Nexus: Inferring Join Graphs from Metadata Alone via Iterative Low-Rank Matrix Completion
作者: Tianji Cong, Yuanyuan Tian, Andreas Mueller, Rathijit Sen, Yeye He, Fotis Psallidas, Shaleen Deep, H. V. Jagadish
分类: cs.DB, cs.AI
发布日期: 2026-02-09
💡 一句话要点
Nexus:通过迭代低秩矩阵补全,仅从元数据推断连接图
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 连接图推断 元数据 低秩矩阵补全 期望最大化算法 大型语言模型
📋 核心要点
- 现有方法在大型复杂模式中,尤其是在数据访问受限时,难以准确高效地推断连接关系。
- Nexus利用连接图邻接矩阵的高稀疏性和低秩结构,将其建模为低秩矩阵补全问题。
- 实验表明,Nexus在多个数据集上显著优于现有方法,并提供快速模式,速度提升高达6倍。
📝 摘要(中文)
自动推断连接关系对于有效的数据发现、集成、查询和重用至关重要。然而,在大型复杂模式中准确高效地识别这些关系可能具有挑战性,尤其是在访问数据值受限的企业环境中。本文提出了仅在元数据可用时进行连接图推断的问题。我们对大量真实模式进行了实证研究,发现连接图在表示为邻接矩阵时表现出两个关键属性:高稀疏性和低秩结构。基于这些新颖的观察,我们将连接图推断形式化为低秩矩阵补全问题,并提出了Nexus,一个仅使用元数据的端到端解决方案。为了进一步提高准确性,我们提出了一种新颖的期望最大化算法,该算法在低秩矩阵补全和通过利用大型语言模型来细化连接候选概率之间交替进行。我们广泛的实验表明,在包括真实生产数据集在内的四个数据集上,Nexus的性能明显优于现有方法。此外,Nexus可以快速运行,提供具有可比性的结果,并且速度提高了6倍,为实际部署提供了一种实用且高效的解决方案。
🔬 方法详解
问题定义:论文旨在解决仅在元数据可用的情况下,如何准确高效地推断数据库模式中的连接图的问题。现有方法通常依赖于数据值,但在许多企业环境中,访问数据值受到限制,使得这些方法无法应用。此外,即使可以访问数据,在大型复杂模式中识别连接关系仍然是一个计算密集型的问题。
核心思路:论文的核心思路是观察到连接图的邻接矩阵具有高稀疏性和低秩结构。高稀疏性是因为并非所有表都相互连接,而低秩结构则源于某些表之间存在共同的连接模式。基于此,论文将连接图推断问题转化为一个低秩矩阵补全问题,即从部分观察到的邻接矩阵中恢复完整的矩阵。
技术框架:Nexus的整体框架包含以下几个主要阶段:1) 元数据提取:从数据库模式中提取表名、列名等元数据。2) 连接候选生成:基于元数据生成可能的连接候选对。3) 低秩矩阵补全:使用迭代低秩矩阵补全算法,根据观察到的连接关系和矩阵的低秩假设,推断缺失的连接关系。4) 期望最大化(EM)优化:利用大型语言模型(LLM)对连接候选概率进行细化,并与低秩矩阵补全交替进行,以提高准确性。
关键创新:论文的关键创新在于:1) 提出了仅使用元数据进行连接图推断的问题。2) 观察到连接图邻接矩阵的高稀疏性和低秩结构,并将其用于指导连接图推断。3) 提出了基于EM算法的迭代优化方法,结合低秩矩阵补全和LLM,进一步提高准确性。
关键设计:Nexus的关键设计包括:1) 使用奇异值阈值化(Singular Value Thresholding, SVT)算法进行低秩矩阵补全。2) 使用LLM(例如,GPT-3)对连接候选对进行评分,并将其作为先验概率融入到EM算法中。3) 设计了快速模式,通过减少迭代次数和简化LLM的使用,实现速度提升。
🖼️ 关键图片
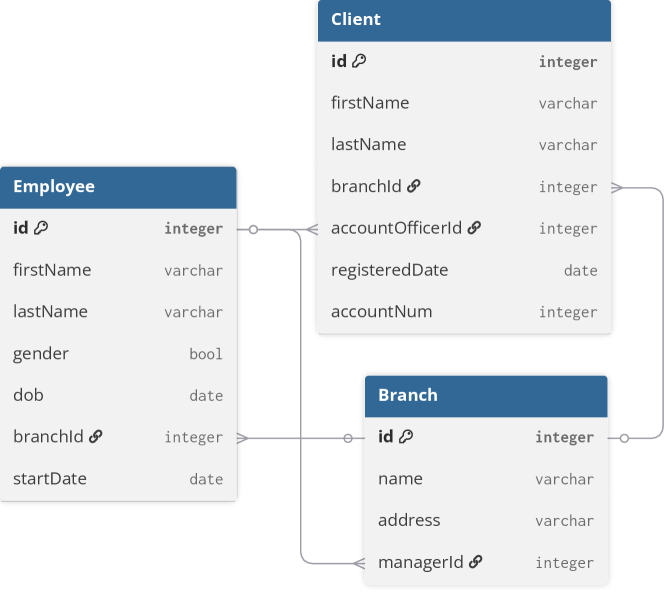
