Can Multimodal LLMs See Science Instruction? Benchmarking Pedagogical Reasoning in K-12 Classroom Videos
作者: Yixuan Shen, Peng He, Honglu Liu, Yuyang Ji, Tingting Li, Tianlong Chen, Kaidi Xu, Feng Liu
分类: cs.CY, cs.AI, cs.CV
发布日期: 2026-02-08
备注: 17pages, 3 figures
💡 一句话要点
提出SciIBI,用于评估多模态LLM在K-12科学课堂视频中教学推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 科学教育 课堂分析 教学推理 视频理解
📋 核心要点
- 现有课堂讨论分析benchmark主要依赖文本,忽略了科学教学中重要的视觉信息和模型推理。
- 论文构建了SciIBI视频基准,包含NGSS对齐的科学课堂视频,并标注了核心教学实践(CIP)。
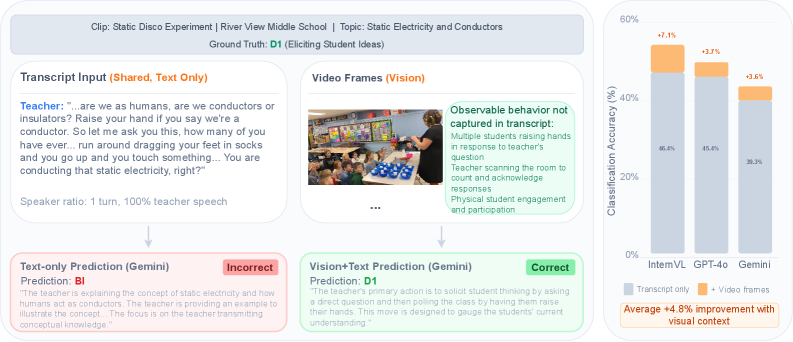
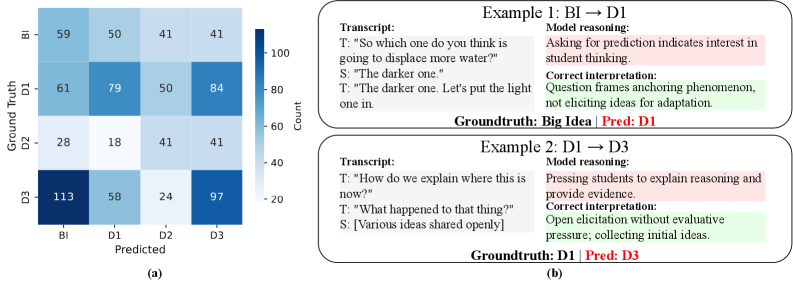
- 实验表明,现有LLM和多模态LLM难以进行教学推理,倾向于利用表面信息,且视频信息增益不稳定。
📝 摘要(中文)
K-12科学课堂是探究的丰富场所,学生通过讨论协调现象、证据和解释性模型;然而,这些互动在多模态上的复杂性使得自动分析难以实现。现有的课堂讨论基准主要集中在数学上,并且仅仅依赖于文本记录,忽略了下一代科学标准(NGSS)所强调的视觉人工制品和基于模型的推理。我们通过SciIBI解决了这个差距,SciIBI是第一个用于分析科学课堂讨论的视频基准,包含113个与NGSS对齐的片段,并标注了核心教学实践(CIP)和复杂程度。通过评估八个最先进的LLM和多模态LLM,我们揭示了根本的局限性:当前的模型难以区分教学上相似的实践,这表明CIP编码需要超越表面模式匹配的教学推理。此外,添加视频输入在不同架构上产生了不一致的收益。至关重要的是,我们基于证据的评估表明,模型通常通过表面捷径而不是真正的教学理解来取得成功。这些发现将科学课堂讨论确立为多模态AI的一个具有挑战性的前沿,并指向人机协作,其中模型检索证据以加速专家审查,而不是取代它。
🔬 方法详解
问题定义:现有课堂讨论分析方法主要集中在数学领域,并且依赖于文本记录,忽略了科学课堂中丰富的视觉信息(如实验器材、图表等)以及学生基于模型的推理过程。这导致现有方法无法有效分析科学课堂的教学实践和学生的学习情况。因此,需要一个能够处理多模态信息,并且能够评估模型教学推理能力的基准数据集。
核心思路:论文的核心思路是构建一个包含科学课堂视频,并标注了核心教学实践(CIP)和复杂程度的基准数据集SciIBI。通过评估现有LLM和多模态LLM在SciIBI上的表现,来分析这些模型在理解科学教学内容和进行教学推理方面的能力。同时,分析视频信息对模型性能的影响,以及模型是否真正理解了教学内容,还是仅仅利用了表面信息。
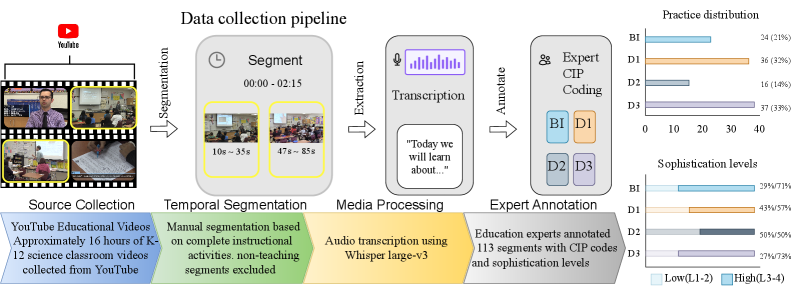
技术框架:SciIBI基准数据集的构建流程如下: 1. 数据收集:收集与NGSS对齐的K-12科学课堂视频片段。 2. 数据标注:由专家对视频片段进行标注,标注内容包括核心教学实践(CIP)和复杂程度。 3. 模型评估:使用现有LLM和多模态LLM在SciIBI上进行评估,分析模型的性能和局限性。 4. 错误分析:对模型的错误进行分析,探究模型失败的原因。
关键创新:论文的关键创新在于: 1. 提出了SciIBI基准数据集:这是第一个用于分析科学课堂讨论的视频基准,填补了现有基准数据集的空白。 2. 揭示了现有模型的局限性:通过实验表明,现有LLM和多模态LLM难以进行教学推理,倾向于利用表面信息。 3. 强调了人机协作的重要性:认为模型可以作为辅助工具,帮助专家进行审查,而不是完全取代专家。
