Finite-State Controllers for (Hidden-Model) POMDPs using Deep Reinforcement Learning
作者: David Hudák, Maris F. L. Galesloot, Martin Tappler, Martin Kurečka, Nils Jansen, Milan Češka
分类: cs.AI
发布日期: 2026-02-09
备注: 17 pages (8 main paper, 2 references, 7 appendix). 3 figures in the main paper, 3 figures in the appendix. Accepted AAMAS'26 submission
💡 一句话要点
提出Lexpop框架,利用深度强化学习和有限状态控制器解决(隐模型)POMDP问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: POMDP 隐模型POMDP 深度强化学习 有限状态控制器 策略提取
📋 核心要点
- 现有的POMDP求解器在可扩展性方面存在局限性,尤其是在需要跨多个POMDP保持策略鲁棒性的场景下。
- Lexpop框架的核心思想是先用深度强化学习训练神经策略,再提取有限状态控制器来模仿该策略,以便进行形式化验证和性能保证。
- 实验结果表明,Lexpop在大型状态空间问题上优于当前最先进的POMDP和HM-POMDP求解器,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Lexpop的框架,用于解决部分可观测马尔可夫决策过程(POMDPs)。Lexpop框架首先利用深度强化学习训练一个由循环神经网络表示的神经策略,然后通过高效的提取方法构建一个模仿该神经策略的有限状态控制器。与神经策略不同,这种控制器可以进行形式化评估,从而提供性能保证。此外,本文还将Lexpop扩展到隐模型POMDPs(HM-POMDPs),该模型描述了有限的POMDP集合,并为每个提取的控制器关联其最坏情况的POMDP。通过一组这样的POMDP,迭代地训练一个鲁棒的神经策略,并提取一个鲁棒的控制器。实验结果表明,在具有大型状态空间的问题上,Lexpop优于当前最先进的POMDP和HM-POMDP求解器。
🔬 方法详解
问题定义:论文旨在解决部分可观测马尔可夫决策过程(POMDPs)和隐模型POMDPs(HM-POMDPs)的求解问题。现有POMDP求解器在处理大规模状态空间时面临可扩展性挑战,并且难以保证策略在多个POMDP上的鲁棒性。传统的基于值迭代的方法计算复杂度高,难以应用于实际场景。
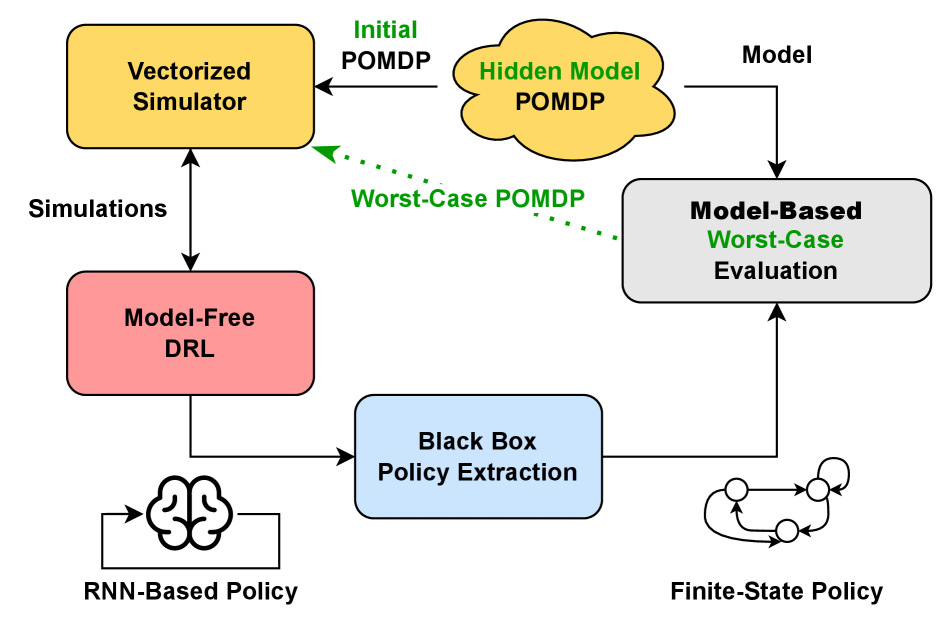
核心思路:论文的核心思路是结合深度强化学习的强大表示能力和有限状态控制器的可验证性。首先,利用深度强化学习训练一个神经策略,使其能够处理POMDP中的部分可观测性。然后,通过策略提取方法,将神经策略转化为一个有限状态控制器,该控制器易于分析和验证,并能提供性能保证。
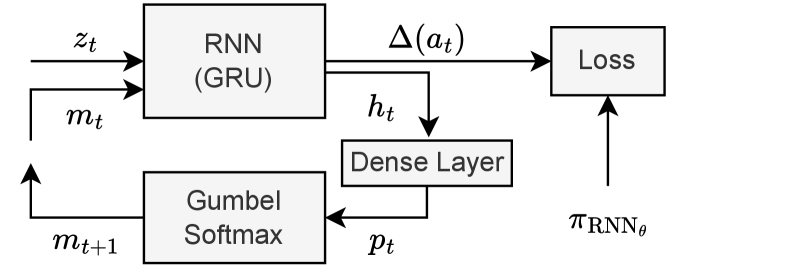
技术框架:Lexpop框架包含两个主要阶段:神经策略训练和控制器提取。在神经策略训练阶段,使用循环神经网络(RNN)作为策略网络,通过强化学习算法(如PPO或DQN)进行训练。在控制器提取阶段,利用策略提取算法,将训练好的神经策略转化为一个有限状态控制器。对于HM-POMDPs,Lexpop采用迭代训练的方式,每次迭代都选择当前控制器最坏情况下的POMDP进行训练,从而提高策略的鲁棒性。
关键创新:Lexpop的关键创新在于结合了深度强化学习和有限状态控制器,既利用了深度学习的强大表示能力,又保证了策略的可验证性。此外,针对HM-POMDPs的迭代训练方法,能够有效地提高策略的鲁棒性。
