Learning the Value Systems of Societies with Preference-based Multi-objective Reinforcement Learning
作者: Andrés Holgado-Sánchez, Peter Vamplew, Richard Dazeley, Sascha Ossowski, Holger Billhardt
分类: cs.AI, cs.CY, cs.LG
发布日期: 2026-02-09
备注: 18 pages, 3 figures. To be published in proceedings of the 25th International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS 2026). This is a full version that includes the supplementary material
DOI: 10.65109/NLVD8864
💡 一句话要点
提出基于偏好的多目标强化学习,用于学习社会价值体系
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标强化学习 偏好学习 价值对齐 社会价值体系 用户建模
📋 核心要点
- 现有方法在序贯决策中缺乏对社会群体价值体系的建模能力,且依赖手动特征或缺乏可解释性。
- 该论文提出基于聚类和偏好学习的多目标强化学习方法,用于学习社会价值对齐模型和价值体系。
- 实验表明,该方法在具有人类价值观的MDP环境中,能够有效地学习并适应不同的用户偏好。
📝 摘要(中文)
价值感知AI应能识别人的价值观并适应不同用户的价值体系(基于价值的偏好)。这需要对价值观进行操作化,但容易出现规范错误。价值观的社会属性要求其表示能够适应多个用户,同时价值体系是多样化的,但在群体中又表现出模式。在序贯决策中,已经有人尝试从不同智能体的演示中进行个性化,以适应不同的目标或价值观。然而,这些方法需要手动设计的特征,或者缺乏基于价值的可解释性和/或对不同用户偏好的适应性。我们提出了算法,用于在马尔可夫决策过程(MDP)中学习社会智能体的价值对齐和价值体系模型,基于聚类和基于偏好的多目标强化学习(PbMORL)。我们共同学习社会衍生的价值对齐模型(基础)和一组价值体系,这些价值体系简洁地代表了社会中不同的用户群体(集群)。每个集群由一个代表其成员基于价值的偏好的价值体系和一个近似帕累托最优策略组成,该策略反映了与该价值体系对齐的行为。我们在两个具有人类价值观的MDP上,针对最先进的PbMORL算法和基线评估了我们的方法。
🔬 方法详解
问题定义:论文旨在解决如何让AI系统理解和适应不同社会群体的价值体系的问题。现有方法,如直接学习个体偏好,无法有效捕捉社会群体的共性价值,且容易受到个体差异的干扰。此外,手动设计特征或缺乏价值解释性限制了模型的泛化能力和可信度。
核心思路:论文的核心思路是将社会价值体系的学习分解为两个关键步骤:首先,通过聚类算法将用户划分为不同的群体,每个群体代表一种特定的价值体系。然后,利用基于偏好的多目标强化学习(PbMORL)方法,为每个群体学习一个帕累托最优策略,该策略能够最大化群体所代表的价值偏好。
技术框架:整体框架包含以下几个主要模块:1) 用户数据收集:收集用户在MDP环境中的行为数据,包括状态、动作和奖励。2) 用户聚类:使用聚类算法(如k-means)将用户划分为不同的群体,每个群体代表一种价值体系。3) 价值体系学习:为每个群体学习一个价值体系,该价值体系定义了群体对不同目标的偏好。4) 策略学习:使用PbMORL算法,为每个群体学习一个帕累托最优策略,该策略能够最大化群体所代表的价值偏好。
关键创新:该论文的关键创新在于将聚类算法与PbMORL相结合,从而能够有效地学习社会群体的价值体系。与现有方法相比,该方法能够更好地捕捉社会群体的共性价值,并能够生成具有价值解释性的策略。此外,该方法不需要手动设计特征,具有更好的泛化能力。
关键设计:论文中,聚类算法的选择会影响最终的价值体系划分。PbMORL算法需要定义目标函数和偏好关系。目标函数通常与MDP环境中的奖励相关,偏好关系则由价值体系决定。此外,策略学习过程中需要平衡不同目标之间的权衡,以获得帕累托最优策略。
🖼️ 关键图片
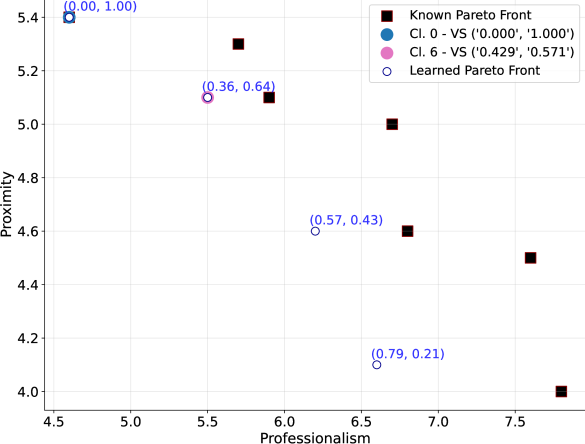

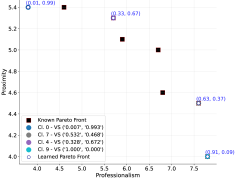
📊 实验亮点
该论文在两个具有人类价值观的MDP环境中进行了实验,结果表明,该方法能够有效地学习社会群体的价值体系,并生成具有价值解释性的策略。与最先进的PbMORL算法和基线方法相比,该方法在学习效率和策略质量方面均有显著提升。具体性能数据未知,但论文强调了其方法在适应不同用户偏好方面的优势。
🎯 应用场景
该研究成果可应用于人机协作、推荐系统、社交机器人等领域。例如,在人机协作中,AI系统可以根据用户的价值体系,提供个性化的建议和帮助。在推荐系统中,可以根据用户的价值偏好,推荐更符合其价值观的内容。在社交机器人中,可以根据不同社会群体的价值体系,进行更自然和有效的交流。
📄 摘要(原文)
Value-aware AI should recognise human values and adapt to the value systems (value-based preferences) of different users. This requires operationalization of values, which can be prone to misspecification. The social nature of values demands their representation to adhere to multiple users while value systems are diverse, yet exhibit patterns among groups. In sequential decision making, efforts have been made towards personalization for different goals or values from demonstrations of diverse agents. However, these approaches demand manually designed features or lack value-based interpretability and/or adaptability to diverse user preferences. We propose algorithms for learning models of value alignment and value systems for a society of agents in Markov Decision Processes (MDPs), based on clustering and preference-based multi-objective reinforcement learning (PbMORL). We jointly learn socially-derived value alignment models (groundings) and a set of value systems that concisely represent different groups of users (clusters) in a society. Each cluster consists of a value system representing the value-based preferences of its members and an approximately Pareto-optimal policy that reflects behaviours aligned with this value system. We evaluate our method against a state-of-the-art PbMORL algorithm and baselines on two MDPs with human values.