关键设计:SciIBI数据集包含113个与NGSS对齐的视频片段,每个片段都由专家标注了核心教学实践(CIP)和复杂程度。CIP包括诸如“引导学生提出问题”、“鼓励学生提供证据”等教学行为。复杂程度则反映了教学实践的深度和难度。在模型评估方面,论文使用了多种LLM和多模态LLM,包括GPT-3、Llama 2、Gemini等,并分析了视频信息对模型性能的影响。具体参数设置和损失函数等细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有LLM和多模态LLM在SciIBI上的表现不佳,难以区分教学上相似的实践,表明模型缺乏真正的教学理解能力。添加视频输入在不同架构上产生了不一致的收益,部分模型甚至因为视频信息的引入而性能下降。这说明现有模型在处理多模态信息方面仍存在挑战。
🎯 应用场景
该研究成果可应用于教育领域,例如开发智能教学辅助系统,帮助教师分析课堂教学情况,提供个性化教学建议。此外,该研究也可以促进多模态AI技术在教育领域的应用,例如开发能够理解学生学习过程的智能辅导系统。未来的研究可以探索如何利用模型检索证据以加速专家审查,从而实现更有效的人机协作。
📄 摘要(原文)
K-12 science classrooms are rich sites of inquiry where students coordinate phenomena, evidence, and explanatory models through discourse; yet, the multimodal complexity of these interactions has made automated analysis elusive. Existing benchmarks for classroom discourse focus primarily on mathematics and rely solely on transcripts, overlooking the visual artifacts and model-based reasoning emphasized by the Next Generation Science Standards (NGSS). We address this gap with SciIBI, the first video benchmark for analyzing science classroom discourse, featuring 113 NGSS-aligned clips annotated with Core Instructional Practices (CIP) and sophistication levels. By evaluating eight state-of-the-art LLMs and Multimodal LLMs, we reveal fundamental limitations: current models struggle to distinguish pedagogically similar practices, suggesting that CIP coding requires instructional reasoning beyond surface pattern matching. Furthermore, adding video input yields inconsistent gains across architectures. Crucially, our evidence-based evaluation reveals that models often succeed through surface shortcuts rather than genuine pedagogical understanding. These findings establish science classroom discourse as a challenging frontier for multimodal AI and point toward human-AI collaboration, where models retrieve evidence to accelerate expert review rather than replace it.