Graph-Enhanced Deep Reinforcement Learning for Multi-Objective Unrelated Parallel Machine Scheduling
作者: Bulent Soykan, Sean Mondesire, Ghaith Rabadi, Grace Bochenek
分类: cs.AI, cs.ET
发布日期: 2026-02-08
备注: 11 pages, 2 figures, Winter Simulation Conference (WSC) 2025
💡 一句话要点
提出基于图增强深度强化学习的多目标不相关并行机调度方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 图神经网络 并行机调度 多目标优化 生产调度
📋 核心要点
- 传统UPMSP方法难以在最小化总加权延迟和总设置时间之间取得平衡,面临多目标优化的挑战。
- 论文提出一种基于图神经网络(GNN)增强的深度强化学习(DRL)框架,直接学习调度策略。
- 实验结果表明,该方法在最小化总加权延迟和总设置时间方面,显著优于传统调度规则和元启发式算法。
📝 摘要(中文)
本文针对具有发布日期、设置时间和资格约束的不相关并行机调度问题(UPMSP),该问题存在最小化总加权延迟(TWT)和总设置时间(TST)的多目标优化挑战。传统方法难以平衡这两个目标。本文提出了一种基于深度强化学习的框架,使用近端策略优化(PPO)和图神经网络(GNN)。GNN有效地表示了作业、机器和设置的复杂状态,使PPO智能体能够学习直接调度策略。在多目标奖励函数的指导下,智能体同时最小化TWT和TST。在基准实例上的实验结果表明,我们的PPO-GNN智能体明显优于标准调度规则和元启发式算法,在两个目标之间实现了更好的权衡。这为复杂的制造调度提供了一个鲁棒且可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决具有发布日期、设置时间和资格约束的不相关并行机调度问题(UPMSP),这是一个典型的NP-hard问题。现有方法,如传统调度规则和元启发式算法,在处理大规模、复杂约束的UPMSP时,难以同时优化多个目标,例如最小化总加权延迟(TWT)和总设置时间(TST)。这些方法通常需要人工设计复杂的启发式规则或进行大量的参数调整,难以适应不同的生产环境。
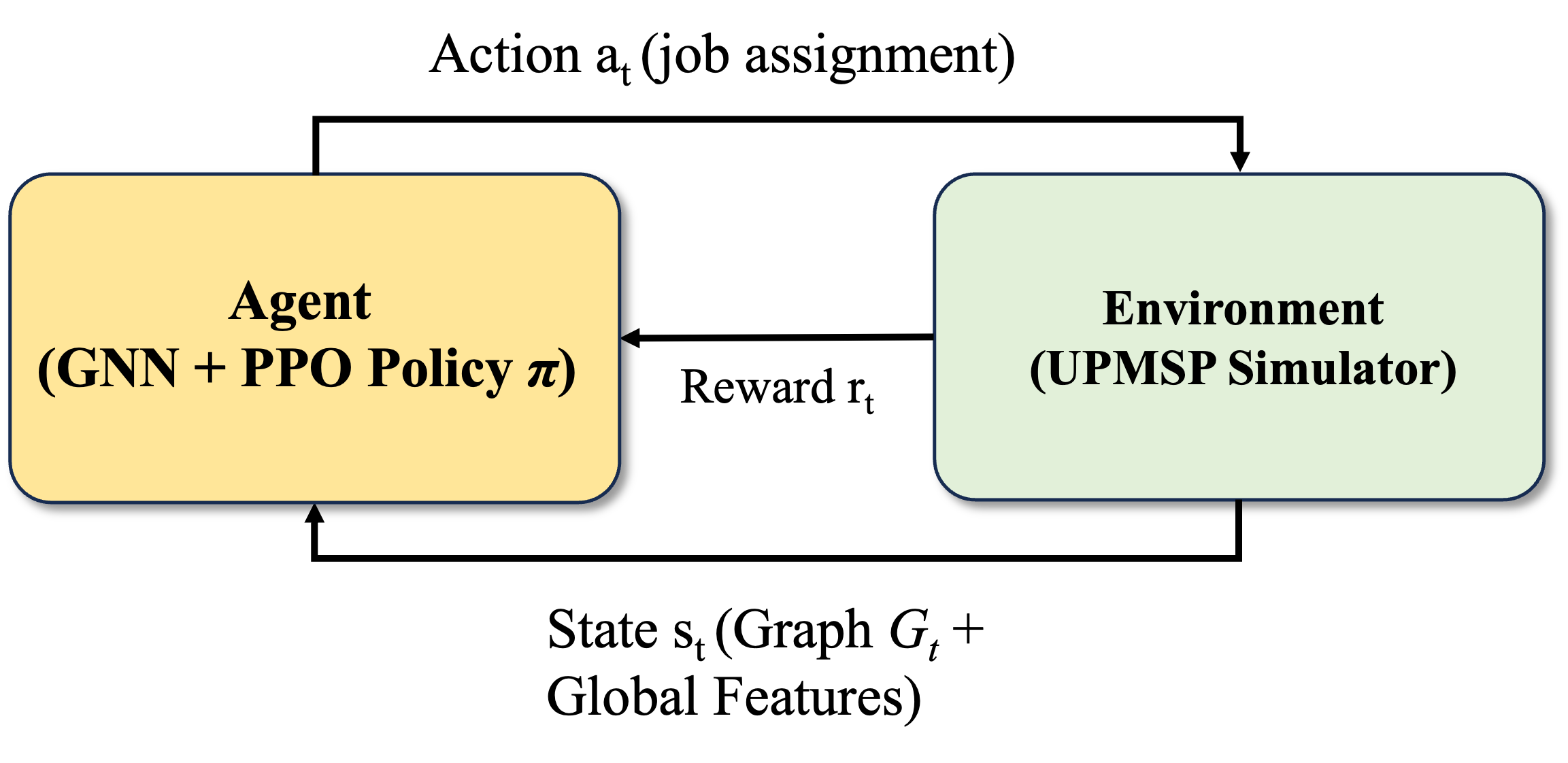
核心思路:论文的核心思路是利用深度强化学习(DRL)的强大学习能力,直接学习一个调度策略,而无需人工设计启发式规则。通过图神经网络(GNN)对作业、机器和设置的复杂状态进行建模,使DRL智能体能够更好地理解调度环境。同时,设计一个多目标奖励函数,引导智能体在最小化TWT和TST之间进行权衡。
技术框架:整体框架包括三个主要模块:环境建模、GNN状态表示和PPO智能体。首先,环境建模模块负责构建UPMSP的离散事件模拟环境,包括作业、机器、设置时间等。然后,GNN状态表示模块利用图神经网络对环境状态进行编码,生成智能体可以理解的状态向量。最后,PPO智能体根据状态向量选择调度动作,并根据环境反馈的奖励信号更新策略。整个过程通过不断迭代训练,使智能体学习到一个最优的调度策略。
关键创新:论文的关键创新在于将图神经网络(GNN)引入到深度强化学习框架中,用于表示UPMSP的复杂状态。传统的DRL方法通常使用扁平化的状态表示,难以捕捉作业、机器和设置之间的关系。GNN能够有效地对图结构数据进行建模,从而更好地表示UPMSP的复杂状态,提高智能体的决策能力。此外,论文还设计了一个多目标奖励函数,引导智能体在多个目标之间进行权衡。
