On Protecting Agentic Systems' Intellectual Property via Watermarking
作者: Liwen Wang, Zongjie Li, Yuchong Xie, Shuai Wang, Dongdong She, Wei Wang, Juergen Rahmel
分类: cs.AI, cs.CR
发布日期: 2026-02-09
💡 一句话要点
提出AGENTWM,通过水印保护Agentic系统免受模仿攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic系统 水印技术 知识产权保护 模仿攻击 语义等价性
📋 核心要点
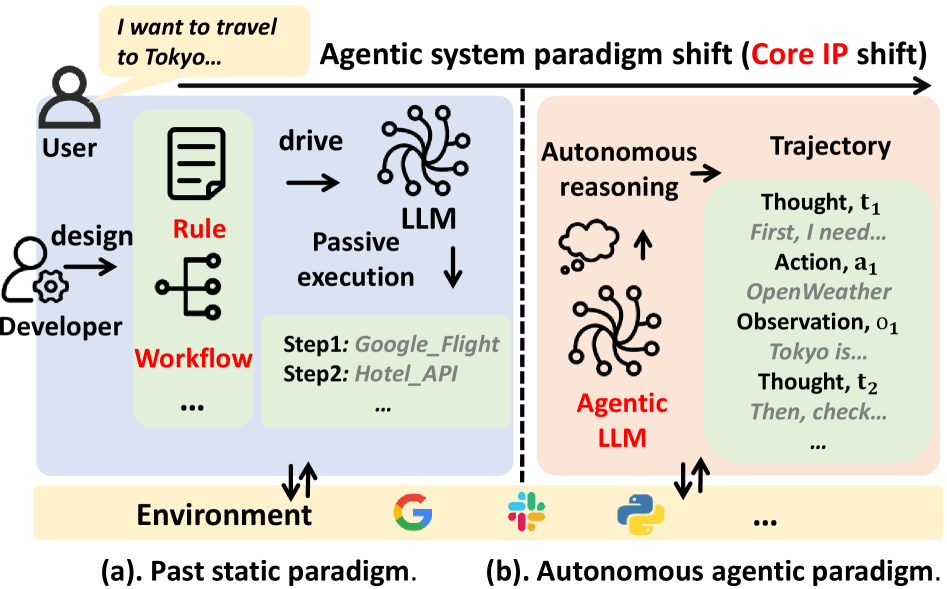
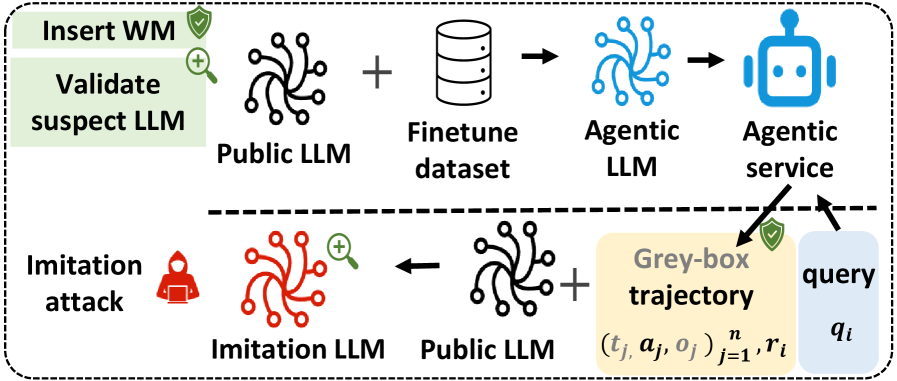
- Agentic系统易受模仿攻击,攻击者通过模仿学习窃取其能力,而现有LLM水印技术无法有效保护灰盒Agentic系统。
- AGENTWM利用动作序列的语义等价性,通过偏置工具执行路径分布,将水印嵌入可见的动作轨迹中,实现隐蔽且可验证的水印。
- 实验表明,AGENTWM在保证Agent性能不受显著影响的前提下,实现了高水印检测精度,有效防御了自适应攻击。
📝 摘要(中文)
大型语言模型(LLM)演变为具有自主推理和工具使用能力的Agentic系统,创造了重要的知识产权(IP)价值。我们证明这些系统极易受到模仿攻击,攻击者通过在受害者输出上训练模仿模型来窃取专有能力。现有的LLM水印技术在此领域失效,因为现实世界的Agentic系统通常作为灰盒运行,隐藏了验证所需的内部推理轨迹。本文提出了AGENTWM,这是第一个专门为Agentic模型设计的水印框架。AGENTWM利用动作序列的语义等价性,通过微妙地偏置功能相同的工具执行路径的分布来注入水印。这种机制允许AGENTWM将可验证的信号直接嵌入到可见的动作轨迹中,同时对用户保持不可区分。我们开发了一个自动化的pipeline来生成鲁棒的水印方案,以及一个严格的统计假设检验程序用于验证。在三个复杂领域的广泛评估表明,AGENTWM实现了高检测精度,同时对Agent性能的影响可忽略不计。我们的结果证实,AGENTWM有效地保护了Agentic IP免受自适应攻击者的攻击,攻击者无法在不严重降低被盗模型效用的情况下移除水印。
🔬 方法详解
问题定义:论文旨在解决Agentic系统面临的知识产权盗窃问题,具体表现为模仿攻击。现有的LLM水印技术依赖于访问模型的内部推理过程,这在实际的Agentic系统中通常不可行,因为它们通常作为灰盒运行,攻击者无法获取内部信息。因此,需要一种新的水印方案,能够在不访问内部状态的情况下,保护Agentic系统的知识产权。
核心思路:AGENTWM的核心思路是利用Agentic系统中动作序列的语义等价性。这意味着对于同一目标,Agent可能存在多种不同的工具执行路径,这些路径在功能上是等价的。AGENTWM通过微妙地偏置这些等价路径的分布,使得某些路径被更频繁地选择,从而将水印信息嵌入到Agent的行动轨迹中。这种方法的优势在于,水印信息隐藏在Agent的外部行为中,无需访问内部状态,同时对用户来说是不可察觉的。
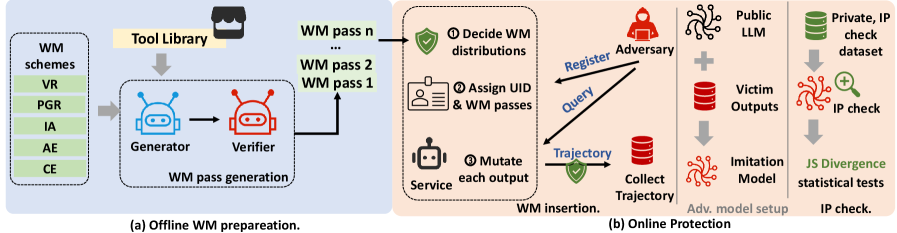
技术框架:AGENTWM包含以下主要模块:1) 水印方案生成器:自动生成鲁棒的水印方案,包括选择哪些动作序列进行偏置以及偏置的程度。2) 水印嵌入器:在Agent执行动作时,根据生成的水印方案,对动作序列的分布进行偏置,从而嵌入水印。3) 水印验证器:通过统计假设检验,判断Agent的行动轨迹中是否包含水印,从而检测是否存在模仿攻击。
关键创新:AGENTWM的关键创新在于其利用了Agentic系统中动作序列的语义等价性来实现水印嵌入。与传统的水印方法不同,AGENTWM不需要访问模型的内部状态,而是通过操纵Agent的外部行为来嵌入水印。这种方法更适用于实际的Agentic系统,因为它们通常作为灰盒运行。
