Efficient and Stable Reinforcement Learning for Diffusion Language Models
作者: Jiawei Liu, Xiting Wang, Yuanyuan Zhong, Defu Lian, Yu Yang
分类: cs.AI
发布日期: 2026-02-09
备注: 13 pages, 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出时空剪枝(STP)框架,提升扩散语言模型强化学习的效率与稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 强化学习 时空剪枝 效率优化 稳定性提升
📋 核心要点
- 扩散语言模型的强化学习面临效率和稳定性挑战,现有方法难以兼顾。
- 论文提出时空剪枝(STP)框架,通过空间和时间两个维度压缩生成过程的冗余信息。
- 实验结果表明,STP在效率和准确性上均优于现有方法,实现了性能提升。
📝 摘要(中文)
强化学习(RL)对于释放基于扩散的大型语言模型(dLLMs)的复杂推理能力至关重要。然而,将RL应用于dLLMs在效率和稳定性方面面临独特的挑战。为了应对这些挑战,我们提出了时空剪枝(STP)框架,旨在同时提高dLLMs强化学习的效率和稳定性。STP通过以下方式压缩生成过程中的冗余:(1)空间剪枝,利用静态先验约束探索空间;(2)时间剪枝,绕过冗余的后期细化步骤。我们的理论分析表明,STP严格降低了对数似然估计的方差,从而确保了更稳定的策略更新。大量的实验表明,STP在效率和准确性方面都超过了最先进的基线。
🔬 方法详解
问题定义:论文旨在解决将强化学习应用于扩散语言模型(dLLMs)时,效率低下和训练不稳定的问题。现有的方法通常需要大量的计算资源和时间来探索策略空间,并且容易受到高方差梯度估计的影响,导致策略更新不稳定。
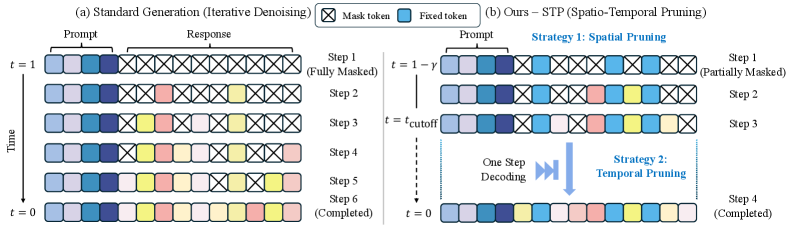
核心思路:论文的核心思路是通过剪枝来减少生成过程中的冗余,从而提高效率和稳定性。具体来说,通过“空间剪枝”约束探索空间,利用静态先验知识减少不必要的探索;通过“时间剪枝”跳过冗余的后期细化步骤,减少计算量。
技术框架:STP框架包含两个主要模块:空间剪枝和时间剪枝。空间剪枝模块利用静态先验知识(例如,预训练模型的知识)来约束生成过程的探索空间,减少无效的探索。时间剪枝模块通过提前停止扩散过程,跳过冗余的后期细化步骤,从而减少计算量。这两个模块可以同时使用,以实现最佳的效率和稳定性。
关键创新:STP的关键创新在于同时在空间和时间两个维度上进行剪枝,从而更有效地压缩生成过程的冗余。与传统的剪枝方法不同,STP不仅减少了计算量,还降低了对数似然估计的方差,从而提高了策略更新的稳定性。
关键设计:空间剪枝的具体实现方式是使用一个静态先验模型来指导扩散过程的采样。时间剪枝的具体实现方式是根据一个预定义的阈值来提前停止扩散过程。论文还提供了理论分析,证明了STP可以降低对数似然估计的方差。具体的参数设置和损失函数细节在论文中有详细描述,例如如何选择合适的阈值来平衡效率和性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,STP在多个任务上都优于现有的强化学习方法。例如,在文本生成任务中,STP在保持生成质量的同时,显著降低了计算成本,并提高了训练的稳定性。与基线方法相比,STP在效率和准确性方面均取得了显著提升。
🎯 应用场景
该研究成果可应用于各种需要高效且稳定强化学习的扩散语言模型场景,例如文本生成、图像生成、对话系统等。通过降低计算成本和提高训练稳定性,STP可以促进dLLMs在资源受限环境中的应用,并加速相关领域的研究进展。未来,该方法有望扩展到其他生成模型和强化学习任务中。
📄 摘要(原文)
Reinforcement Learning (RL) is crucial for unlocking the complex reasoning capabilities of Diffusion-based Large Language Models (dLLMs). However, applying RL to dLLMs faces unique challenges in efficiency and stability. To address these challenges, we propose Spatio-Temporal Pruning (STP), a framework designed to simultaneously improve the efficiency and stability of RL for dLLMs. STP compresses the redundancy in the generative process through: (1) \textit{spatial pruning}, which constrains the exploration space using static priors; and (2) \textit{temporal pruning}, which bypasses redundant late-stage refinement steps. Our theoretical analysis demonstrates that STP strictly reduces the variance of the log-likelihood estimation, thereby ensuring more stable policy updates. Extensive experiments demonstrate that STP surpasses state-of-the-art baselines in both efficiency and accuracy. Our code is available at https://github.com/Lolo1222/STP.