Can Large Language Models Implement Agent-Based Models? An ODD-based Replication Study
作者: Nuno Fachada, Daniel Fernandes, Carlos M. Fernandes, João P. Matos-Carvalho
分类: cs.SE, cs.AI, cs.MA
发布日期: 2026-02-08
💡 一句话要点
评估大型语言模型在Agent-Based模型实现中的可靠性,探索其在可复现建模中的潜力与局限。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Agent-Based模型 ODD规范 代码生成 模型复现
📋 核心要点
- 现有Agent-Based模型开发依赖人工编码,耗时且易出错,缺乏自动化工具支持。
- 利用大型语言模型将ODD规范自动翻译为可执行代码,旨在提升模型开发效率和可复现性。
- 实验评估了17个LLM在ODD-to-code任务中的表现,分析了其生成代码的正确性、效率和可维护性。
📝 摘要(中文)
大型语言模型(LLMs)现在可以从文本描述中合成可执行代码,这引发了一个重要问题:LLMs能否可靠地从标准化规范中实现基于Agent的模型,从而支持复制、验证和确认?我们通过评估17个当代LLMs在一个受控的ODD-to-code翻译任务中来解决这个问题,使用PPHPC捕食者-猎物模型作为完全指定的参考。通过分阶段的可执行性检查、与经过验证的NetLogo基线进行模型独立的统计比较以及运行时效率和可维护性的定量测量来评估生成的Python实现。结果表明,行为上忠实的实现是可以实现的,但不能保证,并且仅凭可执行性不足以用于科学用途。GPT-4.1始终如一地产生统计上有效且高效的实现,而Claude 3.7 Sonnet表现良好但不太可靠。总的来说,这些发现阐明了LLMs作为模型工程工具的希望和当前局限性,对可重复的基于Agent和环境建模具有影响。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在将Agent-Based模型(ABM)的ODD(Overview, Design concepts, Details)规范自动转化为可执行代码方面的能力。现有ABM开发过程依赖于手动编码,耗时且容易出错,缺乏自动化工具的支持,阻碍了模型的可复现性、验证和确认。
核心思路:论文的核心思路是利用LLMs强大的代码生成能力,将ABM的标准化ODD描述作为输入,自动生成相应的可执行代码。通过这种方式,期望降低ABM开发的门槛,提高开发效率,并促进模型的可复现性。论文选择PPHPC捕食者-猎物模型作为案例,因为它具有完整的ODD规范,并且已经存在经过验证的NetLogo实现,方便进行对比。
技术框架:论文的技术框架主要包括以下几个阶段:1) 选择17个主流LLMs(包括GPT系列、Claude系列等);2) 将PPHPC模型的ODD规范作为输入,要求LLMs生成Python代码实现;3) 对生成的代码进行分阶段的可执行性检查,包括语法错误、依赖缺失等;4) 将生成的代码与经过验证的NetLogo基线进行模型无关的统计比较,评估其行为是否一致;5) 对生成的代码进行运行时效率和可维护性的定量测量。
关键创新:论文的关键创新在于系统性地评估了多个LLMs在ABM代码生成任务中的表现,并提出了一个综合性的评估框架,包括可执行性检查、统计比较和性能评估。与以往的研究相比,论文更加关注LLMs生成代码的科学性和可靠性,而不仅仅是代码的可执行性。
关键设计:论文的关键设计包括:1) 使用ODD规范作为LLMs的输入,保证了输入的标准化和完整性;2) 使用模型无关的统计比较方法,避免了对特定实现的依赖;3) 采用运行时效率和可维护性的定量测量,全面评估LLMs生成代码的质量;4) 选择PPHPC模型作为案例,因为它具有完整的ODD规范和经过验证的NetLogo实现,方便进行对比。
🖼️ 关键图片
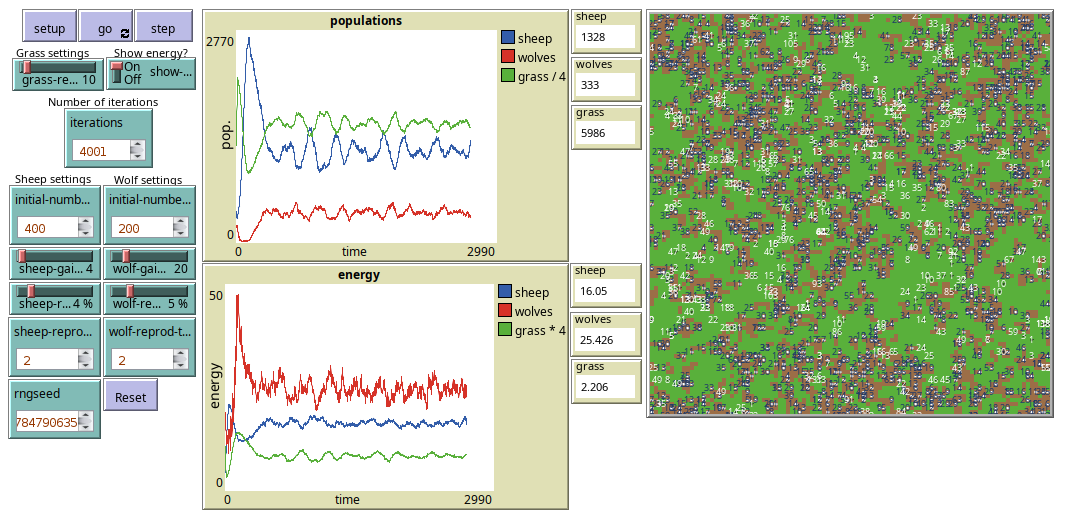


📊 实验亮点
实验结果表明,GPT-4.1在生成行为一致且高效的Agent-Based模型代码方面表现最佳,Claude 3.7 Sonnet表现良好但稳定性稍逊。研究强调,仅代码可执行性不足以保证科学有效性,需进行严格的统计验证。实验揭示了LLM在ABM代码生成中的潜力与局限。
🎯 应用场景
该研究成果可应用于Agent-Based建模、环境建模、社会模拟等领域,通过自动化代码生成降低建模门槛,加速模型开发迭代,并提高模型的可复现性和可靠性。未来可进一步探索LLM在复杂系统建模中的应用,例如城市交通、疫情传播等。
📄 摘要(原文)
Large language models (LLMs) can now synthesize non-trivial executable code from textual descriptions, raising an important question: can LLMs reliably implement agent-based models from standardized specifications in a way that supports replication, verification, and validation? We address this question by evaluating 17 contemporary LLMs on a controlled ODD-to-code translation task, using the PPHPC predator-prey model as a fully specified reference. Generated Python implementations are assessed through staged executability checks, model-independent statistical comparison against a validated NetLogo baseline, and quantitative measures of runtime efficiency and maintainability. Results show that behaviorally faithful implementations are achievable but not guaranteed, and that executability alone is insufficient for scientific use. GPT-4.1 consistently produces statistically valid and efficient implementations, with Claude 3.7 Sonnet performing well but less reliably. Overall, the findings clarify both the promise and current limitations of LLMs as model engineering tools, with implications for reproducible agent-based and environmental modelling.