Rethinking the Value of Agent-Generated Tests for LLM-Based Software Engineering Agents
作者: Zhi Chen, Zhensu Sun, Yuling Shi, Chao Peng, Xiaodong Gu, David Lo, Lingxiao Jiang
分类: cs.SE, cs.AI
发布日期: 2026-02-08
💡 一句话要点
揭示LLM代码Agent中Agent生成测试的价值:作用有限,需重新评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM代码Agent 软件工程 自动化测试 实证研究 Agent轨迹分析
📋 核心要点
- 现有LLM代码Agent在解决软件问题时,过度依赖Agent生成的测试,但其真实价值尚不明确。
- 通过分析Agent轨迹和控制实验,研究Agent生成测试对问题解决的影响,评估其有效性。
- 实验表明,Agent生成测试的频率与问题解决成功率无显著相关性,实际效用可能被高估。
📝 摘要(中文)
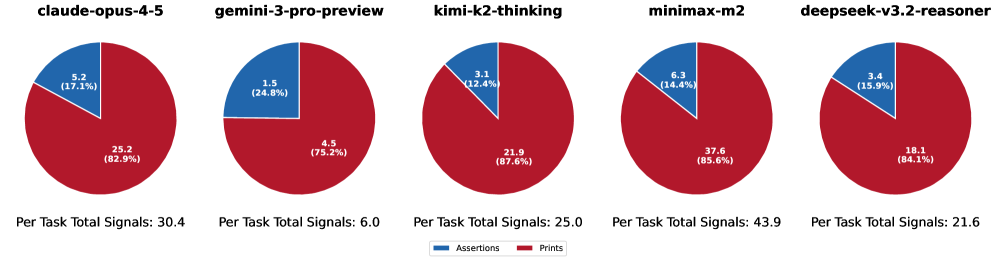
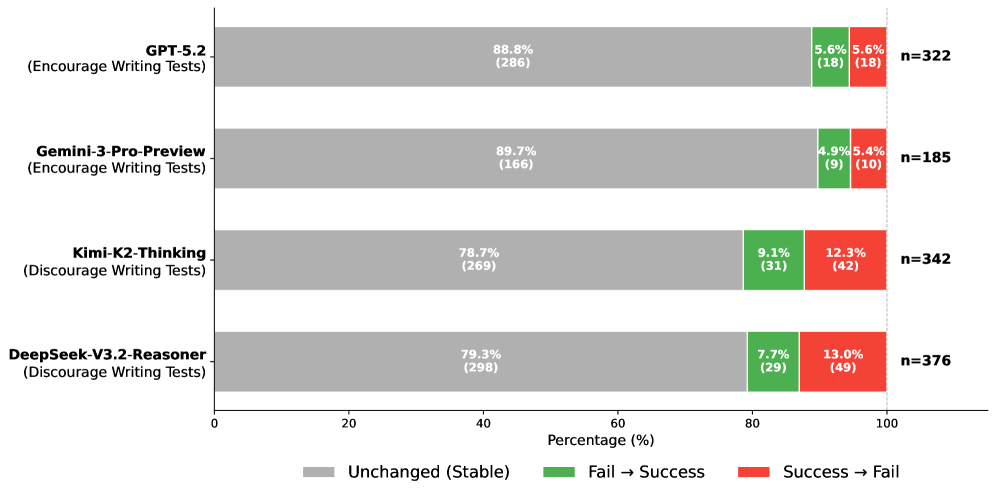
大型语言模型(LLM)代码Agent越来越多地通过迭代编辑代码、调用工具和验证候选补丁来解决仓库级别的问题。在这些工作流程中,Agent通常会动态编写测试,这种模式被SWE-bench排行榜上许多排名靠前的Agent采用。然而,我们观察到,几乎不编写新测试的GPT-5.2甚至可以达到与顶级Agent相当的性能。这就提出了一个关键问题:这些测试是否真正改善了问题解决,或者仅仅是模仿人类的测试实践,同时消耗了大量的交互预算。为了揭示Agent编写测试的影响,我们进行了一项实证研究,分析了SWE-bench Verified上六个最先进的LLM的Agent轨迹。我们的结果表明,虽然测试编写被广泛采用,但在同一模型中,已解决和未解决的任务表现出相似的测试编写频率。此外,这些测试通常作为观察反馈渠道,Agent更倾向于使用揭示数值的打印语句,而不是基于断言的正式检查。基于这些见解,我们通过修改四个Agent的提示来增加或减少测试编写,进行了一项对照实验。结果表明,Agent编写测试的数量变化并不会显著改变最终结果。总而言之,我们的研究表明,当前测试编写实践在自主软件工程任务中可能提供的效用有限。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)驱动的软件工程Agent在解决软件问题时,Agent自主生成的测试用例的实际价值。现有方法中,许多Agent倾向于生成大量的测试用例,但这些测试用例是否真正有助于问题解决,或者仅仅是增加了计算开销,缺乏深入研究。现有方法的痛点在于,对Agent生成测试的有效性缺乏量化分析,可能导致资源浪费和效率低下。
核心思路:论文的核心思路是通过实证研究和控制实验,分析Agent生成测试的频率、类型以及对问题解决的影响。通过比较不同Agent在解决问题时的测试生成行为,以及修改Agent的提示来控制测试生成量,从而评估测试生成对最终结果的影响。核心在于揭示Agent生成测试的真实价值,并为未来的Agent设计提供指导。
技术框架:论文采用的框架主要包括以下几个步骤:1) 数据收集:收集多个LLM Agent在SWE-bench Verified数据集上的运行轨迹,包括代码修改、工具调用和测试生成等信息。2) 行为分析:分析Agent生成测试的频率、类型(例如,断言测试与打印语句)以及与问题解决成功率之间的关系。3) 控制实验:通过修改Agent的提示,控制其生成测试的量,并比较不同测试生成量下的问题解决效果。4) 结果分析:对实验结果进行统计分析,评估Agent生成测试的实际价值。
关键创新:论文的关键创新在于对LLM Agent生成测试的有效性进行了系统的实证研究。与以往的研究不同,该论文不仅关注Agent生成测试的频率,还深入分析了测试的类型和对问题解决的影响。通过控制实验,论文揭示了Agent生成测试的实际价值可能被高估,为未来的Agent设计提供了新的视角。
