Reinforcement Inference: Leveraging Uncertainty for Self-Correcting Language Model Reasoning
作者: Xinhai Sun
分类: cs.AI, cs.LG
发布日期: 2026-02-09
💡 一句话要点
提出Reinforcement Inference,利用不确定性提升语言模型推理能力,无需重训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理 不确定性 熵 自纠正 零样本学习 推理时干预
📋 核心要点
- 现有LLM推理常采用一次性贪婪策略,易受内部模糊性影响,导致性能受限。
- Reinforcement Inference利用模型自身不确定性,选择性地进行二次推理,提升性能。
- 实验表明,该方法在MMLU-Pro上显著提升准确率,且计算成本相对较低。
📝 摘要(中文)
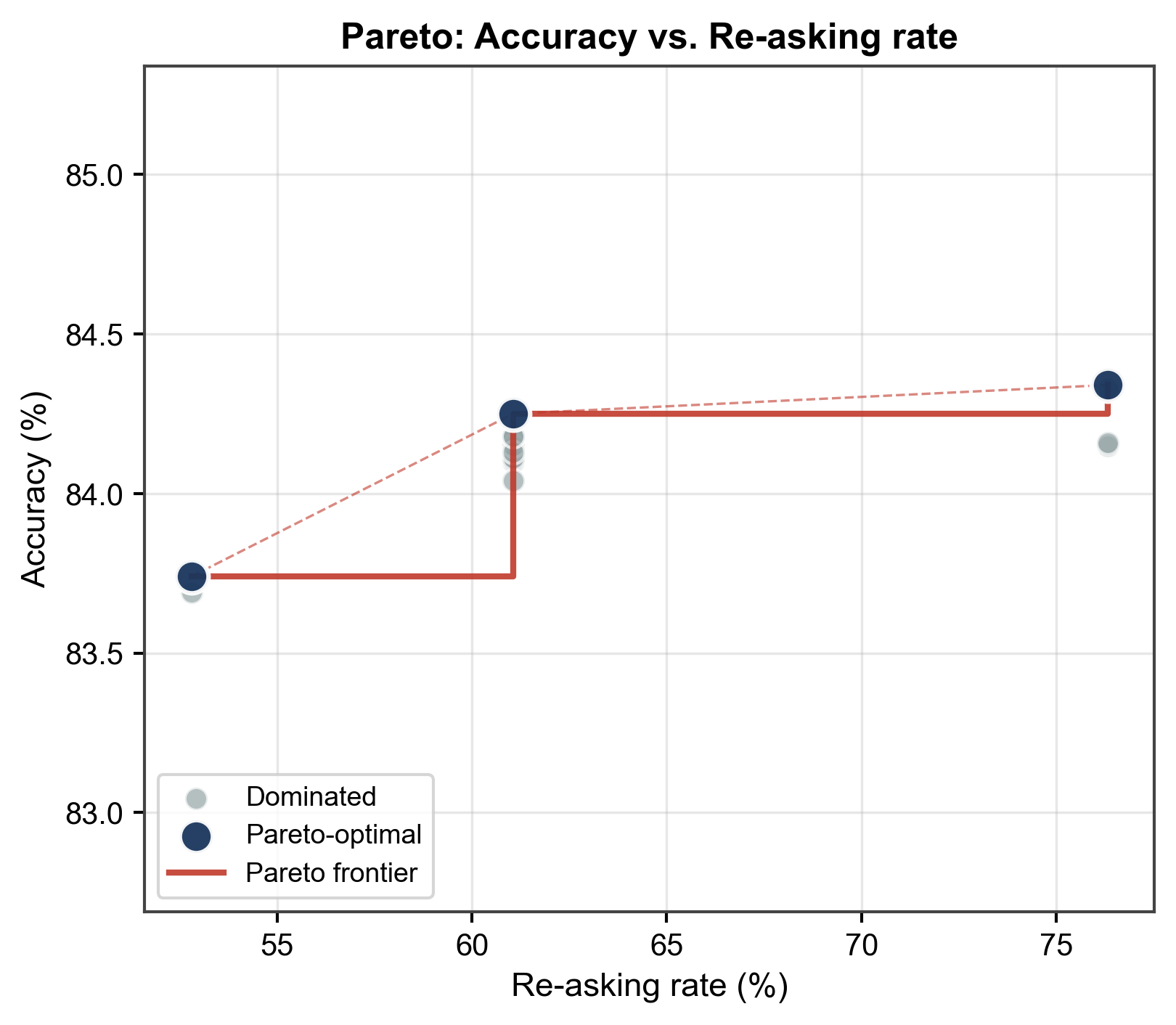
现代大型语言模型(LLMs)通常在“一次性、贪婪”的推理协议下进行评估和部署,尤其是在需要确定性行为的专业环境中。这种方式会系统性地低估固定模型的真实能力:许多错误并非源于知识缺失,而是源于内部模糊性下的过早承诺。我们引入了Reinforcement Inference,这是一种感知熵的推理时控制策略,它利用模型自身的不确定性来选择性地调用第二次、更审慎的推理尝试,从而在不进行任何重新训练的情况下实现更强的性能。在跨越14个学科的12,032个MMLU-Pro问题上,使用DeepSeek-v3.2在零样本设置中进行确定性解码,Reinforcement Inference将准确率从60.72%提高到84.03%,而仅产生61.06%的额外推理调用。100%重新提问的消融实验达到84.35%,表明感知不确定性的选择捕获了大部分可实现的改进,而计算量大大减少。此外,仅使用prompt的消融实验表现不如基线,表明收益不能仅用通用的“你的输出具有高熵,逐步思考”提示来解释。除了提供实用的推理时升级之外,我们的结果还提出了一种更广泛的“感知熵”范例,用于测量和扩展模型能力:由于现代基于解码器的模型以自回归方式生成输出,因此熵和相关的置信度度量自然而然地成为生成过程中的一流控制信号。由此产生的一次性贪婪推理与不确定性条件下的审议之间的差距为LLM的潜在推理范围提供了一个诊断视角,并激发了未来明确约束正确性-置信度对齐的训练目标。
