iGRPO: Self-Feedback-Driven LLM Reasoning
作者: Ali Hatamizadeh, Shrimai Prabhumoye, Igor Gitman, Ximing Lu, Seungju Han, Wei Ping, Yejin Choi, Jan Kautz
分类: cs.AI
发布日期: 2026-02-09
备注: Tech report
💡 一句话要点
提出iGRPO:一种自反馈驱动的LLM推理方法,提升数学问题求解的准确性和一致性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 数学推理 自反馈 策略优化
📋 核心要点
- 现有LLM在复杂数学问题求解中表现不足,缺乏准确性和一致性,需要更有效的训练方法。
- iGRPO通过两阶段迭代,利用模型生成的草稿进行自反馈,提升策略改进能力,超越先前尝试。
- 实验表明iGRPO在多个基准测试中优于GRPO,并在AIME24/25上取得SOTA结果,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)在解决复杂的数学问题方面展现了潜力,但仍然无法产生准确和一致的解决方案。强化学习(RL)是使这些模型与特定任务奖励对齐的框架,从而提高整体质量和可靠性。Group Relative Policy Optimization (GRPO)是一种高效的、无值函数的Proximal Policy Optimization (PPO)替代方案,它利用组相对奖励归一化。我们引入了Iterative Group Relative Policy Optimization (iGRPO),它是GRPO的两阶段扩展,通过模型生成的草稿添加动态自条件反射。在第一阶段,iGRPO采样多个探索性草稿,并使用与优化相同的标量奖励信号选择最高奖励的草稿。在第二阶段,它将这个最佳草稿附加到原始提示中,并对草稿条件下的改进应用GRPO风格的更新,训练策略以超越其最强的先前尝试。在匹配的rollout预算下,iGRPO始终优于GRPO,验证了其在不同推理基准上的有效性。此外,将iGRPO应用于在AceReason-Math上训练的OpenReasoning-Nemotron-7B,在AIME24和AIME25上分别实现了85.62%和79.64%的最新结果。消融实验进一步表明,改进wrapper可以推广到GRPO变体之外,受益于生成式judge,并通过延迟熵崩溃来改变学习动态。这些结果强调了迭代的、基于自反馈的RL在推进可验证的数学推理方面的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂数学推理问题中准确性和一致性不足的问题。现有方法,如直接使用LLM或通过简单的强化学习微调,往往难以达到理想的效果,尤其是在需要多步推理的场景下,容易出现错误累积。
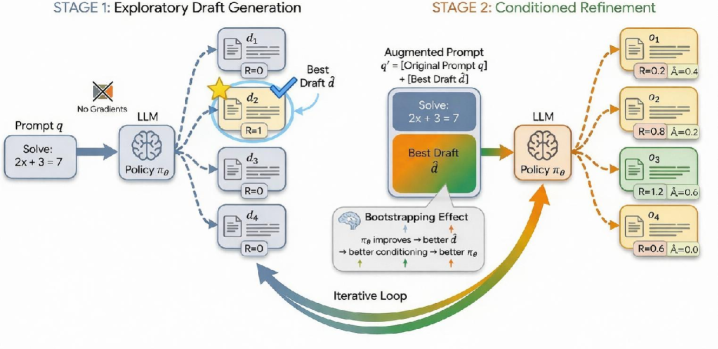
核心思路:iGRPO的核心思路是利用模型自身的输出来指导后续的训练过程,通过迭代地生成草稿并选择最佳草稿作为反馈信号,从而实现更有效的策略优化。这种自反馈机制允许模型逐步改进其推理能力,并克服了传统强化学习方法中奖励信号稀疏的问题。
技术框架:iGRPO包含两个主要阶段:第一阶段是草稿生成阶段,模型基于原始提示生成多个候选草稿,并使用奖励函数选择最佳草稿。第二阶段是改进阶段,将最佳草稿附加到原始提示中,作为条件信息,然后使用GRPO风格的更新来训练模型,使其在最佳草稿的基础上进行改进。整个过程迭代进行,不断提升模型的推理能力。
关键创新:iGRPO的关键创新在于引入了自反馈机制,通过模型自身生成的草稿来指导训练过程。这种方法避免了对外部监督信号的依赖,并允许模型在探索过程中发现更有效的推理策略。此外,iGRPO还采用了GRPO作为优化算法,提高了训练效率和稳定性。
关键设计:iGRPO的关键设计包括:1) 使用标量奖励信号来评估草稿的质量,奖励信号可以是数学问题的正确率或其他相关指标。2) 将最佳草稿附加到原始提示中,作为条件信息,引导模型在最佳草稿的基础上进行改进。3) 使用GRPO算法进行策略优化,GRPO是一种高效的、无值函数的强化学习算法,适用于大规模语言模型的训练。4) 通过消融实验验证了各个组件的有效性,例如生成式judge和延迟熵崩溃。
🖼️ 关键图片

📊 实验亮点
iGRPO在多个数学推理基准测试中取得了显著的性能提升。例如,在AIME24和AIME25数据集上,使用OpenReasoning-Nemotron-7B模型,iGRPO分别达到了85.62%和79.64%的准确率,刷新了SOTA记录。此外,在匹配的rollout预算下,iGRPO始终优于GRPO,验证了其有效性。
🎯 应用场景
iGRPO可应用于需要复杂推理和问题解决能力的领域,如数学、科学、工程等。该方法能够提升LLM在这些领域的应用效果,例如自动解题、科学发现、智能设计等,具有广泛的应用前景和实际价值。未来,iGRPO有望推动LLM在更复杂和具有挑战性的任务中取得突破。
📄 摘要(原文)
Large Language Models (LLMs) have shown promise in solving complex mathematical problems, yet they still fall short of producing accurate and consistent solutions. Reinforcement Learning (RL) is a framework for aligning these models with task-specific rewards, improving overall quality and reliability. Group Relative Policy Optimization (GRPO) is an efficient, value-function-free alternative to Proximal Policy Optimization (PPO) that leverages group-relative reward normalization. We introduce Iterative Group Relative Policy Optimization (iGRPO), a two-stage extension of GRPO that adds dynamic self-conditioning through model-generated drafts. In Stage 1, iGRPO samples multiple exploratory drafts and selects the highest-reward draft using the same scalar reward signal used for optimization. In Stage 2, it appends this best draft to the original prompt and applies a GRPO-style update on draft-conditioned refinements, training the policy to improve beyond its strongest prior attempt. Under matched rollout budgets, iGRPO consistently outperforms GRPO across base models (e.g., Nemotron-H-8B-Base-8K and DeepSeek-R1 Distilled), validating its effectiveness on diverse reasoning benchmarks. Moreover, applying iGRPO to OpenReasoning-Nemotron-7B trained on AceReason-Math achieves new state-of-the-art results of 85.62\% and 79.64\% on AIME24 and AIME25, respectively. Ablations further show that the refinement wrapper generalizes beyond GRPO variants, benefits from a generative judge, and alters learning dynamics by delaying entropy collapse. These results underscore the potential of iterative, self-feedback-based RL for advancing verifiable mathematical reasoning.