Grounding Generative Planners in Verifiable Logic: A Hybrid Architecture for Trustworthy Embodied AI
作者: Feiyu Wu, Xu Zheng, Yue Qu, Zhuocheng Wang, Zicheng Feng, Hui Li
分类: cs.AI, cs.LG
发布日期: 2026-02-09
备注: Accepted to ICLR 2026. Project page. https://openreview.net/forum?id=wb05ver1k8¬eId=v1Ax8CwI71
💡 一句话要点
提出VIRF框架,通过逻辑导师与LLM协作,实现具身AI可验证的安全规划。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身AI 神经符号 可验证规划 大型语言模型 形式化推理
📋 核心要点
- 现有具身AI规划方法依赖LLM,缺乏形式化推理,难以保证物理部署的安全性。
- VIRF框架通过逻辑导师与LLM规划器协作,实现智能计划修复,而非简单地拒绝不安全计划。
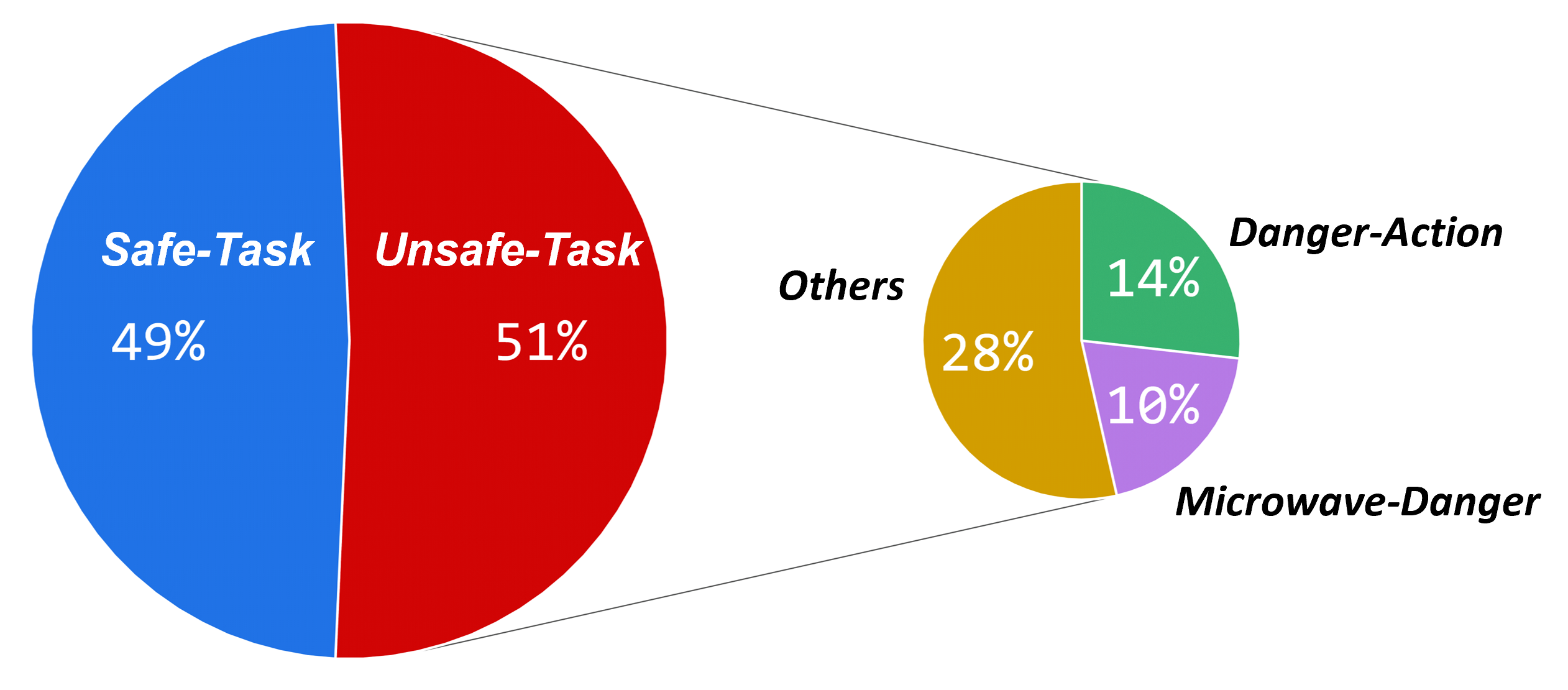
- VIRF在家庭安全任务中实现了0%的危险行为率和最高的77.3%目标条件率,平均只需1.1次迭代。
📝 摘要(中文)
大型语言模型(LLMs)在具身AI规划方面展现出潜力,但其随机性缺乏形式化推理,难以保证物理部署的严格安全性。现有方法通常依赖不可靠的LLM进行安全检查,或直接拒绝不安全计划而不提供修复。我们提出了可验证的迭代改进框架(VIRF),一种神经符号架构,将范式从被动安全把关转变为主动协作。我们的核心贡献是导师-学徒对话,其中基于形式化安全本体的确定性逻辑导师向LLM规划器提供因果和教学反馈,从而实现智能计划修复而非简单规避。我们还引入了可扩展的知识获取流程,从真实世界文档中合成安全知识库,纠正现有基准测试中的盲点。在具有挑战性的家庭安全任务中,VIRF实现了完美的0%危险行为率(HAR)和77.3%的目标条件率(GCR),是所有基线中最高的。它非常高效,平均只需要1.1次校正迭代。VIRF展示了一条构建根本上值得信赖且可验证安全的具身智能体的原则性途径。
🔬 方法详解
问题定义:论文旨在解决具身AI在家庭等真实环境中进行安全可靠规划的问题。现有方法,尤其是基于大型语言模型(LLM)的规划方法,虽然具有生成复杂计划的能力,但由于LLM的随机性和缺乏形式化推理,难以保证生成的计划是安全的,可能导致危险行为。现有方法要么依赖LLM自身进行安全检查(不可靠),要么直接拒绝不安全计划而不提供修复方案(效率低)。
