Weak-Driven Learning: How Weak Agents make Strong Agents Stronger
作者: Zehao Chen, Gongxun Li, Tianxiang Ai, Yifei Li, Zixuan Huang, Wang Zhou, Fuzhen Zhuang, Xianglong Liu, Jianxin Li, Deqing Wang, Yikun Ban
分类: cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出WMSS弱驱动学习,利用模型历史弱状态指导优化,突破后训练饱和瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 弱驱动学习 后训练优化 大型语言模型 熵动力学 补偿学习
📋 核心要点
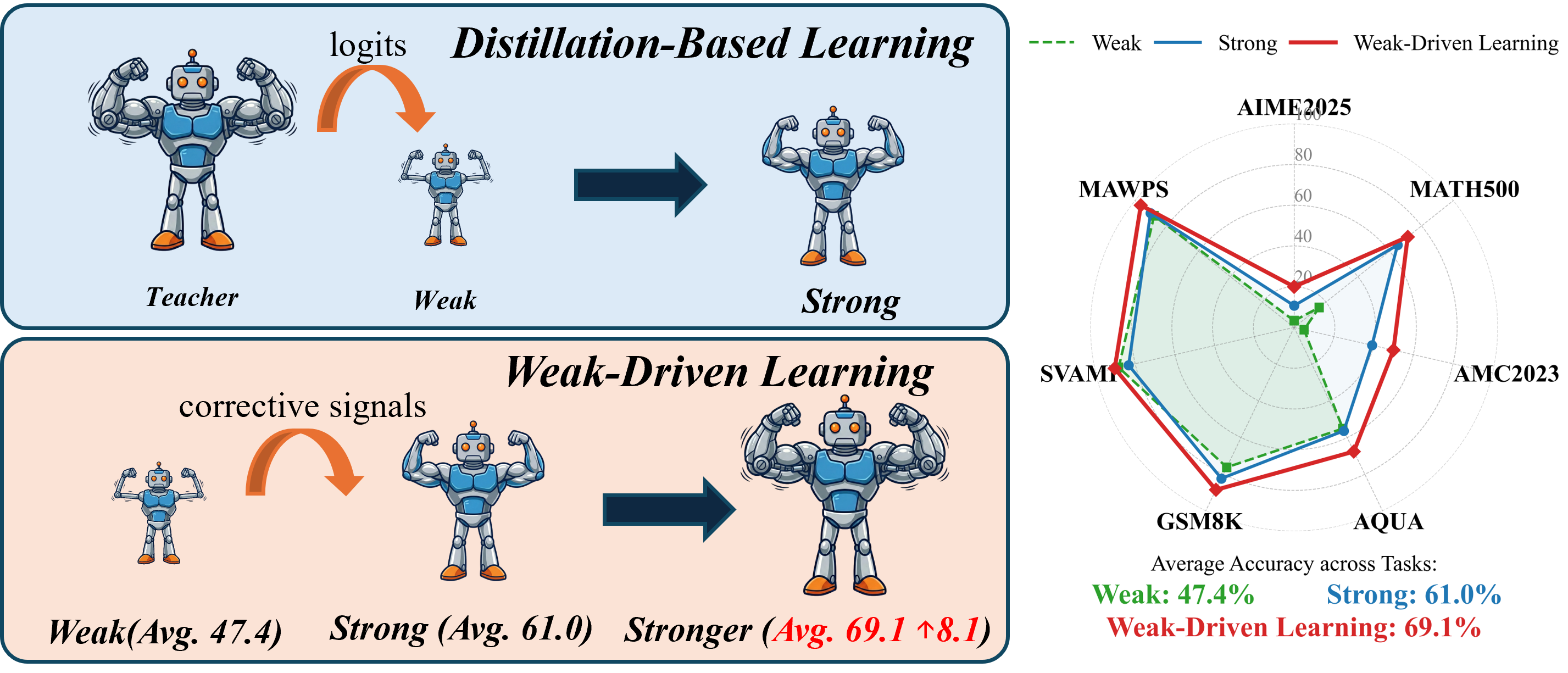
- 现有后训练方法在模型自信度高时易饱和,无法有效利用模型自身历史弱状态中蕴含的监督信息。
- WMSS方法利用模型历史弱检查点指导优化,通过熵动力学识别学习差距,并进行补偿学习。
- 实验表明,WMSS在数学推理和代码生成任务上有效提升模型性能,且不增加推理成本。
📝 摘要(中文)
随着后训练优化在改进大型语言模型中变得至关重要,我们观察到一个持续存在的饱和瓶颈:一旦模型变得高度自信,进一步的训练就会产生递减的回报。虽然现有的方法继续强化目标预测,但我们发现信息丰富的监督信号仍然潜藏在模型自身的历史弱状态中。受此观察的启发,我们提出了一种名为WMSS(弱智能体使强智能体更强)的后训练范式,该范式利用弱检查点来指导持续优化。通过熵动力学识别可恢复的学习差距,并通过补偿学习来加强这些差距,WMSS使强智能体能够超越传统的后训练饱和度进行改进。在数学推理和代码生成数据集上的实验表明,使用我们的方法训练的智能体实现了有效的性能改进,同时不会产生额外的推理成本。
🔬 方法详解
问题定义:论文旨在解决大型语言模型后训练优化过程中出现的饱和问题。现有方法过度强化已有预测,忽略了模型在训练早期阶段(弱状态)所蕴含的潜在有用信息。当模型变得过于自信时,进一步训练带来的收益会显著降低,导致性能提升停滞。
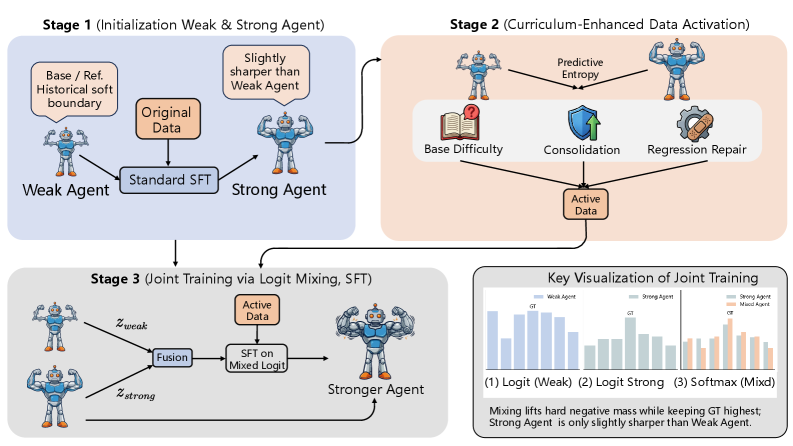
核心思路:论文的核心思路是利用模型自身的历史弱状态(weak checkpoints)作为额外的监督信号,指导模型的进一步训练。通过分析模型在不同训练阶段的熵变化,识别出模型在早期阶段学习不足但在后期有潜力提升的部分,并针对性地进行补偿学习。
技术框架:WMSS (Weak Agents Can Make Strong Agents Stronger) 包含以下主要阶段:1) 弱检查点选择:在模型训练过程中保存多个弱检查点。2) 熵动力学分析:分析模型在不同检查点上的预测熵变化,识别出学习差距较大的样本。3) 补偿学习:利用弱检查点对强模型进行微调,重点关注熵变化较大的样本,以弥补学习差距。整体流程是,先训练一个强模型,然后利用WMSS进行后训练优化。
关键创新:WMSS的关键创新在于它不再仅仅依赖于强模型的当前状态进行训练,而是充分挖掘了模型自身的历史信息。通过熵动力学分析,WMSS能够更精确地识别出模型学习的薄弱环节,并利用弱检查点提供更具针对性的监督信号。这与传统方法只关注当前预测结果的强化学习方式有本质区别。
