6G-Bench: An Open Benchmark for Semantic Communication and Network-Level Reasoning with Foundation Models in AI-Native 6G Networks
作者: Mohamed Amine Ferrag, Abderrahmane Lakas, Merouane Debbah
分类: cs.NI, cs.AI
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
6G-Bench:面向AI原生6G网络中语义通信和网络级推理的开放基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 6G网络 语义通信 网络级推理 基准测试 AI原生网络
📋 核心要点
- 现有6G网络缺乏统一的基准测试,难以评估语义通信和网络级推理能力,阻碍了AI原生6G网络的发展。
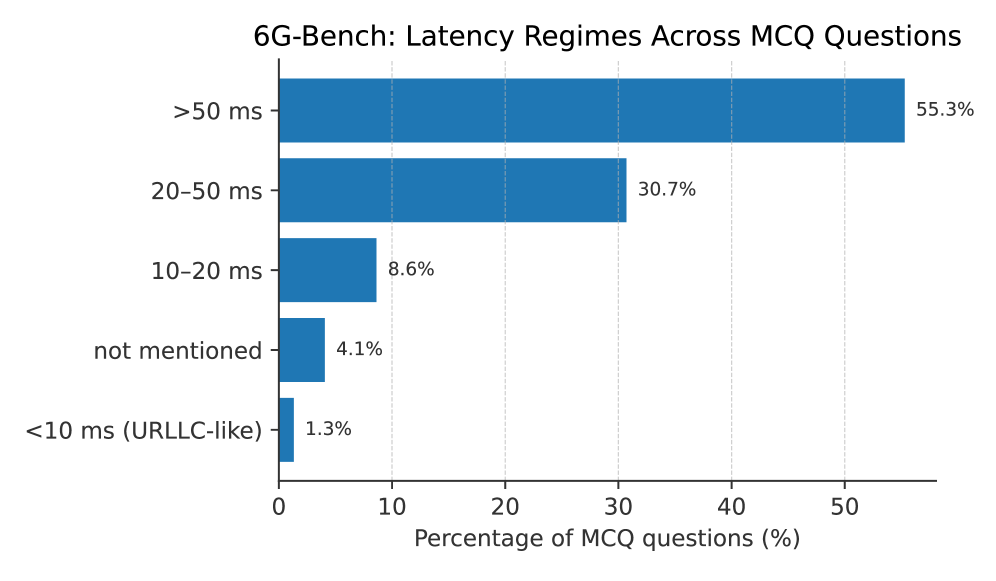
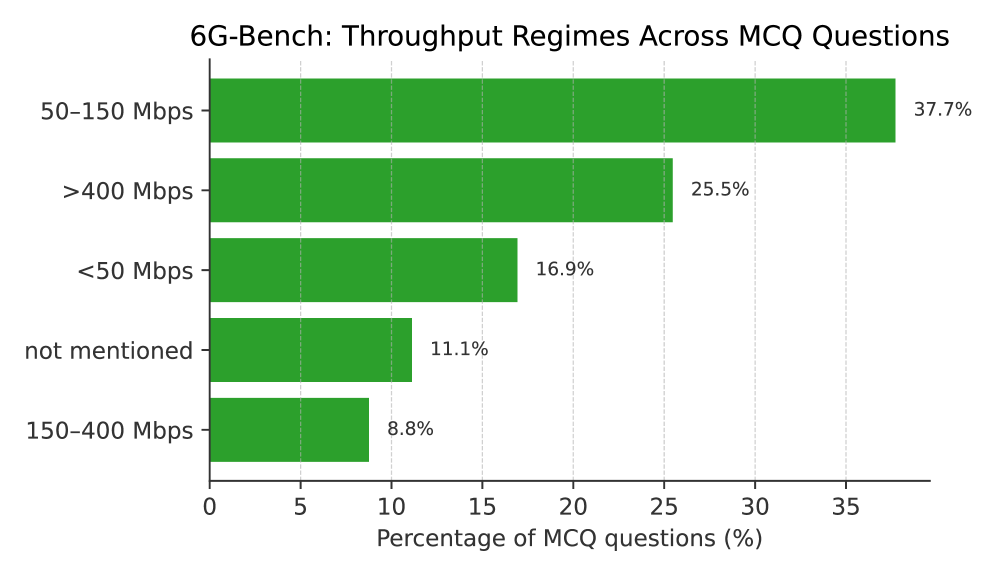
- 6G-Bench通过定义30个决策任务,构建包含3722个高质量问题的基准数据集,用于评估和提升6G网络中的AI推理能力。
- 实验评估了22个基础模型,结果表明模型在语义推理能力上存在显著差异,为未来模型优化提供了方向。
📝 摘要(中文)
本文介绍了6G-Bench,一个开放的基准测试,用于评估AI原生6G网络中的语义通信和网络级推理。6G-Bench定义了一个包含30个决策任务(T1-T30)的分类体系,这些任务来自3GPP、IETF、ETSI、ITU-T和O-RAN联盟中正在进行的6G和AI代理标准化活动,并将它们组织成五个与标准化对齐的能力类别。从113,475个场景开始,我们使用任务条件提示生成了一个包含10,000个非常困难的多项选择题的平衡池,这些提示强制执行不确定性下的多步定量推理以及多轮视野上的最坏情况后悔最小化。经过自动过滤和专家人工验证后,保留了3,722个问题作为高置信度评估集,而完整的问题池被发布以支持6G专用模型的训练和微调。使用6G-Bench,我们评估了22个基础模型,涵盖密集和混合专家架构、短上下文和长上下文设计(高达100万个token)以及开放权重和专有系统。在所有模型中,确定性单次精度(pass@1)的范围从0.22到0.82,突出了语义推理能力的显着差异。领先的模型实现了0.87-0.89范围内的意图和策略推理精度,而对推理密集型任务的选择性鲁棒性分析显示pass@5值范围从0.20到0.91。为了支持开放科学和可重复性,我们在GitHub上发布了6G-Bench数据集。
🔬 方法详解
问题定义:现有6G网络缺乏一个统一的、标准化的基准测试来评估语义通信和网络级推理能力。这使得研究人员难以比较不同算法的性能,也阻碍了AI技术在6G网络中的有效应用。现有方法难以模拟真实6G网络环境下的复杂决策场景,无法全面评估模型的推理能力。
