Scalable Delphi: Large Language Models for Structured Risk Estimation
作者: Tobias Lorenz, Mario Fritz
分类: cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出Scalable Delphi,利用大语言模型实现可扩展的结构化风险评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 风险评估 专家意见征询 Delphi方法 网络安全
📋 核心要点
- 传统Delphi方法耗时耗力,难以满足快速风险评估的需求,限制了其应用范围。
- Scalable Delphi利用LLM模拟专家组,通过迭代优化和理由共享,实现高效的结构化风险评估。
- 实验表明,LLM专家组在网络安全风险评估中与人类专家组高度一致,且评估效率大幅提升。
📝 摘要(中文)
在高风险领域进行定量风险评估依赖于结构化的专家意见征询来估计不可观测的属性。Delphi方法是黄金标准,它能产生经过校准、可审计的判断,但需要数月的协调和专家时间,使得严格的风险评估对大多数应用来说遥不可及。本文研究了大型语言模型(LLM)是否可以作为结构化专家意见征询的可扩展代理。我们提出了Scalable Delphi,将经典协议适配于LLM,包括多样化的专家角色、迭代改进和理由共享。由于目标量通常是不可观测的,我们开发了一个基于必要条件的评估框架:针对可验证代理的校准、对证据的敏感性以及与人类专家判断的一致性。我们在AI增强的网络安全风险领域进行了评估,使用了三个能力基准和独立的人工意见征询研究。LLM专家组与基准真值实现了很强的相关性(Pearson r=0.87-0.95),随着证据的增加系统性地改进,并与人类专家组保持一致——在一个比较中,比两个人类专家组彼此之间更接近。这表明,基于LLM的意见征询可以将结构化专家判断扩展到传统方法不可行的环境中,将意见征询时间从数月缩短到几分钟。
🔬 方法详解
问题定义:论文旨在解决传统Delphi方法在定量风险评估中耗时过长、成本过高的问题,使得结构化专家意见征询难以应用于需要快速响应的场景。现有方法的痛点在于需要大量人工协调和专家时间,无法实现快速、可扩展的风险评估。
核心思路:论文的核心思路是利用大型语言模型(LLM)模拟专家组,通过设计合适的prompt和迭代优化流程,使LLM能够像人类专家一样进行结构化的风险评估。通过将专家知识编码到LLM中,并利用LLM的推理能力,可以显著降低风险评估的时间和成本。
技术框架:Scalable Delphi的技术框架主要包括以下几个阶段:1) 专家角色定义:为LLM设定不同的专家角色,例如安全工程师、威胁情报分析师等,以模拟多样化的专家视角。2) 初始评估:每个专家角色独立对目标风险进行初始评估,并给出评估理由。3) 迭代改进:将所有专家的评估结果和理由共享给其他专家,并允许专家根据新的信息调整自己的评估。这个过程可以迭代多次,直到评估结果趋于稳定。4) 结果汇总:将所有专家的最终评估结果进行汇总,得到最终的风险评估结果。
关键创新:论文最重要的技术创新点在于将传统的Delphi方法适配于LLM,并设计了一套完整的流程来实现可扩展的结构化风险评估。与现有方法相比,Scalable Delphi无需人工协调和专家参与,可以显著降低风险评估的时间和成本。此外,论文还提出了一个基于必要条件的评估框架,用于评估LLM生成的风险评估结果的质量。
关键设计:论文的关键设计包括:1) Prompt设计:设计合适的prompt来引导LLM进行风险评估,包括明确目标风险、提供相关背景信息、要求给出评估理由等。2) 迭代次数:确定合适的迭代次数,以平衡评估结果的准确性和评估效率。3) 结果汇总方法:选择合适的汇总方法来整合不同专家的评估结果,例如取平均值、加权平均值等。4) 评估指标:使用校准度、敏感性和一致性等指标来评估LLM生成的风险评估结果的质量。
🖼️ 关键图片


📊 实验亮点
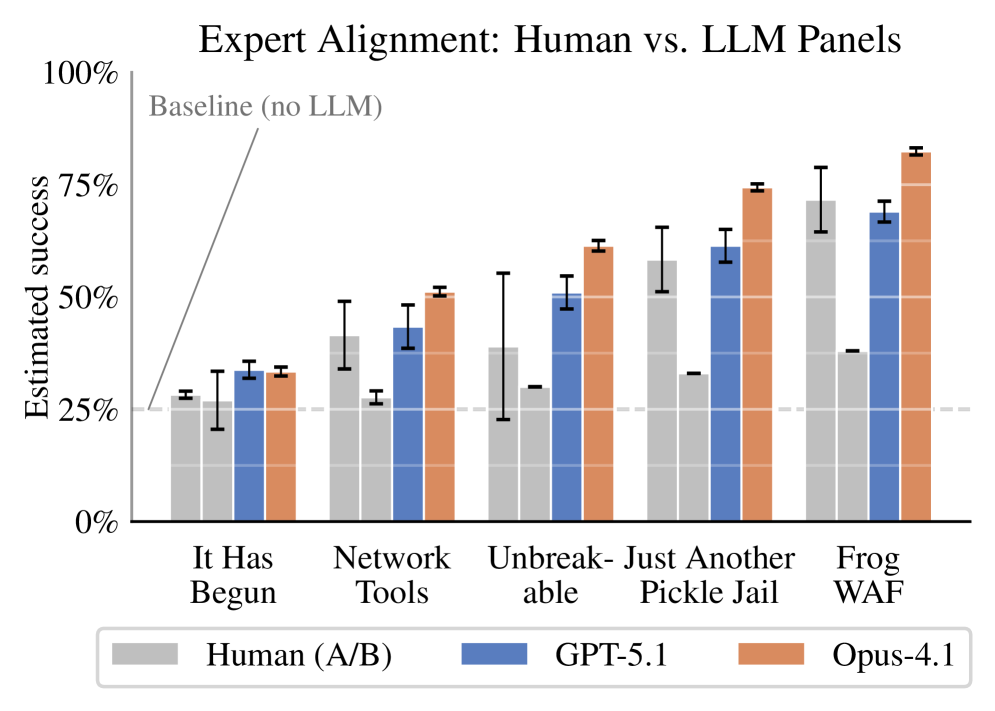