关键设计:在神经策略训练阶段,RNN的网络结构需要根据具体问题进行设计,常用的结构包括LSTM和GRU。损失函数通常采用策略梯度方法中的损失函数,如PPO的裁剪损失。控制器提取算法的选择也很重要,需要根据神经策略的复杂度和控制器的规模进行权衡。对于HM-POMDPs,需要设计合适的算法来寻找每个控制器最坏情况下的POMDP。
🖼️ 关键图片
📊 实验亮点
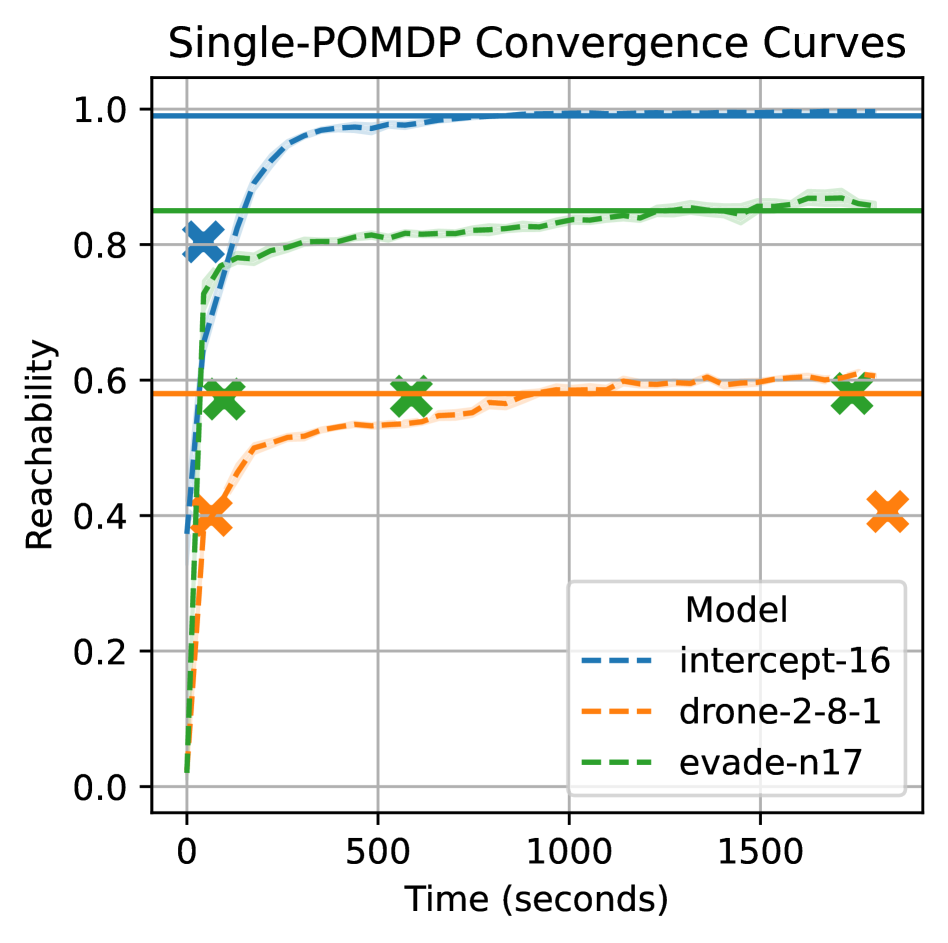
实验结果表明,Lexpop在具有大型状态空间的问题上优于当前最先进的POMDP和HM-POMDP求解器。具体而言,Lexpop在某些测试环境中能够达到比现有方法更高的平均奖励,并且能够提取出具有可验证性能保证的有限状态控制器。在HM-POMDPs问题上,Lexpop能够有效地提高策略的鲁棒性,使其在不同的POMDP实例中都能保持较好的性能。
🎯 应用场景
该研究成果可应用于机器人导航、对话系统、自动驾驶等领域,尤其是在环境状态不确定或存在多个潜在环境模型的场景下。通过Lexpop框架,可以训练出既具有高性能又具有可验证性的控制策略,从而提高系统的安全性和可靠性。未来的研究可以进一步探索更高效的控制器提取算法和更鲁棒的神经策略训练方法。
📄 摘要(原文)
Solving partially observable Markov decision processes (POMDPs) requires computing policies under imperfect state information. Despite recent advances, the scalability of existing POMDP solvers remains limited. Moreover, many settings require a policy that is robust across multiple POMDPs, further aggravating the scalability issue. We propose the Lexpop framework for POMDP solving. Lexpop (1) employs deep reinforcement learning to train a neural policy, represented by a recurrent neural network, and (2) constructs a finite-state controller mimicking the neural policy through efficient extraction methods. Crucially, unlike neural policies, such controllers can be formally evaluated, providing performance guarantees. We extend Lexpop to compute robust policies for hidden-model POMDPs (HM-POMDPs), which describe finite sets of POMDPs. We associate every extracted controller with its worst-case POMDP. Using a set of such POMDPs, we iteratively train a robust neural policy and consequently extract a robust controller. Our experiments show that on problems with large state spaces, Lexpop outperforms state-of-the-art solvers for POMDPs as well as HM-POMDPs.