核心思路:6G-Bench的核心思路是构建一个与6G标准化活动对齐的、包含多样化决策任务的基准数据集。通过任务条件提示生成高质量的多项选择题,这些问题需要模型进行多步定量推理和最坏情况后悔最小化。这样设计的目的是为了全面评估模型在不确定性环境下的推理能力和鲁棒性。
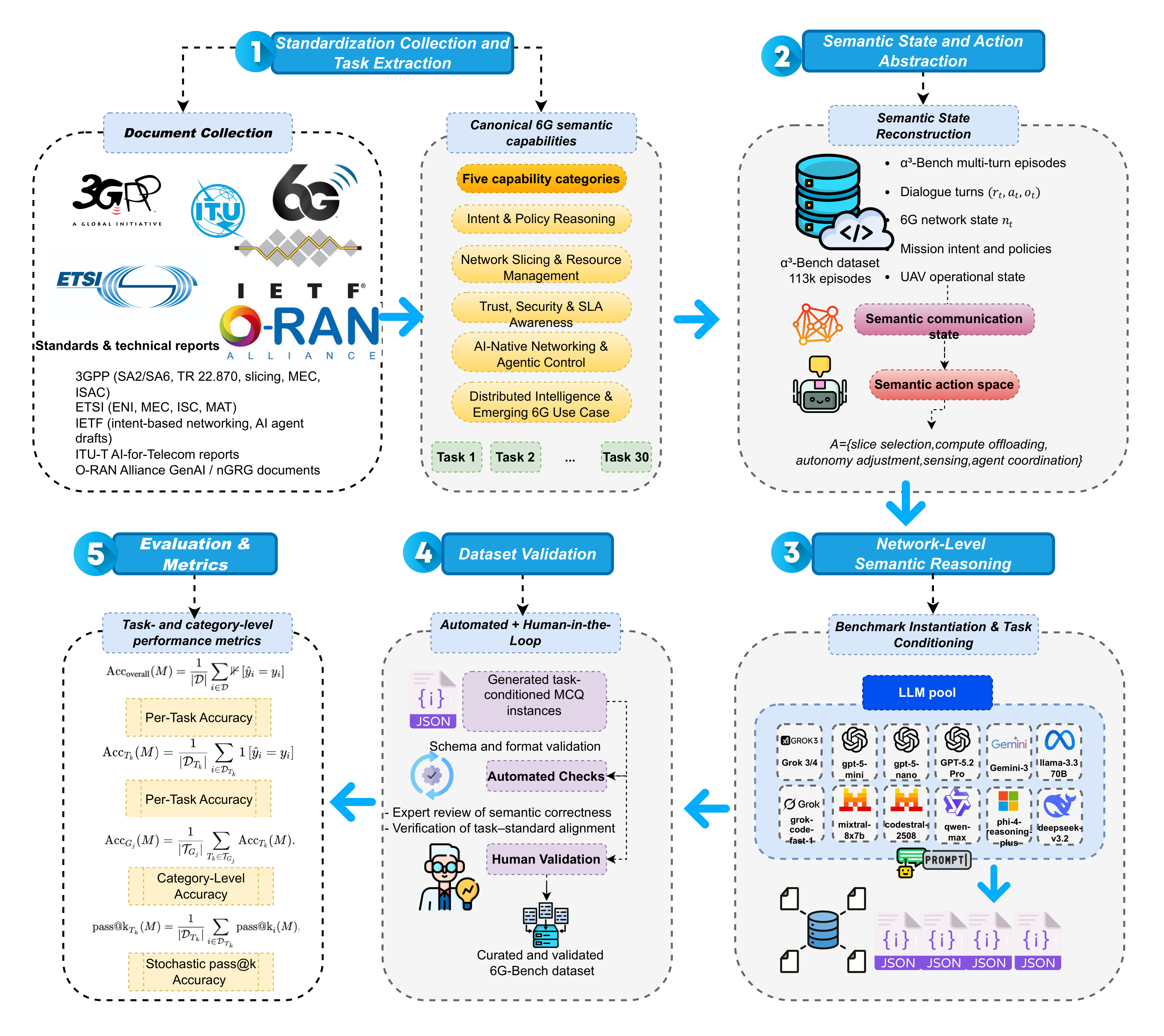
技术框架:6G-Bench的整体框架包括以下几个主要阶段:1) 定义30个决策任务,这些任务来自3GPP、IETF等标准化组织。2) 基于这些任务,生成包含113,475个场景的数据池。3) 使用任务条件提示,从数据池中生成10,000个多项选择题。4) 通过自动过滤和人工验证,筛选出3,722个高质量问题作为评估集。5) 使用评估集评估22个基础模型的性能。
关键创新:6G-Bench的关键创新在于其任务定义的标准化对齐和问题生成方式。通过与6G标准化活动对齐,确保了基准测试的实际意义和应用价值。使用任务条件提示生成问题,能够有效地模拟真实6G网络环境下的复杂决策场景,并评估模型的推理能力。
关键设计:6G-Bench的关键设计包括:1) 任务选择:选择30个来自不同标准化组织的决策任务,覆盖了6G网络中的关键应用场景。2) 问题生成:使用任务条件提示,生成需要多步推理和最坏情况后悔最小化的多项选择题。3) 数据过滤:采用自动过滤和人工验证相结合的方式,确保数据集的质量和可靠性。
🖼️ 关键图片
📊 实验亮点
6G-Bench评估了22个基础模型,结果显示模型在确定性单次精度(pass@1)上的范围从0.22到0.82,表明模型在语义推理能力上存在显著差异。领先的模型实现了0.87-0.89范围内的意图和策略推理精度。对推理密集型任务的选择性鲁棒性分析显示pass@5值范围从0.20到0.91,突出了模型在不同任务上的性能差异。
🎯 应用场景
6G-Bench可用于评估和提升AI原生6G网络中的语义通信和网络级推理能力。它可以帮助研究人员开发更智能、更高效的6G网络算法和模型,从而提高网络性能、降低运营成本,并支持更广泛的应用场景,如自动驾驶、智能制造和虚拟现实。
📄 摘要(原文)
This paper introduces 6G-Bench, an open benchmark for evaluating semantic communication and network-level reasoning in AI-native 6G networks. 