实验结果表明,Scalable Delphi在AI增强的网络安全风险评估中表现出色。LLM专家组与基准真值实现了很强的相关性(Pearson r=0.87-0.95),并且随着证据的增加,评估结果系统性地改进。此外,LLM专家组的评估结果与人类专家组高度一致,甚至在一个比较中,LLM专家组比两个人类专家组彼此之间更接近。这表明Scalable Delphi能够有效地模拟人类专家的风险评估能力。
🎯 应用场景
Scalable Delphi可应用于各种需要快速、低成本风险评估的领域,例如网络安全、金融风险管理、供应链风险管理等。该方法可以帮助企业和组织更有效地识别和应对潜在风险,提高决策效率和风险管理水平。未来,该方法还可以扩展到其他需要专家意见征询的领域,例如政策制定、产品设计等。
📄 摘要(原文)
Quantitative risk assessment in high-stakes domains relies on structured expert elicitation to estimate unobservable properties. The gold standard - the Delphi method - produces calibrated, auditable judgments but requires months of coordination and specialist time, placing rigorous risk assessment out of reach for most applications. We investigate whether Large Language Models (LLMs) can serve as scalable proxies for structured expert elicitation. We propose Scalable Delphi, adapting the classical protocol for LLMs with diverse expert personas, iterative refinement, and rationale sharing. Because target quantities are typically unobservable, we develop an evaluation framework based on necessary conditions: calibration against verifiable proxies, sensitivity to evidence, and alignment with human expert judgment. We evaluate in the domain of AI-augmented cybersecurity risk, using three capability benchmarks and independent human elicitation studies. LLM panels achieve strong correlations with benchmark ground truth (Pearson r=0.87-0.95), improve systematically as evidence is added, and align with human expert panels - in one comparison, closer to a human panel than the two human panels are to each other. This demonstrates that LLM-based elicitation can extend structured expert judgment to settings where traditional methods are infeasible, reducing elicitation time from months to minutes.