关键设计:AGENTWM的关键设计包括:1) 动作序列选择策略:选择哪些动作序列进行偏置,需要考虑这些序列的频率、语义相似度以及对Agent性能的影响。2) 偏置程度控制:偏置程度需要足够大,以便能够有效检测水印,但又不能太大,以免影响Agent的性能。3) 统计假设检验:使用合适的统计假设检验方法来判断Agent的行动轨迹中是否包含水印,需要考虑误报率和漏报率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AGENTWM在三个复杂领域实现了高水印检测精度,同时对Agent性能的影响可忽略不计。具体而言,AGENTWM在保持Agent性能下降小于1%的情况下,实现了超过95%的检测准确率。此外,实验还证明了AGENTWM能够有效防御自适应攻击,即使攻击者试图移除水印,也会显著降低被盗模型的效用。
🎯 应用场景
AGENTWM可应用于保护各种Agentic系统的知识产权,例如智能助手、自动化机器人、游戏AI等。通过嵌入水印,可以有效防止攻击者通过模仿学习窃取这些系统的专有能力,从而保护开发者的投资和创新成果。此外,AGENTWM还可以用于验证Agentic系统的来源,防止恶意软件伪装成合法的Agentic系统。
📄 摘要(原文)
The evolution of Large Language Models (LLMs) into agentic systems that perform autonomous reasoning and tool use has created significant intellectual property (IP) value. We demonstrate that these systems are highly vulnerable to imitation attacks, where adversaries steal proprietary capabilities by training imitation models on victim outputs. Crucially, existing LLM watermarking techniques fail in this domain because real-world agentic systems often operate as grey boxes, concealing the internal reasoning traces required for verification. This paper presents AGENTWM, the first watermarking framework designed specifically for agentic models. AGENTWM exploits the semantic equivalence of action sequences, injecting watermarks by subtly biasing the distribution of functionally identical tool execution paths. This mechanism allows AGENTWM to embed verifiable signals directly into the visible action trajectory while remaining indistinguishable to users. We develop an automated pipeline to generate robust watermark schemes and a rigorous statistical hypothesis testing procedure for verification. Extensive evaluations across three complex domains demonstrate that AGENTWM achieves high detection accuracy with negligible impact on agent performance. Our results confirm that AGENTWM effectively protects agentic IP against adaptive adversaries, who cannot remove the watermarks without severely degrading the stolen model's utility.