6G-Bench defines a taxonomy of 30 decision-making tasks (T1--T30) extracted from ongoing 6G and AI-agent standardization activities in 3GPP, IETF, ETSI, ITU-T, and the O-RAN Alliance, and organizes them into five standardization-aligned capability categories. Starting from 113,475 scenarios, we generate a balanced pool of 10,000 very-hard multiple-choice questions using task-conditioned prompts that enforce multi-step quantitative reasoning under uncertainty and worst-case regret minimization over multi-turn horizons. After automated filtering and expert human validation, 3,722 questions are retained as a high-confidence evaluation set, while the full pool is released to support training and fine-tuning of 6G-specialized models. Using 6G-Bench, we evaluate 22 foundation models spanning dense and mixture-of-experts architectures, short- and long-context designs (up to 1M tokens), and both open-weight and proprietary systems. Across models, deterministic single-shot accuracy (pass@1) spans a wide range from 0.22 to 0.82, highlighting substantial variation in semantic reasoning capability. Leading models achieve intent and policy reasoning accuracy in the range 0.87--0.89, while selective robustness analysis on reasoning-intensive tasks shows pass@5 values ranging from 0.20 to 0.91. To support open science and reproducibility, we release the 6G-Bench dataset on GitHub: https://github.com/maferrag/6G-Bench