OmniReview: A Large-scale Benchmark and LLM-enhanced Framework for Realistic Reviewer Recommendation
作者: Yehua Huang, Penglei Sun, Zebin Chen, Zhenheng Tang, Xiaowen Chu
分类: cs.IR, cs.AI
发布日期: 2026-02-09
💡 一句话要点
OmniReview:提出大规模评审推荐基准与LLM增强框架Pro-MMoE,提升评审专家推荐的准确性和可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 评审推荐 大型语言模型 多任务学习 专家画像 学术同行评审
📋 核心要点
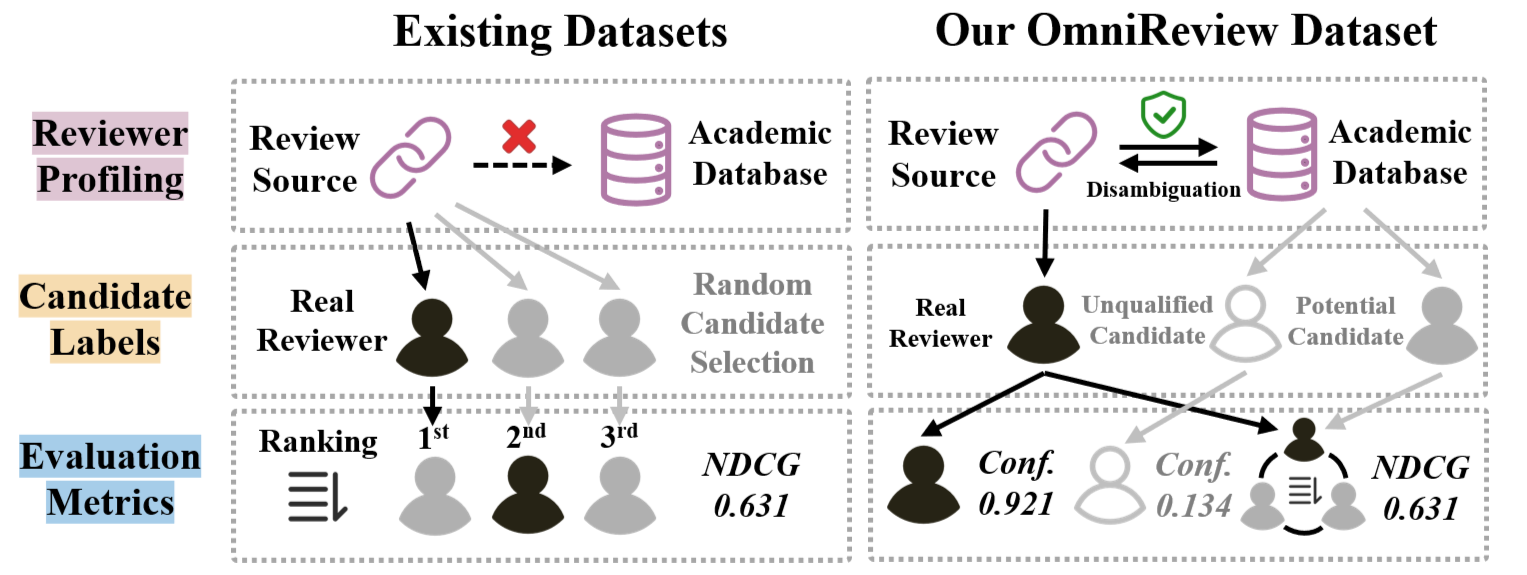
- 现有评审推荐方法缺乏大规模真实数据集支持,评估指标也过于简化,难以反映实际评审流程。
- 论文提出Pro-MMoE框架,利用LLM生成学者语义画像,结合多任务学习,提升推荐准确性和可解释性。
- 实验表明,Pro-MMoE在OmniReview数据集上,在多个指标上超越现有方法,成为新的评审推荐基准。
📝 摘要(中文)
学术同行评审是学术验证的基石,但该领域在数据和方法上面临挑战。在数据方面,现有研究受到大规模、验证过的基准数据集的稀缺以及过于简化的评估指标的限制,这些指标未能反映真实的编辑工作流程。为了弥合这一差距,我们提出了OmniReview,这是一个综合数据集,通过消歧流程整合了多源学术平台,涵盖了全面的学者资料,产生了202,756条经过验证的评审记录。基于此数据,我们引入了一个三层分级评估框架,用于评估从召回到精确专家识别的推荐。在方法方面,现有的基于嵌入的方法受到语义压缩的信息瓶颈和有限的可解释性的影响。为了解决这些方法上的局限性,我们提出了一种利用多门混合专家对学者进行画像的新框架(Pro-MMoE),该框架将大型语言模型(LLM)与多任务学习相结合。具体来说,它利用LLM生成的语义画像来保留细粒度的专业知识细微差别和可解释性,同时采用任务自适应的MMoE架构来动态平衡相互冲突的评估目标。全面的实验表明,Pro-MMoE在七个指标中的六个上实现了最先进的性能,为真实的评审专家推荐建立了一个新的基准。
🔬 方法详解
问题定义:论文旨在解决现有评审专家推荐方法在真实场景下的不足,包括缺乏大规模验证数据集、评估指标简化以及方法本身的信息瓶颈和可解释性差等问题。现有方法难以准确捕捉学者的细粒度专业知识,且推荐结果缺乏透明度,影响了评审质量和效率。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语义理解能力,为学者构建更丰富、更细粒度的专业知识画像。同时,采用多任务学习框架,平衡不同评估指标的需求,从而提升推荐的准确性和可解释性。
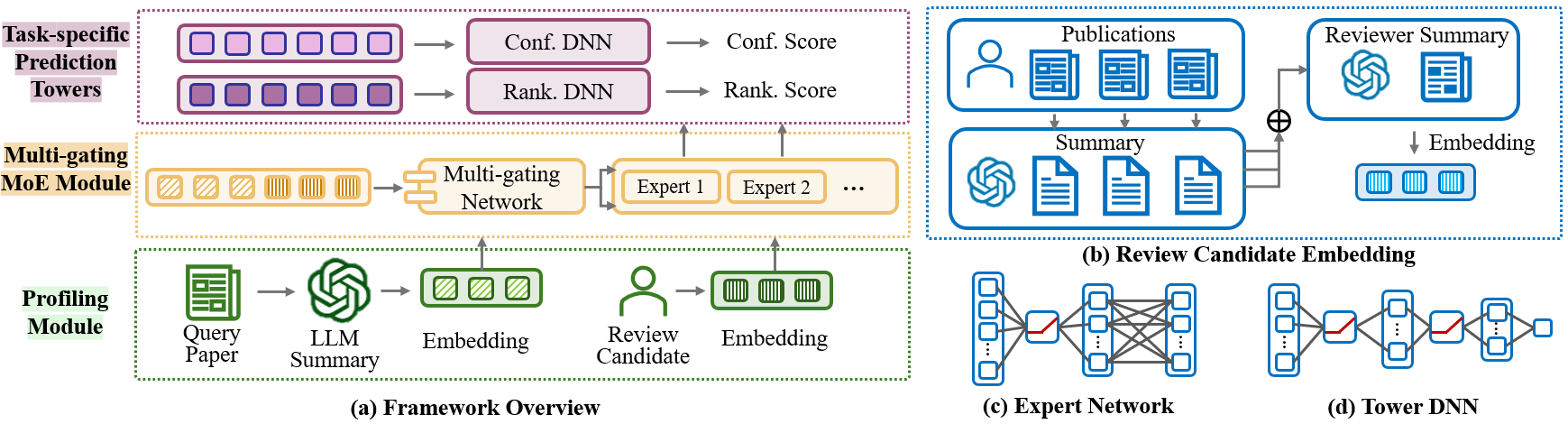
技术框架:Pro-MMoE框架主要包含以下几个模块:1) 数据预处理:构建大规模评审数据集OmniReview,并进行学者信息消歧;2) LLM语义画像生成:利用LLM从学者发表的论文等信息中提取语义特征,构建学者画像;3) 任务自适应MMoE:设计多门混合专家(MMoE)架构,针对不同的评估指标(如召回率、精确率等)学习不同的专家网络,并通过门控机制动态调整不同专家的权重;4) 推荐排序:根据MMoE的输出,对候选评审专家进行排序,并推荐给编辑。
关键创新:论文的关键创新在于:1) 提出了OmniReview大规模评审数据集,为评审推荐研究提供了可靠的基准;2) 将LLM引入评审专家推荐,利用LLM生成细粒度的学者语义画像,有效解决了信息瓶颈问题;3) 设计了任务自适应MMoE架构,能够动态平衡不同评估指标的需求,提升整体推荐性能。
关键设计:在LLM语义画像生成方面,论文可能采用了Prompt Engineering等技术,引导LLM提取关键信息。在MMoE架构中,门控网络的具体设计(如激活函数、层数等)以及专家网络的数量和结构是关键参数。损失函数的设计也至关重要,需要综合考虑不同评估指标的优化目标。