关键设计:WMSS的关键设计包括:1) 熵计算方法:使用交叉熵或KL散度等方法计算模型预测的熵,用于衡量模型的不确定性。2) 弱检查点选择策略:例如,可以定期保存检查点,或者根据验证集性能选择代表性的弱检查点。3) 补偿学习损失函数:可以使用加权交叉熵损失,其中权重与熵变化成正比,以强调对学习差距较大样本的训练。4) 微调策略:例如,可以使用较小的学习率和较少的训练轮数,以避免过度拟合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在数学推理和代码生成数据集上,使用WMSS方法训练的智能体实现了显著的性能提升。例如,在某个数学推理数据集上,WMSS将模型的准确率从X%提升到Y%,超过了现有后训练优化方法Z%。此外,WMSS在提升性能的同时,没有增加模型的推理成本。
🎯 应用场景
WMSS方法可广泛应用于各种需要后训练优化的大型语言模型,尤其是在数学推理、代码生成等对知识掌握和推理能力要求较高的领域。该方法能够有效提升模型性能,且不增加推理成本,具有很高的实际应用价值。未来,该方法可以进一步扩展到其他模态的模型,例如图像和语音模型。
📄 摘要(原文)
As post-training optimization becomes central to improving large language models, we observe a persistent saturation bottleneck: once models grow highly confident, further training yields diminishing returns. While existing methods continue to reinforce target predictions, we find that informative supervision signals remain latent in models' own historical weak states. Motivated by this observation, we propose WMSS (Weak Agents Can Make Strong Agents Stronger), a post-training paradigm that leverages weak checkpoints to guide continued optimization. By identifying recoverable learning gaps via entropy dynamics and reinforcing them through compensatory learning, WMSS enables strong agents to improve beyond conventional post-training saturation. Experiments on mathematical reasoning and code generation datasets show that agents trained with our approach achieve effective performance improvements, while incurring zero additional inference cost.