Rethinking Latency Denial-of-Service: Attacking the LLM Serving Framework, Not the Model
作者: Tianyi Wang, Huawei Fan, Yuanchao Shu, Peng Cheng, Cong Wang
分类: cs.CR, cs.AI
发布日期: 2026-02-08
💡 一句话要点
提出针对LLM服务框架的Fill and Squeeze攻击,提升延迟拒绝服务攻击效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 延迟拒绝服务攻击 LLM服务框架 KV缓存 调度器攻击 侧信道攻击
📋 核心要点
- 现有算法复杂度攻击难以有效攻击现代LLM服务系统,因为系统级优化(如连续批处理)缓解了延迟影响。
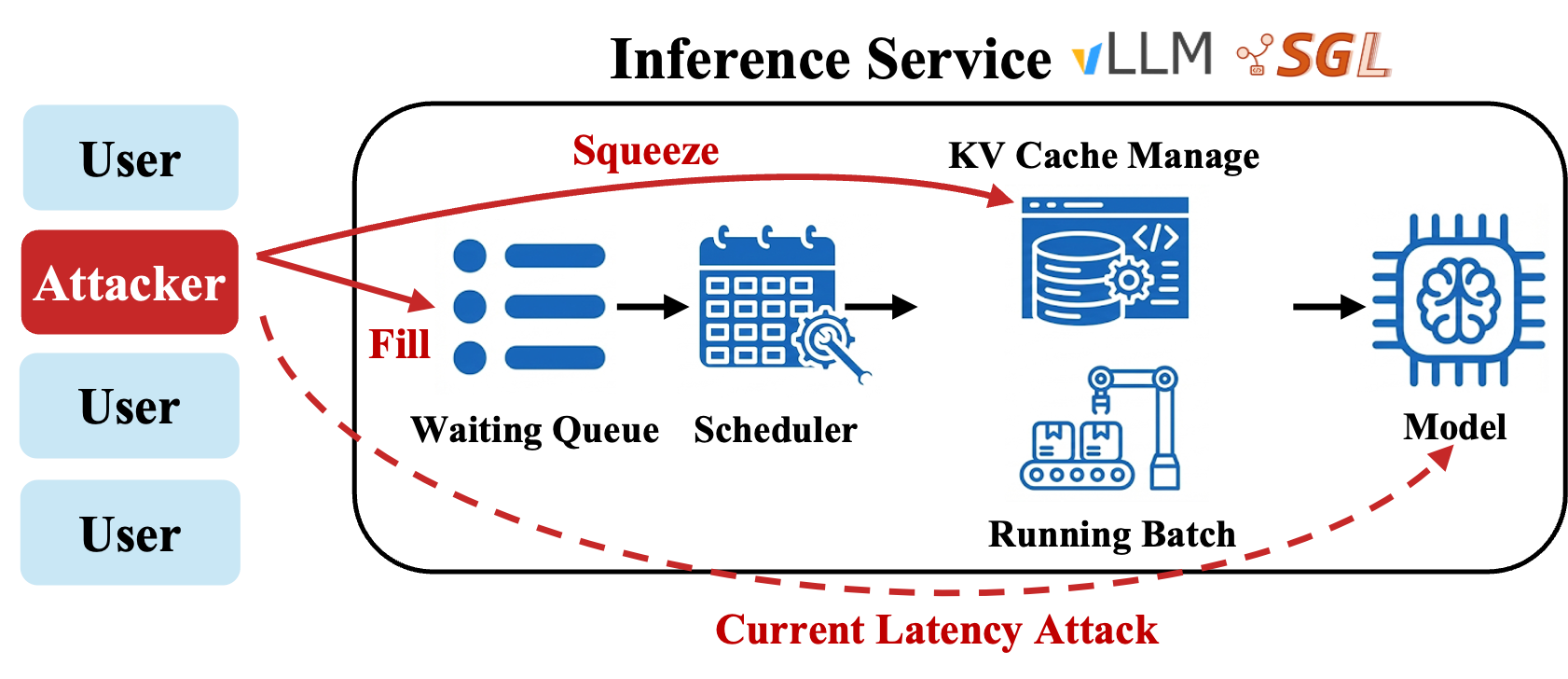
- 提出Fill and Squeeze攻击,通过耗尽KV缓存和诱导重复抢占,针对LLM服务框架的调度器状态转换。
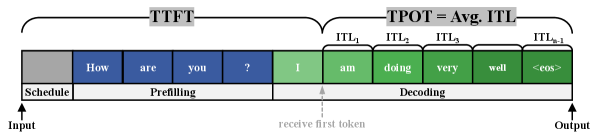
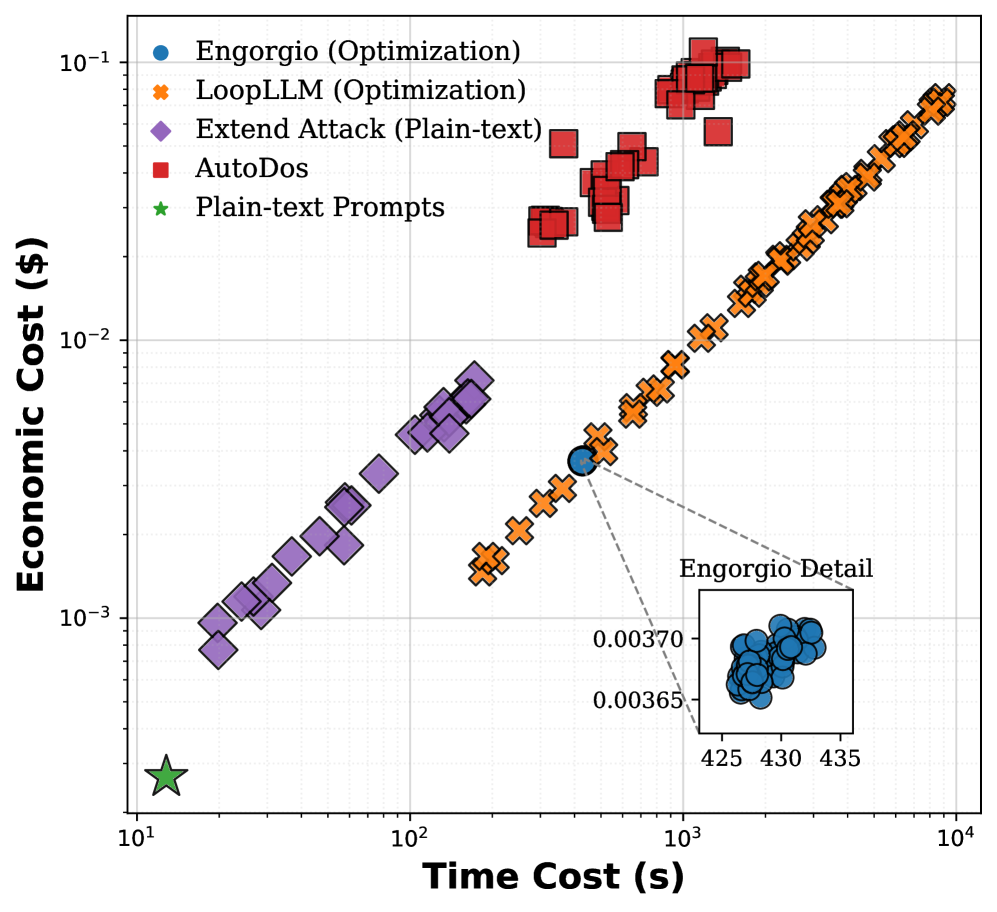
- 实验表明,该攻击在黑盒设置下,能以更低的成本实现比现有攻击高20-280倍的首次令牌时间减慢。
📝 摘要(中文)
大型语言模型面临着日益严峻的延迟攻击威胁。由于LLM推理本身计算成本高昂,即使是适度的延迟也会转化为巨大的运营成本和严重的服务可用性风险。最近的研究主要集中在通过构造输入来触发最坏情况输出长度的算法复杂度攻击。然而,本文发现这些算法延迟攻击对现代LLM服务系统基本无效。系统级的优化(如连续批处理)提供了逻辑隔离,以减轻对同地用户的传染性延迟影响。因此,本文将重点从算法转移到系统层,并提出了一种新的Fill and Squeeze攻击策略,针对调度器的状态转换。“Fill”首先耗尽全局KV缓存以诱导队头阻塞,而“Squeeze”迫使系统进入重复抢占。通过操纵输出长度(使用简单的纯文本提示到更复杂的提示工程方法)并利用内存状态的侧信道探测,证明了该攻击可以在黑盒设置中以更低的成本进行。大量评估表明,与现有攻击相比,首次令牌时间平均减慢20-280倍,每次输出令牌时间平均减慢1.5-4倍,且攻击成本降低30-40%。
🔬 方法详解
问题定义:现有针对LLM的延迟攻击主要集中在算法层面,通过构造特殊输入来触发模型生成过长的输出来实现拒绝服务。然而,现代LLM服务系统通常采用连续批处理等优化手段,使得算法层面的攻击效果大打折扣。因此,需要研究针对LLM服务框架本身的攻击方法,以实现更有效的延迟拒绝服务攻击。