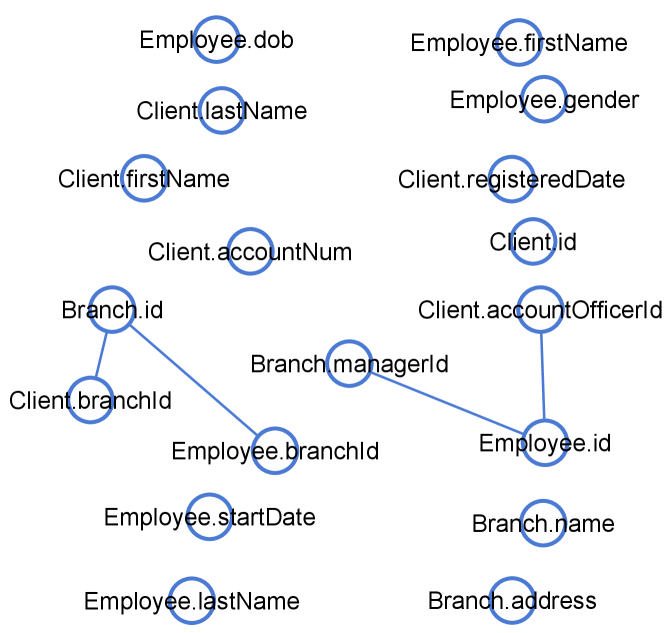

📊 实验亮点
实验结果表明,Nexus在四个数据集上显著优于现有方法。在真实生产数据集上,Nexus的F1-score比最佳基线提高了10%以上。此外,Nexus的快速模式在保持可比性能的同时,实现了高达6倍的速度提升,使其更适用于实际部署。
🎯 应用场景
该研究成果可应用于数据治理、数据集成、数据发现和查询优化等领域。通过自动推断连接关系,可以帮助用户更好地理解和利用数据资产,提高数据分析和决策的效率。在企业环境中,可以用于构建数据目录、优化查询性能、支持数据沿袭分析等。未来,该方法可以扩展到更复杂的数据模式和数据类型,例如图数据库和非结构化数据。
📄 摘要(原文)
Automatically inferring join relationships is a critical task for effective data discovery, integration, querying and reuse. However, accurately and efficiently identifying these relationships in large and complex schemas can be challenging, especially in enterprise settings where access to data values is constrained. In this paper, we introduce the problem of join graph inference when only metadata is available. We conduct an empirical study on a large number of real-world schemas and observe that join graphs when represented as adjacency matrices exhibit two key properties: high sparsity and low-rank structure. Based on these novel observations, we formulate join graph inference as a low-rank matrix completion problem and propose Nexus, an end-to-end solution using only metadata. To further enhance accuracy, we propose a novel Expectation-Maximization algorithm that alternates between low-rank matrix completion and refining join candidate probabilities by leveraging Large Language Models. Our extensive experiments demonstrate that Nexus outperforms existing methods by a significant margin on four datasets including a real-world production dataset. Additionally, Nexus can operate in a fast mode, providing comparable results with up to 6x speedup, offering a practical and efficient solution for real-world deployments.