An Attention Mechanism for Robust Multimodal Integration in a Global Workspace Architecture
作者: Roland Bertin-Johannet, Lara Scipio, Leopold Maytié, Rufin VanRullen
分类: cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出一种基于注意力机制的全局工作空间架构,提升多模态融合的噪声鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全局工作空间 注意力机制 多模态融合 噪声鲁棒性 跨模态学习
📋 核心要点
- 现有的全局工作空间(GWT)多模态实现缺乏对模态选择的有效注意力机制,限制了其在噪声环境下的性能。
- 论文提出一种顶向下注意力机制,用于在GWT中选择相关模态,从而提高系统对噪声的鲁棒性。
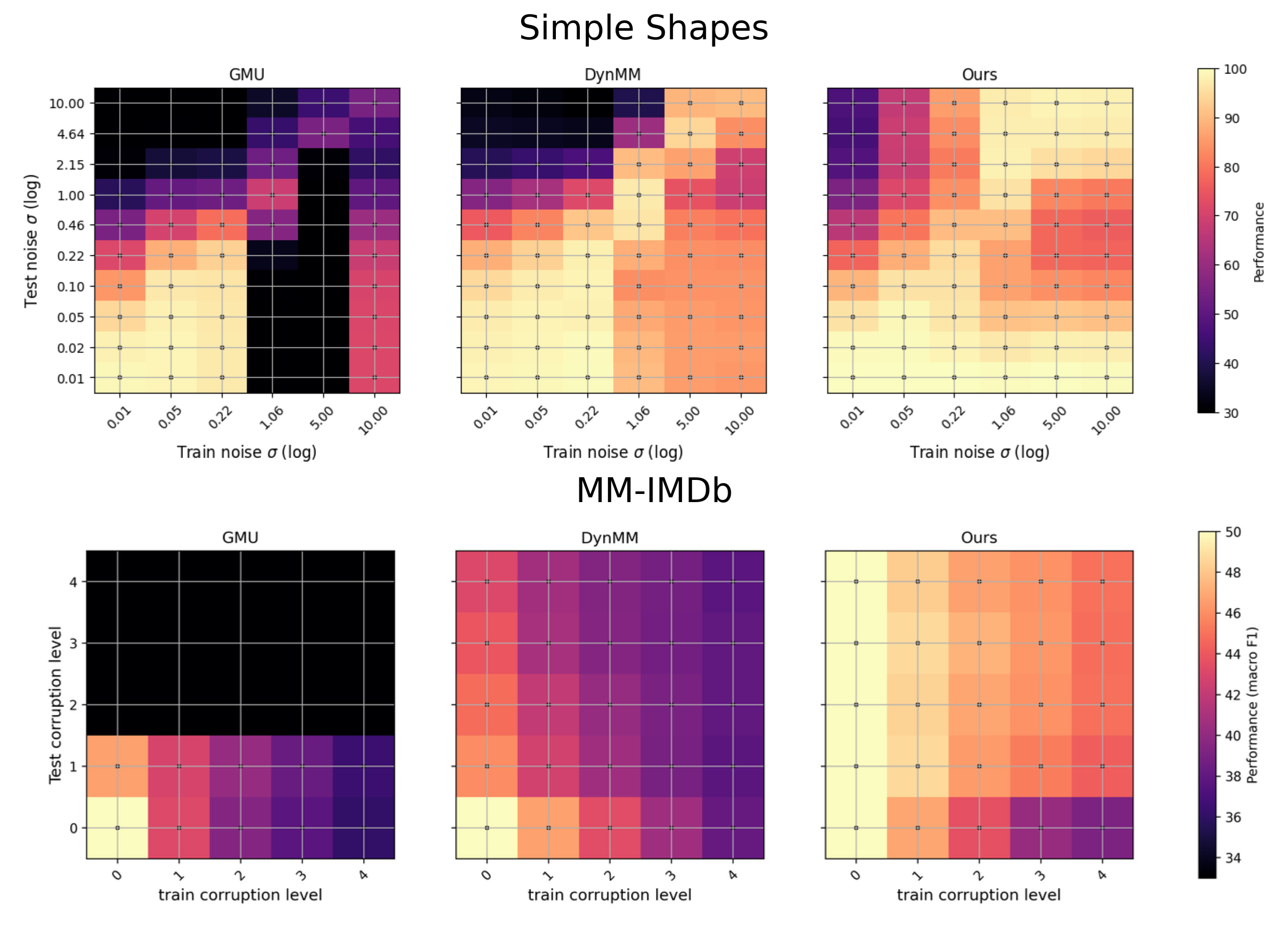
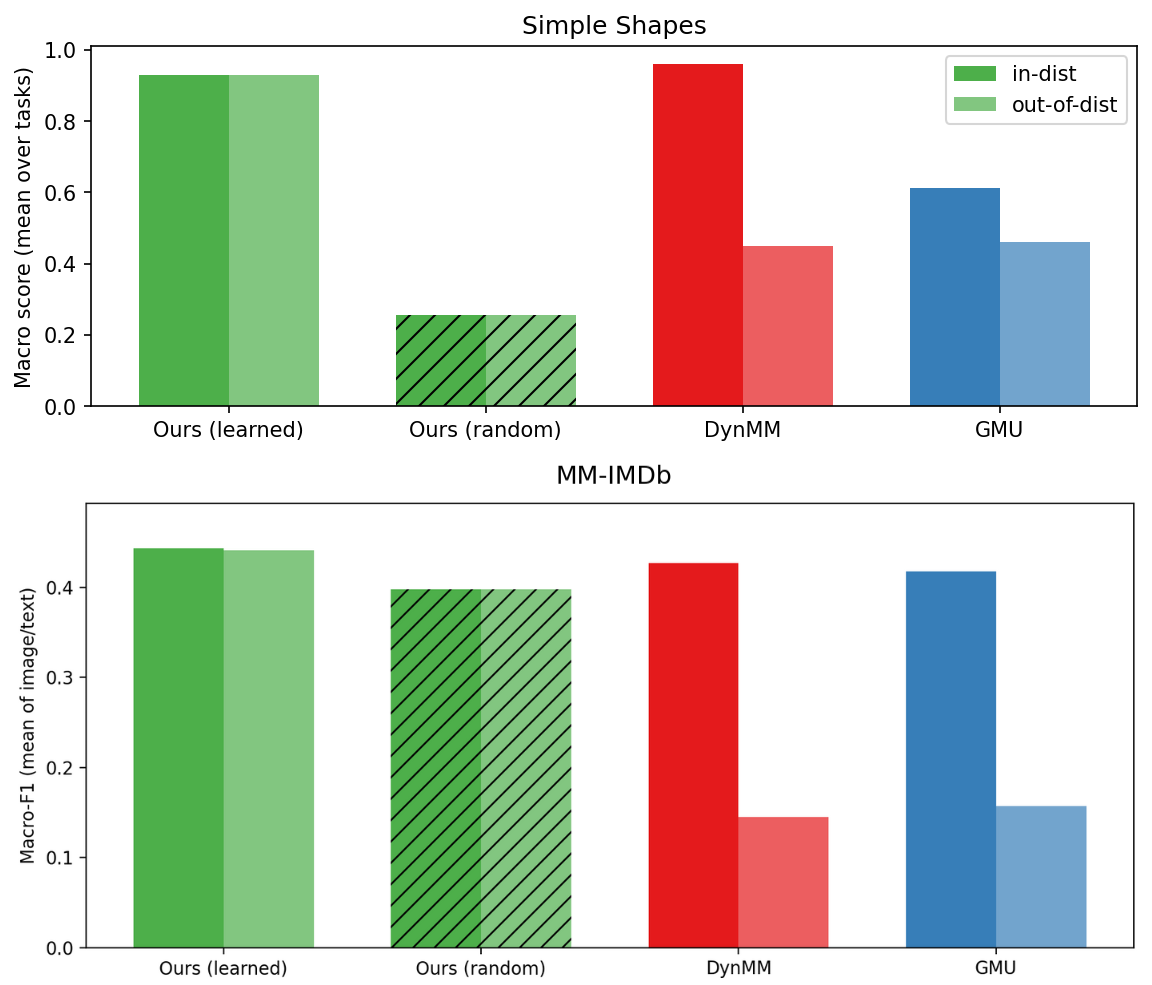
- 实验表明,该机制在多模态数据集上提升了噪声鲁棒性,并展现出优于现有模型的跨任务和跨模态泛化能力。
📝 摘要(中文)
本文提出并评估了一种顶向下注意力机制,用于在全局工作空间中选择模态,旨在提升多模态融合系统的噪声鲁棒性。该机制基于认知神经科学中的全局工作空间理论(GWT),该理论认为灵活的认知能力源于多模态整合系统中相关模态的注意力选择。实验结果表明,该注意力机制在Simple Shapes和MM-IMDb 1.0两个复杂度递增的多模态数据集上,提高了全局工作空间系统的噪声鲁棒性。此外,该机制还展现了多种跨任务和跨模态的泛化能力,这是现有文献中的多模态注意力模型所不具备的。在MM-IMDb 1.0基准测试中,该注意力机制使得全局工作空间系统具有与当前最佳方法相媲美的性能。
🔬 方法详解
问题定义:论文旨在解决多模态融合中,由于噪声模态的存在而导致系统性能下降的问题。现有的全局工作空间架构在处理多模态数据时,缺乏有效的注意力机制来选择和加权不同的模态,使得系统容易受到噪声模态的干扰,降低了整体的鲁棒性和泛化能力。
