Auditing Multi-Agent LLM Reasoning Trees Outperforms Majority Vote and LLM-as-Judge
作者: Wei Yang, Shixuan Li, Heng Ping, Peiyu Zhang, Paul Bogdan, Jesse Thomason
分类: cs.AI
发布日期: 2026-02-10
💡 一句话要点
提出AgentAuditor,通过推理树审核多智能体LLM,提升复杂推理任务准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 推理树 证据推理 反共识偏好优化
📋 核心要点
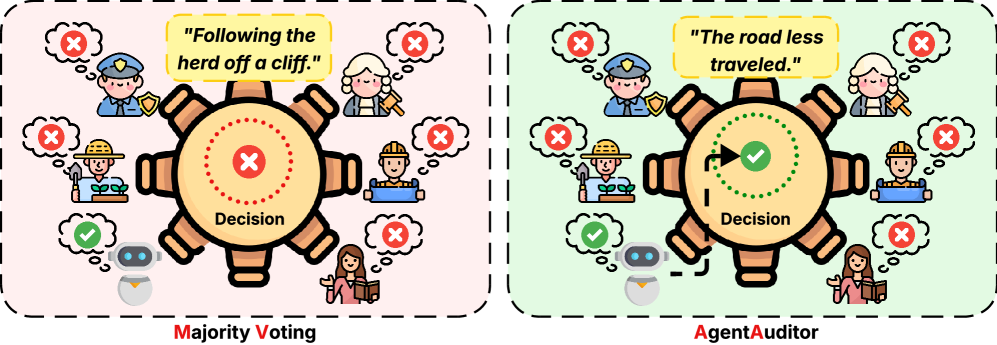
- 现有方法在多智能体LLM推理中依赖多数投票,忽略了推理过程中的证据信息,易受“虚构共识”影响。
- AgentAuditor构建推理树,通过在分歧点比较推理分支进行局部验证,从而解决智能体间的冲突。
- 实验表明,AgentAuditor在多个任务中显著优于多数投票和LLM-as-Judge,精度提升高达5%。
📝 摘要(中文)
多智能体系统(MAS)能够显著扩展大型语言模型(LLM)的推理能力,但现有框架大多采用多数投票来聚合智能体的输出。这种启发式方法忽略了推理轨迹的证据结构,并且在“虚构共识”下表现脆弱,即智能体共享相关的偏见并收敛于相同的错误理由。我们引入AgentAuditor,它用推理树上的路径搜索取代投票,该推理树显式地表示智能体轨迹之间的协议和分歧。AgentAuditor通过比较关键分歧点的推理分支来解决冲突,将全局裁决转化为高效的局部验证。我们进一步提出了反共识偏好优化(ACPO),它在多数失败的情况下训练仲裁者,并奖励基于证据的少数选择,而不是流行的错误。AgentAuditor与MAS设置无关,我们发现在5个流行的设置中,它比多数投票的绝对精度提高了5%,比使用LLM-as-Judge提高了3%。
🔬 方法详解
问题定义:现有基于多智能体LLM的推理框架,通常采用多数投票的方式整合多个智能体的输出结果。这种方法忽略了每个智能体推理过程中的证据信息,容易受到“虚构共识”的影响,即多个智能体由于共享相似的偏见,最终得出相同的错误结论。因此,如何有效利用多智能体的推理轨迹,避免“虚构共识”带来的负面影响,是本文要解决的核心问题。
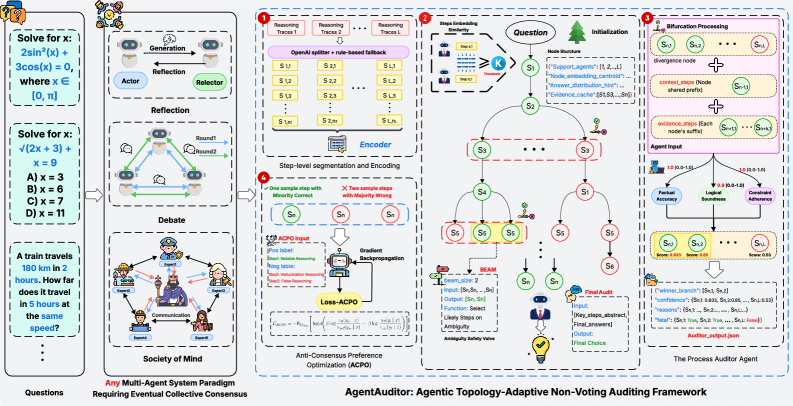