关键设计:论文的关键设计包括:1) 选择SWE-bench Verified作为评估数据集,保证了评估的可靠性和可重复性。2) 设计了控制实验,通过修改Agent的提示来控制测试生成量,从而评估测试生成对问题解决的影响。3) 区分了不同类型的测试,例如断言测试和打印语句,从而更细致地分析了测试的有效性。4) 采用了统计分析方法,对实验结果进行了量化评估。
🖼️ 关键图片
📊 实验亮点
研究发现,Agent生成测试的频率与问题解决的成功率之间没有显著相关性。即使减少Agent生成测试的量,也不会显著降低问题解决的性能。GPT-5.2在几乎不编写新测试的情况下,也能达到与顶级Agent相当的性能,表明当前Agent生成测试的效用可能被高估。
🎯 应用场景
该研究成果可应用于改进LLM驱动的自动化软件工程工具。通过重新评估Agent生成测试的价值,可以优化Agent的设计,减少不必要的计算开销,提高问题解决效率。研究结果有助于开发更智能、更高效的自动化软件开发工具,加速软件开发流程。
📄 摘要(原文)
Large Language Model (LLM) code agents increasingly resolve repository-level issues by iteratively editing code, invoking tools, and validating candidate patches. In these workflows, agents often write tests on the fly, a paradigm adopted by many high-ranking agents on the SWE-bench leaderboard. However, we observe that GPT-5.2, which writes almost no new tests, can even achieve performance comparable to top-ranking agents. This raises the critical question: whether such tests meaningfully improve issue resolution or merely mimic human testing practices while consuming a substantial interaction budget. To reveal the impact of agent-written tests, we present an empirical study that analyzes agent trajectories across six state-of-the-art LLMs on SWE-bench Verified. Our results show that while test writing is commonly adopted, but resolved and unresolved tasks within the same model exhibit similar test-writing frequencies Furthermore, these tests typically serve as observational feedback channels, where agents prefer value-revealing print statements significantly more than formal assertion-based checks. Based on these insights, we perform a controlled experiment by revising the prompts of four agents to either increase or reduce test writing. The results suggest that changes in the volume of agent-written tests do not significantly change final outcomes. Taken together, our study reveals that current test-writing practices may provide marginal utility in autonomous software engineering tasks.