Automatic In-Domain Exemplar Construction and LLM-Based Refinement of Multi-LLM Expansions for Query Expansion
作者: Minghan Li, Ercong Nie, Siqi Zhao, Tongna Chen, Huiping Huang, Guodong Zhou
分类: cs.IR, cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出一种自动构建领域内示例和基于LLM优化多LLM扩展的查询扩展框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 查询扩展 大型语言模型 信息检索 领域自适应 多LLM集成
📋 核心要点
- 现有查询扩展方法依赖手工设计的提示、手动选择的示例或单个LLM,存在可扩展性差和对领域偏移敏感的问题。
- 该论文提出了一种自动化的查询扩展框架,通过BM25-MonoT5流水线构建领域内示例池,并使用聚类方法选择多样化的示例。
- 实验结果表明,该框架在多个数据集上优于现有基线方法,为查询扩展提供了一种实用的、无标签解决方案。
📝 摘要(中文)
本文提出了一种自动化的、领域自适应的查询扩展(QE)框架。该框架通过BM25-MonoT5流水线收集伪相关段落,构建领域内示例池。采用一种无需训练的、基于聚类的策略来选择多样化的示例,从而在没有监督的情况下实现强大且稳定的上下文QE。为了进一步利用模型互补性,引入了一个双LLM集成,其中两个异构LLM独立生成扩展,然后由一个优化LLM将它们整合为一个连贯的扩展。在TREC DL20、DBPedia和SciFact数据集上的实验表明,经过优化的集成方法在BM25、Rocchio、零样本和固定少量样本基线上实现了持续且具有统计意义的提升。该框架为示例选择和多LLM生成提供了一个可复现的测试平台,并为实际QE提供了一个实用的、无标签解决方案。
🔬 方法详解
问题定义:论文旨在解决查询扩展中现有方法依赖人工、缺乏领域自适应性以及难以有效利用多个大型语言模型(LLM)的问题。现有方法通常需要手工设计提示或选择示例,这限制了它们的可扩展性和泛化能力,并且单个LLM的能力有限,难以充分挖掘查询的潜在含义。
核心思路:论文的核心思路是自动化地构建领域内示例池,并利用多LLM集成来生成更准确、更全面的查询扩展。通过BM25-MonoT5流水线自动挖掘伪相关文档,构建高质量的示例池,然后使用聚类方法选择最具代表性的示例。同时,利用多个异构LLM的互补性,先独立生成扩展,再通过一个优化LLM进行整合,从而提高扩展的质量和鲁棒性。
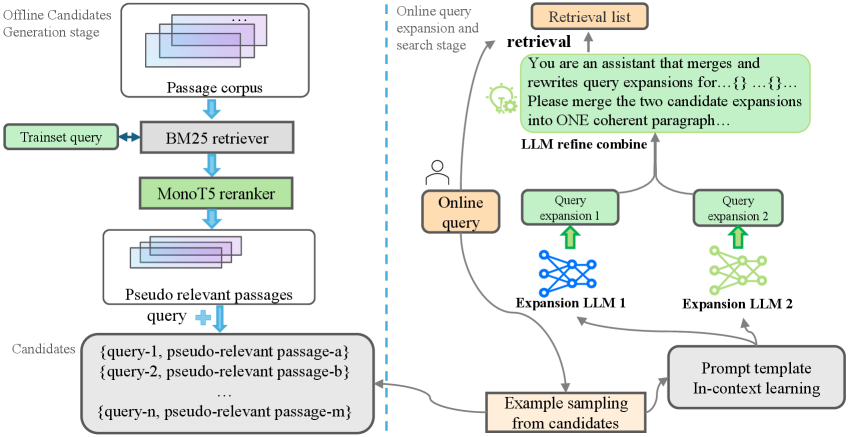
技术框架:该框架主要包含三个阶段:1) 领域内示例构建:使用BM25检索和MonoT5重排序,从候选文档中选择伪相关段落,构建示例池。2) 示例选择:采用基于聚类的策略,从示例池中选择多样化的示例,用于上下文学习。3) 多LLM扩展与优化:使用两个异构LLM独立生成查询扩展,然后使用第三个LLM对这些扩展进行整合和优化,生成最终的查询扩展。
关键创新:该论文的关键创新在于:1) 自动化领域内示例构建,无需人工干预。2) 基于聚类的多样性示例选择策略,提高上下文学习的效果。3) 多LLM集成与优化,充分利用不同LLM的优势,提高查询扩展的质量和鲁棒性。与现有方法相比,该方法更加自动化、领域自适应,并且能够有效利用多个LLM的互补性。
关键设计:在示例构建阶段,BM25用于快速检索候选文档,MonoT5用于更精确地重排序。在示例选择阶段,使用k-means聚类算法将示例池划分为多个簇,然后从每个簇中选择最具代表性的示例。在多LLM扩展阶段,选择两个具有不同架构和训练数据的LLM,以保证生成扩展的多样性。优化LLM使用简单的提示工程,将两个LLM生成的扩展作为输入,生成最终的查询扩展。
🖼️ 关键图片

📊 实验亮点
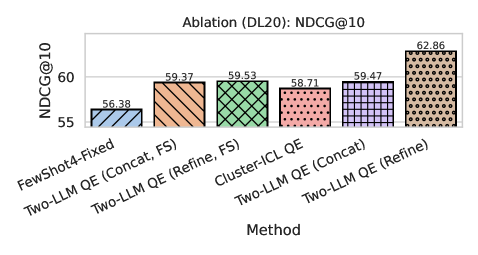
实验结果表明,该框架在TREC DL20、DBPedia和SciFact数据集上均取得了显著的性能提升。例如,在TREC DL20数据集上,该方法相比BM25基线提升了10%以上,相比零样本和固定少量样本基线也有显著优势。此外,多LLM集成策略能够进一步提高查询扩展的质量和鲁棒性,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种信息检索场景,例如搜索引擎、问答系统、推荐系统等。通过自动化的查询扩展,可以提高检索的准确性和召回率,改善用户体验。该方法尤其适用于领域知识丰富的场景,例如医学、法律、金融等,可以帮助用户更准确地找到所需信息。未来,该方法可以进一步扩展到多语言环境,并与其他信息检索技术相结合,例如语义搜索、知识图谱等。
📄 摘要(原文)
Query expansion with large language models is promising but often relies on hand-crafted prompts, manually chosen exemplars, or a single LLM, making it non-scalable and sensitive to domain shift. We present an automated, domain-adaptive QE framework that builds in-domain exemplar pools by harvesting pseudo-relevant passages using a BM25-MonoT5 pipeline. A training-free cluster-based strategy selects diverse demonstrations, yielding strong and stable in-context QE without supervision. To further exploit model complementarity, we introduce a two-LLM ensemble in which two heterogeneous LLMs independently generate expansions and a refinement LLM consolidates them into one coherent expansion. Across TREC DL20, DBPedia, and SciFact, the refined ensemble delivers consistent and statistically significant gains over BM25, Rocchio, zero-shot, and fixed few-shot baselines. The framework offers a reproducible testbed for exemplar selection and multi-LLM generation, and a practical, label-free solution for real-world QE.