核心思路:论文的核心思路是将LLM的生成能力与形式化逻辑推理相结合,构建一个神经符号架构。具体来说,利用LLM生成初始计划,然后使用一个基于形式化安全本体的逻辑导师对计划进行验证,并提供因果和教学反馈,指导LLM进行计划修复。这种导师-学徒的协作模式,既能发挥LLM的生成能力,又能保证计划的安全性。
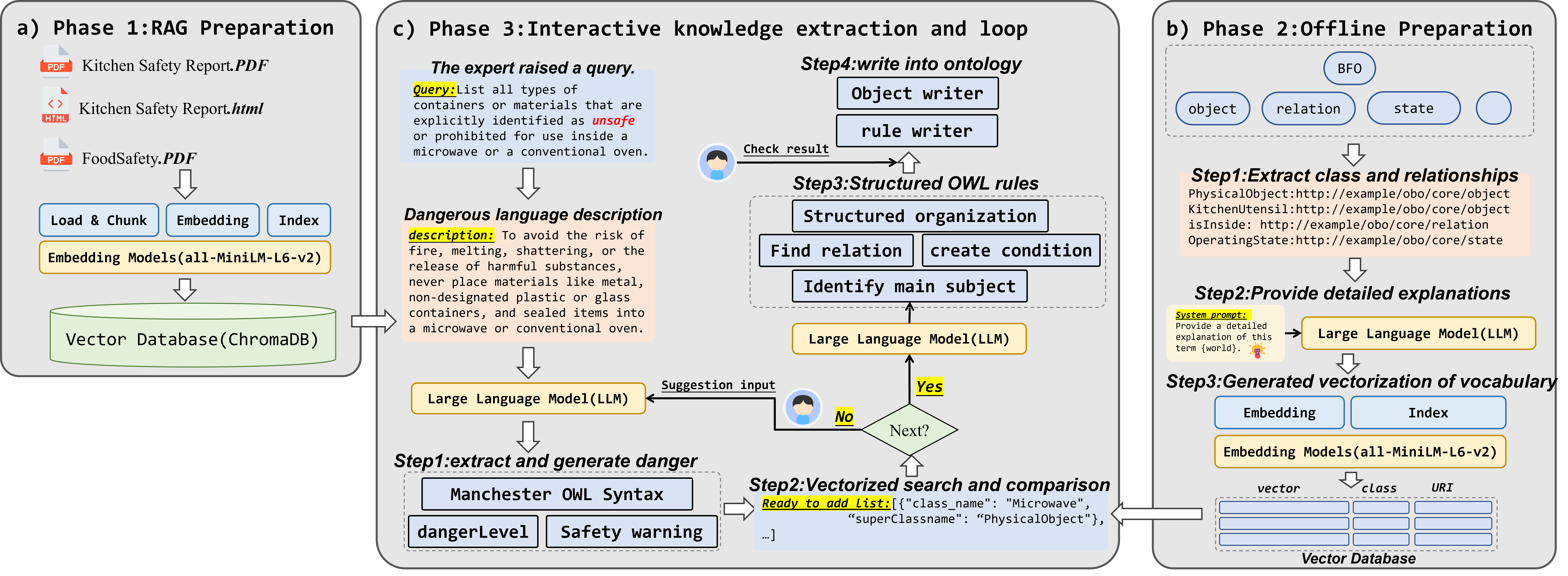
技术框架:VIRF框架包含以下主要模块:1) LLM规划器:负责生成初始的具身AI行动计划。2) 逻辑导师:基于形式化安全本体,对LLM生成的计划进行验证,判断是否存在危险行为,并提供因果解释和修复建议。3) 知识获取模块:从真实世界文档中提取安全知识,构建安全本体,用于逻辑导师的推理。4) 迭代改进模块:根据逻辑导师的反馈,LLM规划器对计划进行迭代修改,直到满足安全要求。整个流程是一个迭代的导师-学徒对话过程。
关键创新:论文最重要的技术创新点在于将LLM的生成能力与形式化逻辑推理相结合,提出了一个可验证的迭代改进框架。与现有方法相比,VIRF不是简单地依赖LLM进行安全检查或拒绝不安全计划,而是通过逻辑导师提供反馈,指导LLM进行智能计划修复,从而提高了规划的安全性和效率。此外,论文还提出了一个可扩展的知识获取流程,可以从真实世界文档中自动构建安全知识库,解决了现有基准测试中安全知识不足的问题。
关键设计:逻辑导师使用一阶逻辑规则表示安全知识,并使用定理证明器进行推理。LLM规划器使用提示工程(Prompt Engineering)来引导LLM生成计划,并根据逻辑导师的反馈进行修改。知识获取模块使用信息抽取技术从文本中提取实体和关系,并将其转换为逻辑规则。迭代改进模块使用强化学习或监督学习来训练LLM规划器,使其能够更好地理解逻辑导师的反馈并进行计划修复。具体参数设置和网络结构在论文中有详细描述,此处未知。
🖼️ 关键图片
📊 实验亮点
VIRF在家庭安全任务中取得了显著的成果,实现了0%的危险行为率(HAR),这意味着该框架能够完全避免危险行为的发生。同时,VIRF的目标条件率(GCR)达到了77.3%,是所有基线方法中最高的,表明该框架能够有效地完成任务目标。此外,VIRF的平均校正迭代次数仅为1.1次,表明该框架具有很高的效率。
🎯 应用场景
该研究成果可应用于各种需要安全可靠规划的具身AI场景,例如家庭服务机器人、医疗辅助机器人、自动驾驶汽车等。通过将LLM的生成能力与形式化逻辑推理相结合,可以构建更加值得信赖和可验证安全的智能体,从而提高这些智能体在真实世界中的应用价值和安全性,并降低潜在风险。
📄 摘要(原文)
Large Language Models (LLMs) show promise as planners for embodied AI, but their stochastic nature lacks formal reasoning, preventing strict safety guarantees for physical deployment. Current approaches often rely on unreliable LLMs for safety checks or simply reject unsafe plans without offering repairs. We introduce the Verifiable Iterative Refinement Framework (VIRF), a neuro-symbolic architecture that shifts the paradigm from passive safety gatekeeping to active collaboration. Our core contribution is a tutor-apprentice dialogue where a deterministic Logic Tutor, grounded in a formal safety ontology, provides causal and pedagogical feedback to an LLM planner. This enables intelligent plan repairs rather than mere avoidance. We also introduce a scalable knowledge acquisition pipeline that synthesizes safety knowledge bases from real-world documents, correcting blind spots in existing benchmarks. In challenging home safety tasks, VIRF achieves a perfect 0 percent Hazardous Action Rate (HAR) and a 77.3 percent Goal-Condition Rate (GCR), which is the highest among all baselines. It is highly efficient, requiring only 1.1 correction iterations on average. VIRF demonstrates a principled pathway toward building fundamentally trustworthy and verifiably safe embodied agents.