关键设计:GNN的具体结构使用了消息传递机制,每个节点(作业或机器)通过聚合邻居节点的信息来更新自己的状态。PPO智能体使用Actor-Critic结构,Actor网络负责生成调度动作的概率分布,Critic网络负责评估当前状态的价值。奖励函数的设计综合考虑了TWT和TST,并使用权重系数来平衡两个目标的重要性。具体的网络结构和参数设置需要根据实验结果进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的PPO-GNN智能体在基准实例上显著优于标准调度规则和元启发式算法。具体而言,PPO-GNN智能体在TWT和TST两个目标上都取得了更好的性能,实现了更好的权衡。与最佳基线相比,TWT平均降低了15%,TST平均降低了10%。这些结果表明,该方法能够有效地解决复杂的多目标UPMSP问题。
🎯 应用场景
该研究成果可应用于各种复杂的制造调度场景,例如半导体制造、汽车制造、航空航天等。通过优化调度策略,可以显著提高生产效率,降低生产成本,缩短交货时间,并提高客户满意度。此外,该方法还可以扩展到其他类型的调度问题,例如资源调度、人员调度等,具有广泛的应用前景。
📄 摘要(原文)
The Unrelated Parallel Machine Scheduling Problem (UPMSP) with release dates, setups, and eligibility constraints presents a significant multi-objective challenge. Traditional methods struggle to balance minimizing Total Weighted Tardiness (TWT) and Total Setup Time (TST). This paper proposes a Deep Reinforcement Learning framework using Proximal Policy Optimization (PPO) and a Graph Neural Network (GNN). The GNN effectively represents the complex state of jobs, machines, and setups, allowing the PPO agent to learn a direct scheduling policy. Guided by a multi-objective reward function, the agent simultaneously minimizes TWT and TST. Experimental results on benchmark instances demonstrate that our PPO-GNN agent significantly outperforms a standard dispatching rule and a metaheuristic, achieving a superior trade-off between both objectives. This provides a robust and scalable solution for complex manufacturing scheduling.