MemFly: On-the-Fly Memory Optimization via Information Bottleneck
作者: Zhenyuan Zhang, Xianzhang Jia, Zhiqin Yang, Zhenbo Song, Wei Xue, Sirui Han, Yike Guo
分类: cs.AI, cs.LG
发布日期: 2026-02-08
💡 一句话要点
MemFly:基于信息瓶颈的LLM即时记忆优化框架,提升长期记忆能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长期记忆 信息瓶颈 大语言模型 记忆优化 混合检索
📋 核心要点
- 现有LLM长期记忆框架难以兼顾信息压缩效率和下游任务检索精度,面临两难。
- MemFly基于信息瓶颈原则,通过优化压缩熵和相关性熵,实现LLM记忆的即时演化。
- 实验表明,MemFly在记忆连贯性、响应保真度和准确性方面均优于现有技术。
📝 摘要(中文)
本文提出MemFly,一个基于信息瓶颈原则的框架,用于大语言模型(LLM)的即时记忆演化。现有框架在高效压缩冗余信息和维持下游任务的精确检索之间面临根本困境。MemFly通过无梯度优化器最小化压缩熵,同时最大化相关性熵,从而构建分层记忆结构以实现高效存储。为了充分利用MemFly,我们开发了一种混合检索机制,无缝集成语义、符号和拓扑路径,并结合迭代细化来处理复杂的多跳查询。综合实验表明,MemFly在记忆连贯性、响应保真度和准确性方面显著优于最先进的基线方法。
🔬 方法详解
问题定义:现有大语言模型(LLM)的长期记忆框架在处理复杂任务时,面临着如何有效压缩冗余信息和保持精确检索能力之间的矛盾。简单地存储所有历史交互信息会导致记忆冗余和检索效率低下,而过度压缩则可能丢失关键信息,影响下游任务的性能。因此,如何构建一个既能高效存储又能精确检索的长期记忆系统是亟待解决的问题。
核心思路:MemFly的核心思路是利用信息瓶颈(Information Bottleneck, IB)原则来优化LLM的记忆。IB原则旨在找到一个信息表示,该表示既能最大程度地保留与下游任务相关的信息,又能最小化冗余信息。通过在记忆压缩过程中同时考虑相关性和压缩效率,MemFly能够构建一个更有效的分层记忆结构。
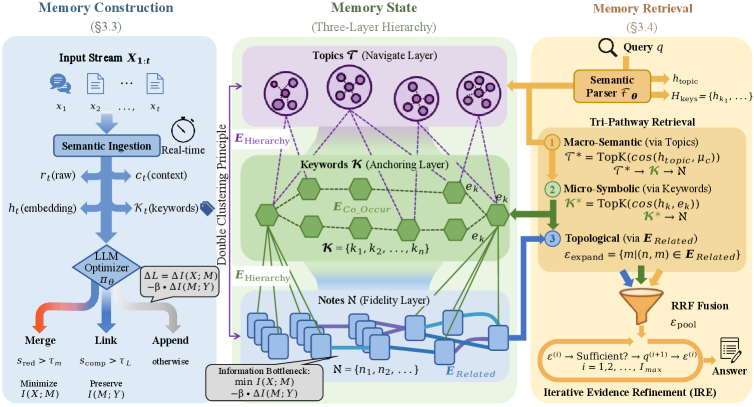
技术框架:MemFly框架主要包含三个核心模块:1) 记忆演化模块:该模块基于信息瓶颈原则,通过无梯度优化器来最小化压缩熵并最大化相关性熵,从而实现记忆的动态更新和压缩。2) 分层记忆结构:该结构将记忆划分为不同的层级,每一层级存储不同粒度的信息,以实现高效的存储和检索。3) 混合检索机制:该机制融合了语义、符号和拓扑三种检索路径,并采用迭代细化策略来处理复杂的多跳查询。
关键创新:MemFly的关键创新在于其基于信息瓶颈原则的即时记忆优化方法。与现有方法不同,MemFly不是简单地压缩或过滤记忆,而是通过优化压缩熵和相关性熵来动态地演化记忆。这种方法能够更好地平衡记忆的压缩效率和检索精度,从而提升LLM的长期记忆能力。此外,混合检索机制也能够更全面地利用记忆中的信息,提高检索的准确性。
关键设计:MemFly的关键设计包括:1) 使用无梯度优化器来优化信息瓶颈目标函数,避免了梯度计算的复杂性。2) 设计了分层记忆结构,以支持不同粒度的信息存储和检索。3) 提出了混合检索机制,融合了语义、符号和拓扑三种检索路径,并采用迭代细化策略来处理复杂查询。具体参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
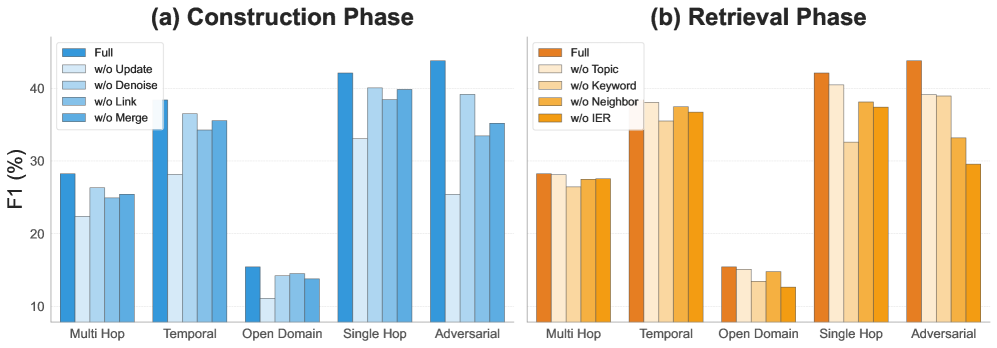
实验结果表明,MemFly在记忆连贯性、响应保真度和准确性方面均显著优于现有基线方法。具体性能数据和提升幅度在论文中进行了详细展示(未知)。这些结果验证了MemFly在提升LLM长期记忆能力方面的有效性。
🎯 应用场景
MemFly具有广泛的应用前景,例如可以应用于智能客服、对话系统、智能助手等需要长期记忆能力的场景。通过提升LLM的记忆连贯性、响应保真度和准确性,MemFly可以显著改善这些应用的用户体验。未来,MemFly还可以扩展到其他需要长期记忆的领域,例如机器人导航、智能规划等。
📄 摘要(原文)
Long-term memory enables large language model agents to tackle complex tasks through historical interactions. However, existing frameworks encounter a fundamental dilemma between compressing redundant information efficiently and maintaining precise retrieval for downstream tasks. To bridge this gap, we propose MemFly, a framework grounded in information bottleneck principles that facilitates on-the-fly memory evolution for LLMs. Our approach minimizes compression entropy while maximizing relevance entropy via a gradient-free optimizer, constructing a stratified memory structure for efficient storage. To fully leverage MemFly, we develop a hybrid retrieval mechanism that seamlessly integrates semantic, symbolic, and topological pathways, incorporating iterative refinement to handle complex multi-hop queries. Comprehensive experiments demonstrate that MemFly substantially outperforms state-of-the-art baselines in memory coherence, response fidelity, and accuracy.