🔬 方法详解
问题定义:现有的大型语言模型在推理时,通常采用一次性、贪婪的解码策略。这种策略容易受到模型内部不确定性的影响,导致过早地做出错误的决策,从而影响最终的推理结果。尤其是在需要高可靠性的专业场景下,这种问题更加突出。现有方法缺乏对模型自身不确定性的有效利用,无法在推理过程中进行自我修正。
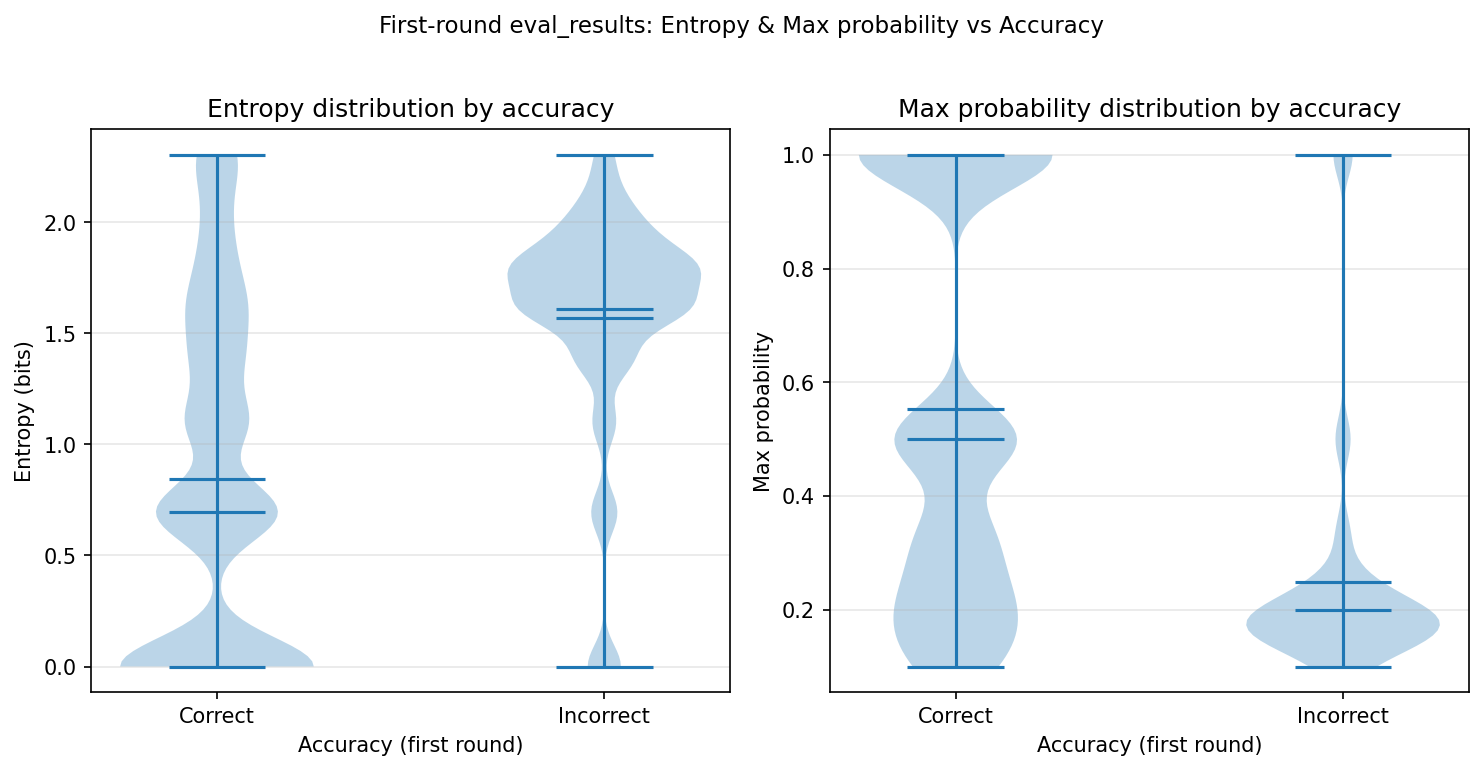
核心思路:Reinforcement Inference的核心思路是利用模型自身输出的熵作为不确定性的度量。当模型输出的熵较高时,表明模型对当前决策的置信度较低,存在较大的不确定性。此时,Reinforcement Inference会触发第二次推理尝试,让模型重新审视之前的决策,从而有机会纠正错误。
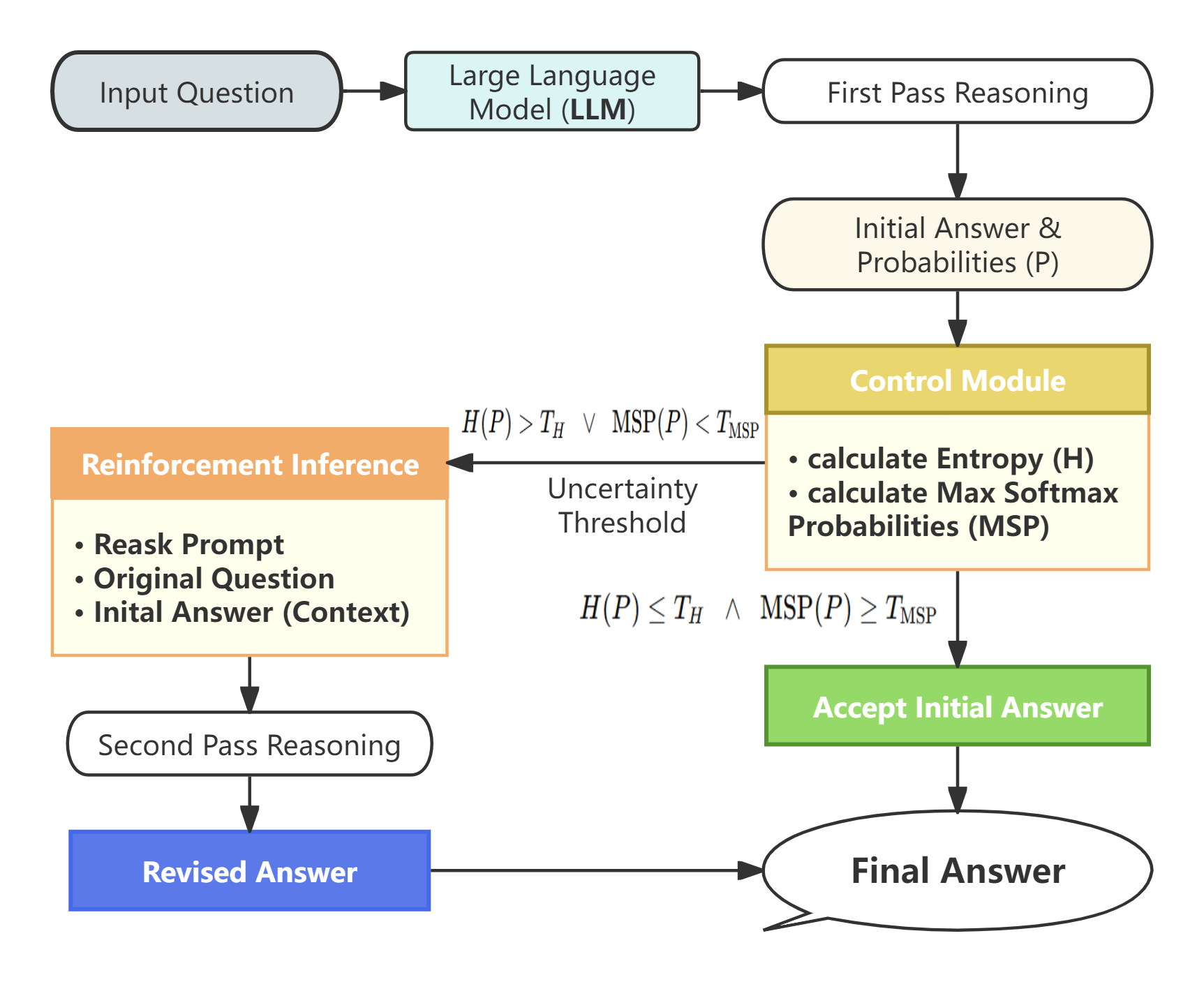
技术框架:Reinforcement Inference的整体框架如下: 1. 初始推理:使用标准的一次性、贪婪解码策略生成初始输出。 2. 不确定性评估:计算初始输出的熵,作为模型不确定性的度量。 3. 重推理决策:如果熵高于预设阈值,则触发第二次推理尝试。 4. 二次推理:使用相同的模型和输入,进行第二次推理,生成新的输出。 5. 结果选择:选择两次推理中置信度更高的结果作为最终输出。
关键创新:Reinforcement Inference的关键创新在于: 1. 熵感知推理:首次将模型自身输出的熵作为推理过程中的控制信号,实现了对不确定性的有效利用。 2. 无需重训练:该方法无需对模型进行任何重训练,即可显著提升推理性能,具有很强的实用性。 3. 选择性重推理:通过不确定性评估,选择性地进行二次推理,避免了不必要的计算开销。
关键设计:Reinforcement Inference的关键设计包括: 1. 熵的计算方式:论文采用标准的信息熵计算公式,对模型输出的概率分布进行计算。 2. 熵阈值的设定:熵阈值的设定需要根据具体的任务和模型进行调整,以平衡性能提升和计算开销。 3. 结果选择策略:论文选择两次推理中置信度更高的结果作为最终输出,置信度可以通过模型输出的概率分布进行估计。
🖼️ 关键图片
📊 实验亮点
