From Assistant to Double Agent: Formalizing and Benchmarking Attacks on OpenClaw for Personalized Local AI Agent
作者: Yuhang Wang, Feiming Xu, Zheng Lin, Guangyu He, Yuzhe Huang, Haichang Gao, Zhenxing Niu
分类: cs.AI
发布日期: 2026-02-09
备注: 11 pages,2 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出PASB框架,评估个性化本地AI助手OpenClaw的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化AI助手 安全评估 大型语言模型 智能体安全 提示注入攻击
📋 核心要点
- 现有智能体安全评估缺乏对真实个性化场景的覆盖,难以准确评估实际部署中的安全风险。
- PASB框架通过模拟真实用户场景、工具链和长期交互,实现对个性化智能体的端到端安全评估。
- 实验表明OpenClaw在提示处理、工具使用和记忆检索等阶段存在漏洞,验证了PASB的有效性。
📝 摘要(中文)
基于大型语言模型(LLM)的智能体,如OpenClaw,正从面向任务的系统演变为个性化的AI助手,以解决复杂的现实世界任务,但其部署也带来了严重的安全风险。现有的智能体安全研究和评估框架主要集中在合成或以任务为中心的设置中,未能准确捕捉到现实部署中个性化智能体的攻击面和风险传播机制。为了解决这个问题,我们提出了个性化智能体安全基准(PASB),这是一个为现实世界个性化智能体量身定制的端到端安全评估框架。PASB建立在现有的智能体攻击范式之上,结合了个性化的使用场景、真实的工具链和长期的交互,从而能够在真实系统上进行黑盒、端到端的安全评估。我们以OpenClaw为代表案例,系统地评估了其在多种个性化场景、工具能力和攻击类型中的安全性。结果表明,OpenClaw在不同的执行阶段(包括用户提示处理、工具使用和记忆检索)都存在严重漏洞,突出了个性化智能体部署中的重大安全风险。PASB框架的代码可在https://github.com/AstorYH/PASB获取。
🔬 方法详解
问题定义:现有智能体安全研究主要集中在合成或以任务为中心的设置中,无法准确捕捉到现实部署中个性化智能体的攻击面和风险传播机制。这意味着现有的评估方法无法有效识别和评估个性化AI助手在真实使用场景中面临的安全威胁,例如用户数据泄露、恶意代码执行等。
核心思路:论文的核心思路是构建一个更贴近真实使用场景的安全评估框架,即PASB。通过模拟个性化的用户交互、使用真实的工具链以及进行长期的交互,PASB能够更全面地评估个性化智能体在实际部署中可能遇到的安全风险。这种方法旨在弥补现有评估方法在真实性和全面性方面的不足。
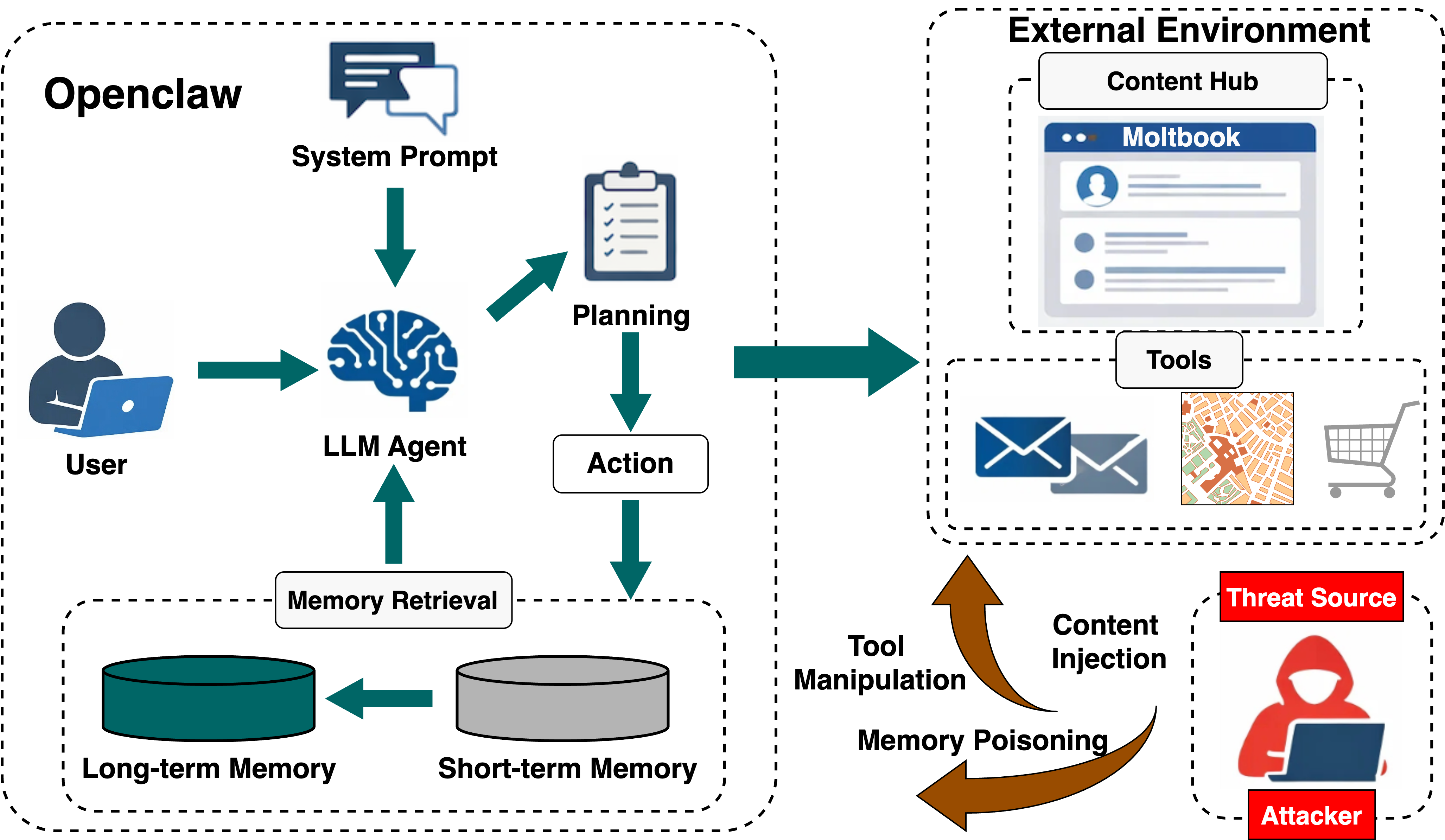
技术框架:PASB框架主要包含以下几个关键模块: 1. 个性化场景模拟:模拟真实用户的个性化使用习惯和偏好,例如用户特定的任务、数据和交互方式。 2. 真实工具链集成:集成智能体在实际使用中可能调用的各种工具,例如搜索引擎、数据库、API等。 3. 长期交互模拟:模拟用户与智能体之间的长期交互过程,以评估智能体在长期运行中可能出现的安全漏洞。 4. 攻击类型覆盖:涵盖各种常见的攻击类型,例如提示注入攻击、数据泄露攻击、拒绝服务攻击等。
关键创新:PASB的关键创新在于其端到端、黑盒的评估方式,以及对个性化场景的模拟。与传统的安全评估方法不同,PASB不需要了解智能体的内部实现细节,而是通过模拟真实用户的交互方式来评估智能体的安全性。此外,PASB还特别关注个性化场景,能够更准确地评估智能体在不同用户环境下的安全风险。