核心思路:论文的核心思路是引入一种顶向下(top-down)的注意力机制,该机制能够根据任务需求和模态的重要性,动态地选择和加权不同的模态。通过这种方式,系统可以更加关注有用的模态,抑制噪声模态的影响,从而提高整体的性能和鲁棒性。这种顶向下注意力机制模拟了认知神经科学中全局工作空间理论中注意力选择的过程。
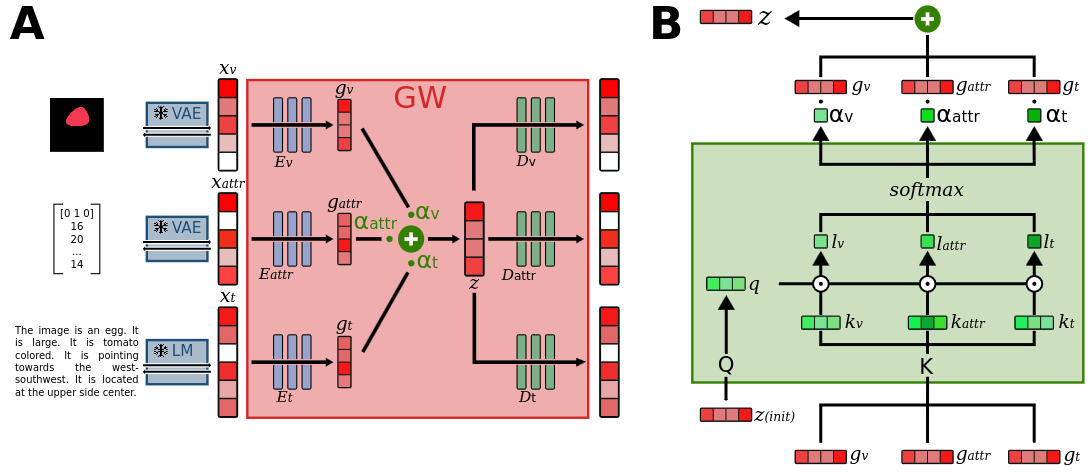
技术框架:该全局工作空间架构包含多个模态输入通道,每个通道对应一种模态的数据。这些模态数据被输入到各自的编码器中,生成模态表示。然后,顶向下注意力机制根据任务需求,对这些模态表示进行加权融合,得到一个全局表示。最后,全局表示被输入到解码器中,生成最终的输出结果。整个框架通过端到端的方式进行训练。
关键创新:论文的关键创新在于提出了一种适用于全局工作空间架构的顶向下注意力机制。与传统的注意力机制不同,该机制更加关注模态之间的关系和任务需求,能够更加有效地选择和加权不同的模态。此外,该机制还具有良好的跨任务和跨模态泛化能力,能够适应不同的任务和模态组合。
关键设计:注意力机制的具体实现采用了一个多层感知机(MLP),该MLP以任务相关的上下文向量作为输入,输出每个模态的注意力权重。这些权重被用于对模态表示进行加权融合。损失函数包括任务相关的损失和注意力正则化损失,其中注意力正则化损失用于鼓励注意力权重的稀疏性,从而提高模型的解释性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该注意力机制在Simple Shapes和MM-IMDb 1.0两个数据集上均取得了显著的性能提升。在MM-IMDb 1.0数据集上,该方法与现有最佳方法相比具有竞争力,并且展现出更强的跨任务和跨模态泛化能力。具体而言,该方法在噪声环境下的性能提升尤为明显,证明了其良好的噪声鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要多模态信息融合的场景,例如视频理解、语音识别、机器人感知等。通过引入注意力机制,可以提高系统在复杂环境下的鲁棒性和准确性,例如在嘈杂环境中进行语音识别,或者在光照条件不佳的情况下进行图像识别。该研究也有助于开发更智能、更可靠的人工智能系统。
📄 摘要(原文)
Global Workspace Theory (GWT), inspired by cognitive neuroscience, posits that flexible cognition could arise via the attentional selection of a relevant subset of modalities within a multimodal integration system. This cognitive framework can inspire novel computational architectures for multimodal integration. Indeed, recent implementations of GWT have explored its multimodal representation capabilities, but the related attention mechanisms remain understudied. Here, we propose and evaluate a top-down attention mechanism to select modalities inside a global workspace. First, we demonstrate that our attention mechanism improves noise robustness of a global workspace system on two multimodal datasets of increasing complexity: Simple Shapes and MM-IMDb 1.0. Second, we highlight various cross-task and cross-modality generalization capabilities that are not shared by multimodal attention models from the literature. Comparing against existing baselines on the MM-IMDb 1.0 benchmark, we find our attention mechanism makes the global workspace competitive with the state of the art.