核心思路:AgentAuditor的核心思路是将多智能体的推理过程表示为一棵推理树,树的节点代表推理步骤,边代表智能体在该步骤上的选择。通过在推理树上进行路径搜索,找到最佳的推理路径。AgentAuditor的关键在于能够识别推理过程中的分歧点,并在这些分歧点上进行局部验证,从而避免全局裁决带来的计算开销。
技术框架:AgentAuditor的整体框架包括以下几个主要模块:1) 推理树构建:将多个智能体的推理轨迹构建成一棵推理树,记录每个智能体在每个推理步骤上的选择。2) 分歧点识别:识别推理树中的分歧点,即不同智能体在同一推理步骤上做出不同选择的节点。3) 局部验证:在分歧点上,使用仲裁者(adjudicator)对不同的推理分支进行评估,选择更合理的推理路径。4) 路径搜索:在推理树上进行路径搜索,找到最佳的推理路径,作为最终的推理结果。
关键创新:AgentAuditor最重要的创新在于将全局裁决转化为局部验证。传统的多数投票方法需要对所有智能体的输出进行全局评估,而AgentAuditor只需要在分歧点上对不同的推理分支进行局部验证,从而大大降低了计算开销。此外,AgentAuditor还提出了反共识偏好优化(ACPO)方法,通过在多数失败的情况下训练仲裁者,提高其识别错误推理路径的能力。
关键设计:AgentAuditor的关键设计包括:1) 推理树的表示:如何有效地表示推理树,包括节点和边的定义,以及如何记录智能体的选择。2) 分歧点的识别策略:如何准确地识别推理树中的分歧点,避免遗漏或误判。3) 仲裁者的训练方法:如何训练一个有效的仲裁者,使其能够准确地评估不同的推理分支。ACPO是一种关键的训练策略,它通过在多数失败的情况下训练仲裁者,提高其识别错误推理路径的能力。具体来说,ACPO会奖励那些基于证据的少数选择,而不是流行的错误。
🖼️ 关键图片
📊 实验亮点
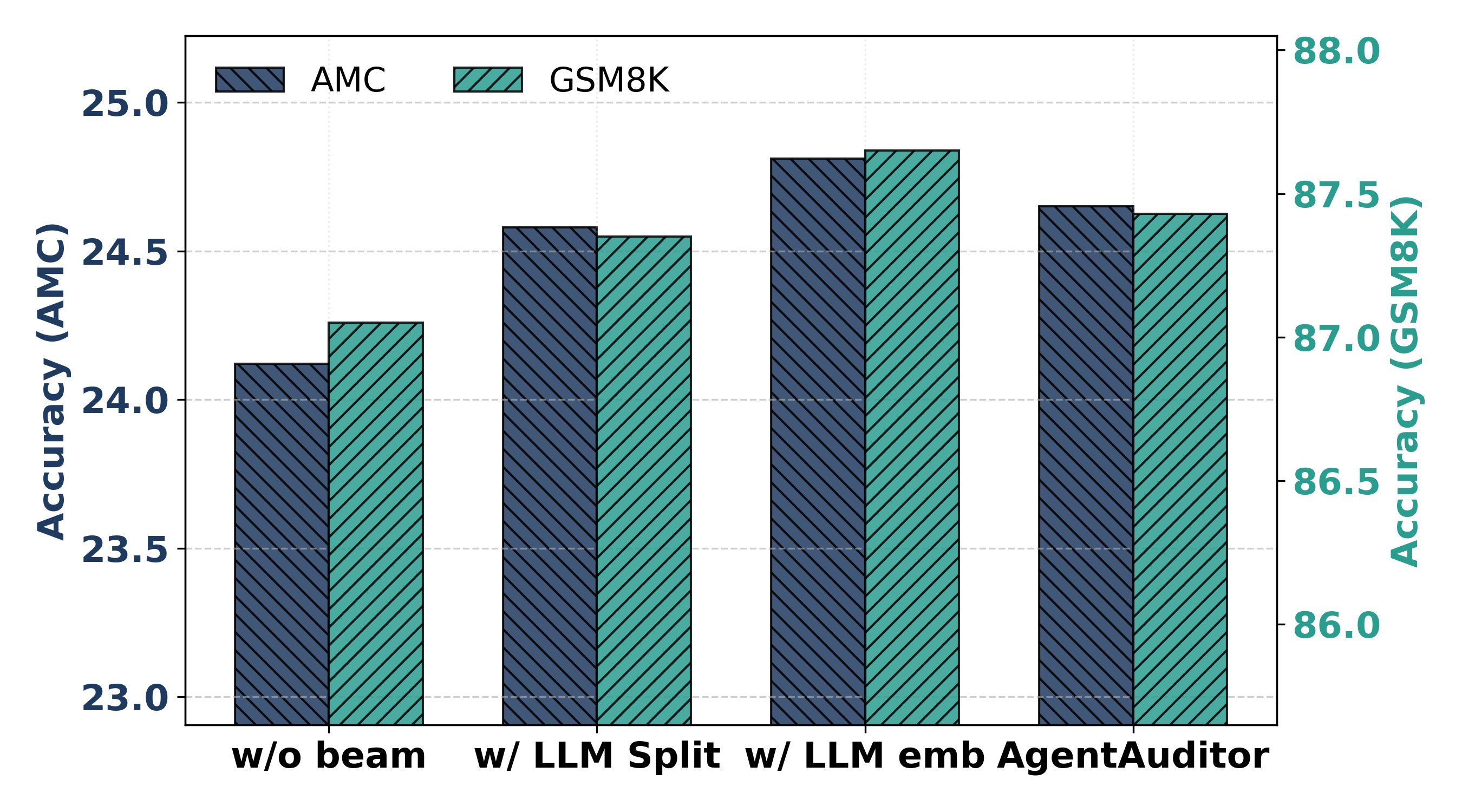
实验结果表明,AgentAuditor在5个流行的多智能体推理任务中,显著优于传统的多数投票方法和LLM-as-Judge方法。具体来说,AgentAuditor的绝对精度比多数投票提高了高达5%,比LLM-as-Judge提高了高达3%。这些结果表明,AgentAuditor能够有效地利用多智能体的推理轨迹,避免“虚构共识”带来的负面影响,从而提高推理准确率。
🎯 应用场景
AgentAuditor可应用于需要复杂推理的各种场景,例如问答系统、代码生成、策略规划等。通过提升多智能体LLM的推理准确率,可以提高这些应用系统的性能和可靠性。该研究对于构建更强大的多智能体协作系统具有重要意义,并有望推动人工智能在复杂问题解决方面的应用。
📄 摘要(原文)
Multi-agent systems (MAS) can substantially extend the reasoning capacity of large language models (LLMs), yet most frameworks still aggregate agent outputs with majority voting. This heuristic discards the evidential structure of reasoning traces and is brittle under the confabulation consensus, where agents share correlated biases and converge on the same incorrect rationale. We introduce AgentAuditor, which replaces voting with a path search over a Reasoning Tree that explicitly represents agreements and divergences among agent traces. AgentAuditor resolves conflicts by comparing reasoning branches at critical divergence points, turning global adjudication into efficient, localized verification. We further propose Anti-Consensus Preference Optimization (ACPO), which trains the adjudicator on majority-failure cases and rewards evidence-based minority selections over popular errors. AgentAuditor is agnostic to MAS setting, and we find across 5 popular settings that it yields up to 5% absolute accuracy improvement over a majority vote, and up to 3% over using LLM-as-Judge.