Who Deserves the Reward? SHARP: Shapley Credit-based Optimization for Multi-Agent System
作者: Yanming Li, Xuelin Zhang, WenJie Lu, Ziye Tang, Maodong Wu, Haotian Luo, Tongtong Wu, Zijie Peng, Hongze Mi, Yibo Feng, Naiqiang Tan, Chao Huang, Hong Chen, Li Shen
分类: cs.AI
发布日期: 2026-02-09
💡 一句话要点
SHARP:基于Shapley值的多智能体系统奖励优化框架,解决信用分配难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 强化学习 信用分配 Shapley值 奖励函数 深度学习 智能体协作
📋 核心要点
- 多智能体系统面临信用分配难题,难以确定每个智能体对最终结果的贡献。
- SHARP框架通过Shapley值进行信用分配,并结合全局奖励和工具奖励,实现更有效的训练。
- 实验表明,SHARP在多个真实场景中显著优于现有方法,性能提升明显。
📝 摘要(中文)
本文提出了一种名为SHARP(Shapley-based Hierarchical Attribution for Reinforcement Policy)的框架,旨在通过精确的信用分配来优化多智能体强化学习。多智能体系统结合大型语言模型(LLM)与外部工具,为分解和解决复杂问题提供了一种有前景的新范式。然而,由于信用分配的挑战,训练此类系统非常困难,因为通常不清楚哪个特定功能智能体对决策轨迹的成功或失败负责。SHARP通过对轨迹组中特定于智能体的优势进行归一化来有效地稳定训练,这主要通过分解的奖励机制实现,该机制包括全局广播的准确性奖励、基于Shapley值的每个智能体的边际信用奖励以及用于提高执行效率的工具过程奖励。在各种真实世界基准上的大量实验表明,SHARP显著优于最新的基线方法,与单智能体和多智能体方法相比,平均匹配改进分别达到23.66%和14.05%。
🔬 方法详解
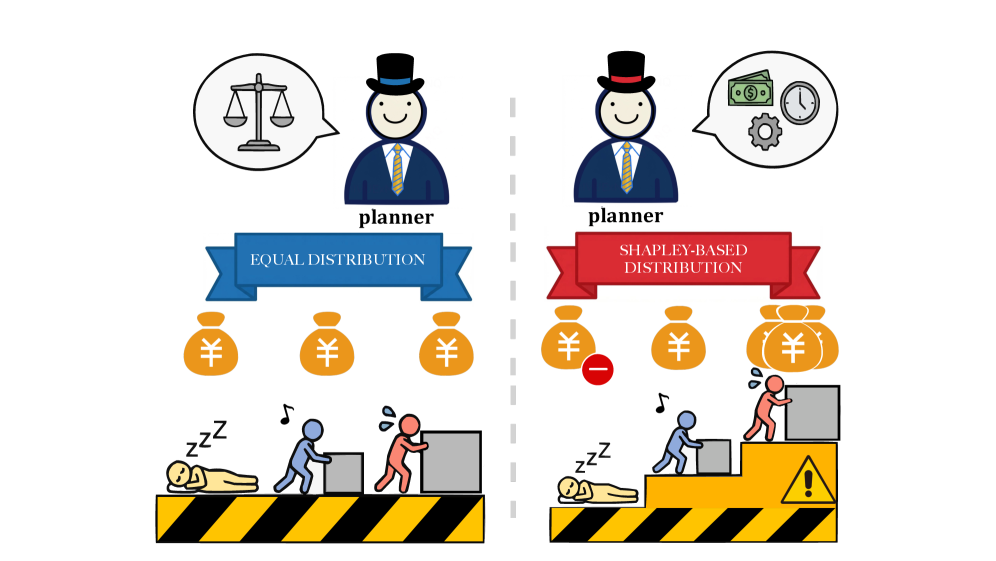
问题定义:多智能体系统在解决复杂问题时,面临着严重的信用分配问题。传统的强化学习方法通常依赖于稀疏或全局广播的奖励,无法准确评估每个智能体的贡献,导致训练效率低下,难以收敛。现有方法无法有效区分各个智能体在决策过程中的作用,难以针对性地优化每个智能体的策略。