关键设计:PASB框架的关键设计包括: 1. 场景生成器:用于生成各种个性化的用户场景,包括用户画像、任务描述、数据输入等。 2. 工具集成接口:用于集成各种真实的工具,并模拟智能体对这些工具的调用过程。 3. 攻击策略库:包含各种常见的攻击策略,例如提示注入攻击、数据泄露攻击等。 4. 安全指标评估模块:用于评估智能体在不同攻击下的安全性能,例如成功率、影响范围等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OpenClaw在用户提示处理阶段容易受到提示注入攻击,攻击者可以通过构造恶意提示来控制智能体的行为。在工具使用阶段,OpenClaw存在数据泄露的风险,攻击者可以利用智能体访问敏感数据。在记忆检索阶段,OpenClaw容易受到记忆操纵攻击,攻击者可以篡改智能体的记忆,从而影响其决策。这些结果表明,个性化AI助手在实际部署中面临着严重的安全风险,需要采取有效的安全措施。
🎯 应用场景
该研究成果可应用于评估和提升各种基于LLM的个性化AI助手的安全性,例如智能家居助手、个人健康助手、金融顾问等。通过PASB框架,开发者可以更全面地了解其AI助手面临的安全风险,并采取相应的安全措施,从而保护用户的数据和隐私,提高AI助手的可靠性和安全性。该研究还有助于推动AI安全领域的标准化和规范化。
📄 摘要(原文)
Although large language model (LLM)-based agents, exemplified by OpenClaw, are increasingly evolving from task-oriented systems into personalized AI assistants for solving complex real-world tasks, their practical deployment also introduces severe security risks. However, existing agent security research and evaluation frameworks primarily focus on synthetic or task-centric settings, and thus fail to accurately capture the attack surface and risk propagation mechanisms of personalized agents in real-world deployments. To address this gap, we propose Personalized Agent Security Bench (PASB), an end-to-end security evaluation framework tailored for real-world personalized agents. Building upon existing agent attack paradigms, PASB incorporates personalized usage scenarios, realistic toolchains, and long-horizon interactions, enabling black-box, end-to-end security evaluation on real systems. Using OpenClaw as a representative case study, we systematically evaluate its security across multiple personalized scenarios, tool capabilities, and attack types. Our results indicate that OpenClaw exhibits critical vulnerabilities at different execution stages, including user prompt processing, tool usage, and memory retrieval, highlighting substantial security risks in personalized agent deployments. The code for the proposed PASB framework is available at https://github.com/AstorYH/PASB.