在MMLU-Pro数据集上,Reinforcement Inference将DeepSeek-v3.2的零样本准确率从60.72%提升至84.03%,仅增加了61.06%的推理调用。与100%重问的消融实验相比,该方法在计算成本更低的情况下,获得了接近的性能提升,验证了不确定性感知选择的有效性。
🎯 应用场景
Reinforcement Inference可广泛应用于需要高可靠性的大语言模型应用场景,如医疗诊断、金融分析、法律咨询等。该方法无需重训练,易于部署,能够有效提升模型在复杂推理任务中的准确性和可靠性,降低错误风险,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
Modern large language models (LLMs) are often evaluated and deployed under a \emph{one-shot, greedy} inference protocol, especially in professional settings that require deterministic behavior. This regime can systematically under-estimate a fixed model's true capability: many errors arise not from missing knowledge, but from premature commitment under internal ambiguity. We introduce \emph{Reinforcement Inference}, an entropy-aware inference-time control strategy that uses the model's own uncertainty to selectively invoke a second, more deliberate reasoning attempt, enabling stronger performance \emph{without any retraining}. On 12,032 MMLU-Pro questions across 14 subjects, using DeepSeek-v3.2 with deterministic decoding in a zero-shot setting, Reinforcement Inference improves accuracy from 60.72\% to 84.03\%, while only incurring 61.06\% additional inference calls. A 100\% re-asking ablation reaches 84.35\%, indicating that uncertainty-aware selection captures most of the attainable improvement with substantially less compute. Moreover, a \emph{prompt-only} ablation underperforms the baseline, suggesting that the gains are not explained by generic `` your output had high entropy, think step-by-step'' prompting alone. Beyond providing a practical inference-time upgrade, our results suggest a broader \emph{entropy-aware} paradigm for measuring and expanding model capability: because modern decoder-based models generate outputs autoregressively, entropy and related confidence measures arise naturally as first-class control signals during generation. The resulting gap between one-pass greedy inference and uncertainty-conditioned deliberation offers a diagnostic lens on an LLM's latent reasoning horizon and motivates future training objectives that explicitly constrain correctness--confidence alignment.