🖼️ 关键图片

📊 实验亮点
Pro-MMoE在OmniReview数据集上进行了实验,结果表明,该方法在七个评估指标中的六个上取得了state-of-the-art的性能。相较于现有方法,Pro-MMoE在推荐准确率和召回率上均有显著提升,证明了LLM和多任务学习在评审专家推荐中的有效性。
🎯 应用场景
该研究成果可应用于学术期刊、会议等平台的评审专家推荐系统,提高评审效率和质量,促进学术交流和发展。此外,该方法也可推广到其他专家推荐场景,如招聘、咨询等领域,具有广泛的应用前景。
📄 摘要(原文)
Academic peer review remains the cornerstone of scholarly validation, yet the field faces some challenges in data and methods. From the data perspective, existing research is hindered by the scarcity of large-scale, verified benchmarks and oversimplified evaluation metrics that fail to reflect real-world editorial workflows. To bridge this gap, we present OmniReview, a comprehensive dataset constructed by integrating multi-source academic platforms encompassing comprehensive scholarly profiles through the disambiguation pipeline, yielding 202, 756 verified review records. Based on this data, we introduce a three-tier hierarchical evaluaion framework to assess recommendations from recall to precise expert identification. From the method perspective, existing embedding-based approaches suffer from the information bottleneck of semantic compression and limited interpretability. To resolve these method limitations, we propose Profiling Scholars with Multi-gate Mixture-of-Experts (Pro-MMoE), a novel framework that synergizes Large Language Models (LLMs) with Multi-task Learning. Specifically, it utilizes LLM-generated semantic profiles to preserve fine-grained expertise nuances and interpretability, while employing a Task-Adaptive MMoE architecture to dynamically balance conflicting evaluation goals. Comprehensive experiments demonstrate that Pro-MMoE achieves state-of-the-art performance across six of seven metrics, establishing a new benchmark for realistic reviewer recommendation.