核心思路:SHARP的核心思路是利用Shapley值来精确评估每个智能体对整体奖励的边际贡献。Shapley值是一种合作博弈论中的概念,可以公平地分配合作产生的收益。通过计算每个智能体加入或离开智能体联盟时对整体奖励的影响,可以量化其重要性。此外,SHARP还引入了全局准确性奖励和工具过程奖励,以进一步稳定训练并提高执行效率。
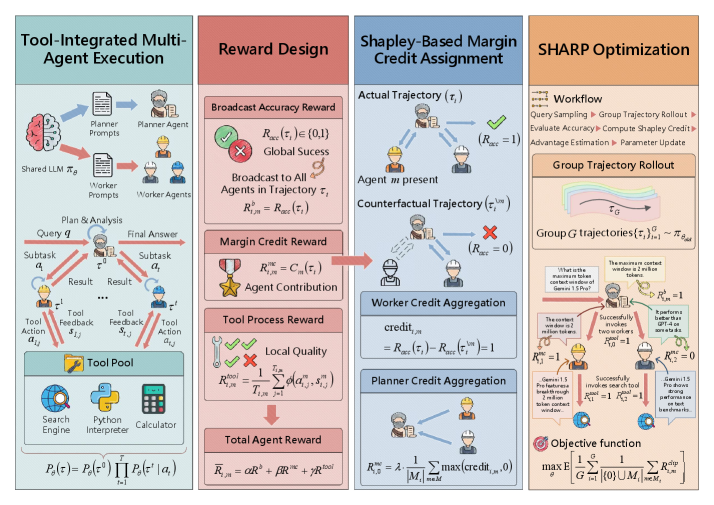
技术框架:SHARP框架包含三个主要的奖励组成部分:1) 全局广播的准确性奖励,用于鼓励整体任务的完成;2) 基于Shapley值的边际信用奖励,用于评估每个智能体的贡献;3) 工具过程奖励,用于提高智能体使用工具的效率。在训练过程中,每个智能体根据这三种奖励的加权和来更新其策略。框架通过对轨迹组中特定于智能体的优势进行归一化来稳定训练。
关键创新:SHARP的关键创新在于将Shapley值应用于多智能体强化学习的信用分配问题。与传统的奖励分配方法相比,Shapley值能够更准确地评估每个智能体的贡献,从而实现更有效的策略优化。此外,SHARP还引入了工具过程奖励,鼓励智能体更有效地使用外部工具,进一步提高了系统的整体性能。
关键设计:SHARP的关键设计包括:1) Shapley值的计算方法,需要高效地估计每个智能体的边际贡献;2) 三种奖励的权重设置,需要根据具体任务进行调整;3) 优势函数归一化的方法,用于稳定训练过程。具体的网络结构和参数设置需要根据具体的应用场景进行调整。损失函数是三种奖励的加权和,通过梯度下降法进行优化。
🖼️ 关键图片
📊 实验亮点
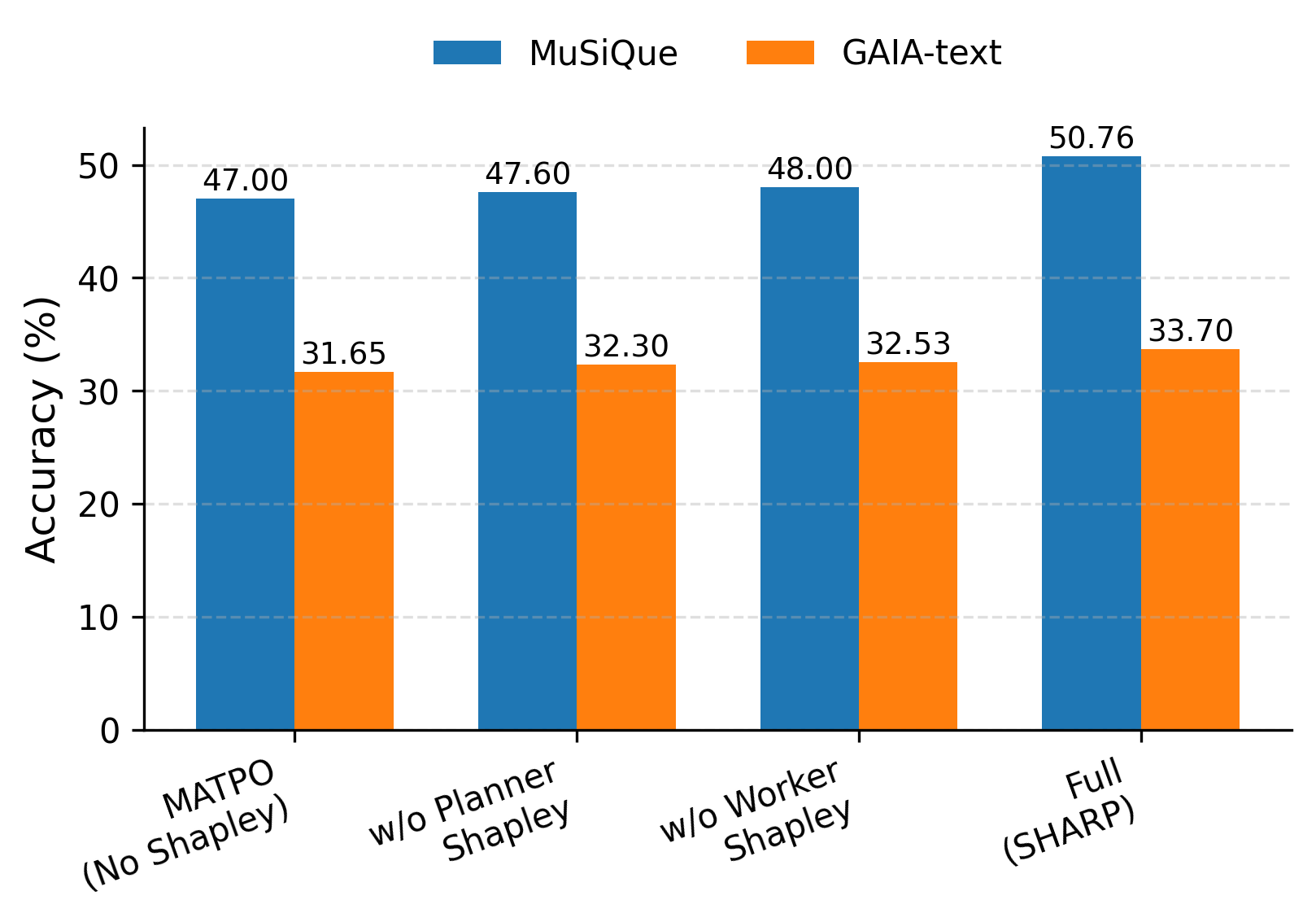
实验结果表明,SHARP在多个真实世界基准上显著优于最新的基线方法。与单智能体方法相比,平均匹配改进达到23.66%;与多智能体方法相比,平均匹配改进达到14.05%。这些结果验证了SHARP框架在解决多智能体信用分配问题上的有效性,并展示了其在实际应用中的潜力。
🎯 应用场景
SHARP框架可应用于各种需要多智能体协作解决复杂问题的场景,例如:机器人协作、自动驾驶、智能交通、供应链管理、金融交易等。通过精确的信用分配,可以提高多智能体系统的训练效率和性能,使其能够更好地适应复杂多变的环境,并实现更高效的协作。
📄 摘要(原文)
Integrating Large Language Models (LLMs) with external tools via multi-agent systems offers a promising new paradigm for decomposing and solving complex problems. However, training these systems remains notoriously difficult due to the credit assignment challenge, as it is often unclear which specific functional agent is responsible for the success or failure of decision trajectories. Existing methods typically rely on sparse or globally broadcast rewards, failing to capture individual contributions and leading to inefficient reinforcement learning. To address these limitations, we introduce the Shapley-based Hierarchical Attribution for Reinforcement Policy (SHARP), a novel framework for optimizing multi-agent reinforcement learning via precise credit attribution. SHARP effectively stabilizes training by normalizing agent-specific advantages across trajectory groups, primarily through a decomposed reward mechanism comprising a global broadcast-accuracy reward, a Shapley-based marginal-credit reward for each agent, and a tool-process reward to improve execution efficiency. Extensive experiments across various real-world benchmarks demonstrate that SHARP significantly outperforms recent state-of-the-art baselines, achieving average match improvements of 23.66% and 14.05% over single-agent and multi-agent approaches, respectively.