. Our experiments show that the fingerprint is unique to each model family, with low cosine similarity between independently trained models. In a large-scale identification task across 76 offspring models, our method achieves 100\% accuracy in identifying the correct base model family. Furthermore, we analyze the fingerprint's behavior under alignment-breaking attacks, finding that while performance degrades significantly, detectable traces remain. Finally, we propose a theoretical framework to transform this private fingerprint into a publicly verifiable, privacy-preserving artifact using locality-sensitive hashing and zero-knowledge proofs.