核心思路:本文的核心思路是绕过模型本身,直接攻击LLM服务框架的调度器。通过控制请求的输出长度和利用内存状态的侧信道信息,攻击者可以操纵调度器的状态转换,使其进入一种低效的状态,从而影响其他用户的服务质量。具体来说,攻击分为两个阶段:Fill和Squeeze。
技术框架:该攻击框架主要包含以下几个阶段:1) 侧信道探测:利用侧信道信息(如内存占用率)来了解LLM服务框架的状态。2) Fill阶段:通过发送大量请求,耗尽全局KV缓存,从而导致后续请求的队头阻塞。3) Squeeze阶段:通过构造特定长度的输出,迫使系统频繁进行抢占,进一步降低服务效率。4) 攻击orchestration:根据侧信道探测的结果,动态调整Fill和Squeeze阶段的参数,以达到最佳攻击效果。
关键创新:该论文的关键创新在于将攻击目标从LLM模型本身转移到LLM服务框架的调度器。这种攻击方式能够绕过模型层面的防御机制,直接影响服务框架的性能。此外,利用侧信道信息进行攻击orchestration也提高了攻击的效率和隐蔽性。
关键设计:Fill阶段的关键在于控制请求的数量和输出长度,以确保KV缓存被有效耗尽。Squeeze阶段的关键在于构造特定长度的输出,使得系统在不同请求之间频繁切换,从而产生大量的抢占开销。攻击者可以使用简单的纯文本提示或更复杂的提示工程方法来控制输出长度。此外,侧信道探测的精度也会影响攻击效果,需要选择合适的探测指标和频率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Fill and Squeeze攻击能够显著降低LLM服务的性能。与现有攻击相比,首次令牌时间平均减慢20-280倍,每次输出令牌时间平均减慢1.5-4倍,且攻击成本降低30-40%。这些数据表明,该攻击方法具有很高的效率和实用性,对LLM服务安全构成了严重威胁。
🎯 应用场景
该研究成果可应用于评估和增强LLM服务框架的安全性。通过模拟Fill and Squeeze攻击,可以发现服务框架的潜在漏洞,并采取相应的防御措施,例如优化调度算法、增加KV缓存容量、实施更严格的资源隔离等。这有助于提高LLM服务的可用性和可靠性,保护用户免受恶意攻击的影响。
📄 摘要(原文)
Large Language Models face an emerging and critical threat known as latency attacks. Because LLM inference is inherently expensive, even modest slowdowns can translate into substantial operating costs and severe availability risks. Recently, a growing body of research has focused on algorithmic complexity attacks by crafting inputs to trigger worst-case output lengths. However, we report a counter-intuitive finding that these algorithmic latency attacks are largely ineffective against modern LLM serving systems. We reveal that system-level optimization such as continuous batching provides a logical isolation to mitigate contagious latency impact on co-located users. To this end, in this paper, we shift the focus from the algorithm to the system layer, and introduce a new Fill and Squeeze attack strategy targeting the state transition of the scheduler. "Fill" first exhausts the global KV cache to induce Head-of-Line blocking, while "Squeeze" forces the system into repetitive preemption. By manipulating output lengths using methods from simple plain-text prompts to more complex prompt engineering, and leveraging side-channel probing of memory status, we demonstrate that the attack can be orchestrated in a black-box setting with much less cost. Extensive evaluations indicate by up to 20-280x average slowdown on Time to First Token and 1.5-4x average slowdown on Time Per Output Token compared to existing attacks with 30-40% lower attack cost.