SAGE: Scalable AI Governance & Evaluation
作者: Benjamin Le, Xueying Lu, Nick Stern, Wenqiong Liu, Igor Lapchuk, Xiang Li, Baofen Zheng, Kevin Rosenberg, Jiewen Huang, Zhe Zhang, Abraham Cabangbang, Satej Milind Wagle, Jianqiang Shen, Raghavan Muthuregunathan, Abhinav Gupta, Mathew Teoh, Andrew Kirk, Thomas Kwan, Jingwei Wu, Wenjing Zhang
分类: cs.IR, cs.AI
发布日期: 2026-02-08 (更新: 2026-02-10)
💡 一句话要点
SAGE:可扩展的AI治理与评估框架,提升大规模搜索系统相关性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: AI治理 相关性评估 大型语言模型 师生蒸馏 搜索系统 自然语言策略 双向校准
📋 核心要点
- 大规模搜索系统相关性评估面临人工监督不足与生产系统高吞吐量需求的矛盾。
- SAGE框架通过双向校准循环,将人工判断转化为可扩展的评估信号,解决语义歧义。
- SAGE通过师生蒸馏降低推理成本,在LinkedIn搜索中提升了0.25%的日活用户。
📝 摘要(中文)
在大规模搜索系统中评估相关性,根本上受到细致入微、资源受限的人工监督与生产系统高吞吐量需求之间的治理差距的限制。传统方法依赖于参与度代理或稀疏的人工审查,但这些方法通常无法捕捉到高影响相关性失败的全部范围。我们提出了SAGE(Scalable AI Governance & Evaluation),一个将高质量的人工产品判断转化为可扩展评估信号的框架。SAGE的核心是一个双向校准循环,其中自然语言的“策略”、精心策划的“先例”和一个“LLM代理评判器”共同进化。SAGE系统地解决语义歧义和错位问题,将主观相关性判断转化为可执行的、多维度的规则,并达到接近人类水平的一致性。为了弥合前沿模型推理和工业规模推理之间的差距,我们应用师生蒸馏将高保真判断转移到成本降低92倍的紧凑型学生代理。SAGE在LinkedIn搜索生态系统中部署,通过模拟驱动的开发指导模型迭代,为在线服务提炼策略对齐的模型,并实现快速离线评估。在生产中,它支持策略监督,测量已提升的模型变体,并检测参与度指标无法发现的回归。总的来说,这些推动了LinkedIn每日活跃用户数提升0.25%。
🔬 方法详解
问题定义:论文旨在解决大规模搜索系统中相关性评估的治理问题。现有方法,如参与度代理或稀疏人工审查,无法全面捕捉高影响的相关性失败,导致模型迭代方向可能存在偏差。人工监督的成本高昂,难以满足生产系统的高吞吐量需求。
核心思路:论文的核心思路是将高质量的人工产品判断转化为可扩展的评估信号。通过构建一个双向校准循环,使自然语言策略、精心策划的先例和LLM代理评判器协同进化,从而系统地解决语义歧义和错位问题,将主观判断转化为可执行的多维度规则。
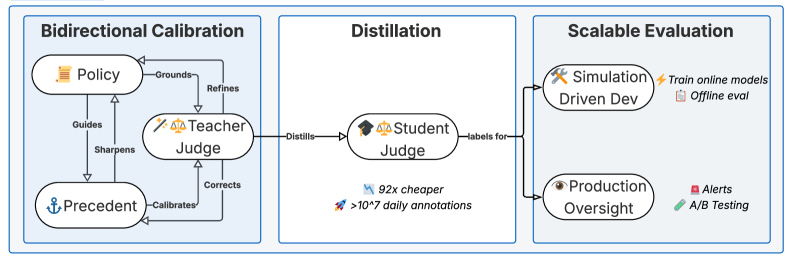
技术框架:SAGE框架包含以下主要模块:1) 策略(Policy):使用自然语言描述相关性判断的标准和规则。2) 先例(Precedent):人工标注的、符合或违反策略的具体案例。3) LLM代理评判器(LLM Surrogate Judge):使用大型语言模型作为代理,根据策略和先例对搜索结果进行判断。4) 双向校准循环:人工审查LLM代理评判器的判断结果,并更新策略和先例,从而不断提高LLM代理评判器的准确性和一致性。5) 师生蒸馏:将LLM代理评判器的高保真判断蒸馏到更小、更高效的学生模型中,以降低推理成本。
关键创新:SAGE的关键创新在于将人工判断、自然语言策略和大型语言模型结合起来,构建了一个可扩展的、高质量的相关性评估框架。与传统方法相比,SAGE能够更全面地捕捉相关性失败,并以更低的成本进行大规模评估。此外,双向校准循环的设计能够不断提高评估的准确性和一致性。
关键设计:论文中没有明确给出关键参数设置或损失函数的具体细节,但可以推断,LLM代理评判器的训练可能使用了对比学习或排序学习等方法,以提高其判断的准确性。师生蒸馏过程可能使用了知识蒸馏常用的损失函数,如KL散度损失或Hinton损失。策略和先例的质量对SAGE的性能至关重要,因此需要精心设计策略的表达方式和先例的选择标准。
🖼️ 关键图片
📊 实验亮点
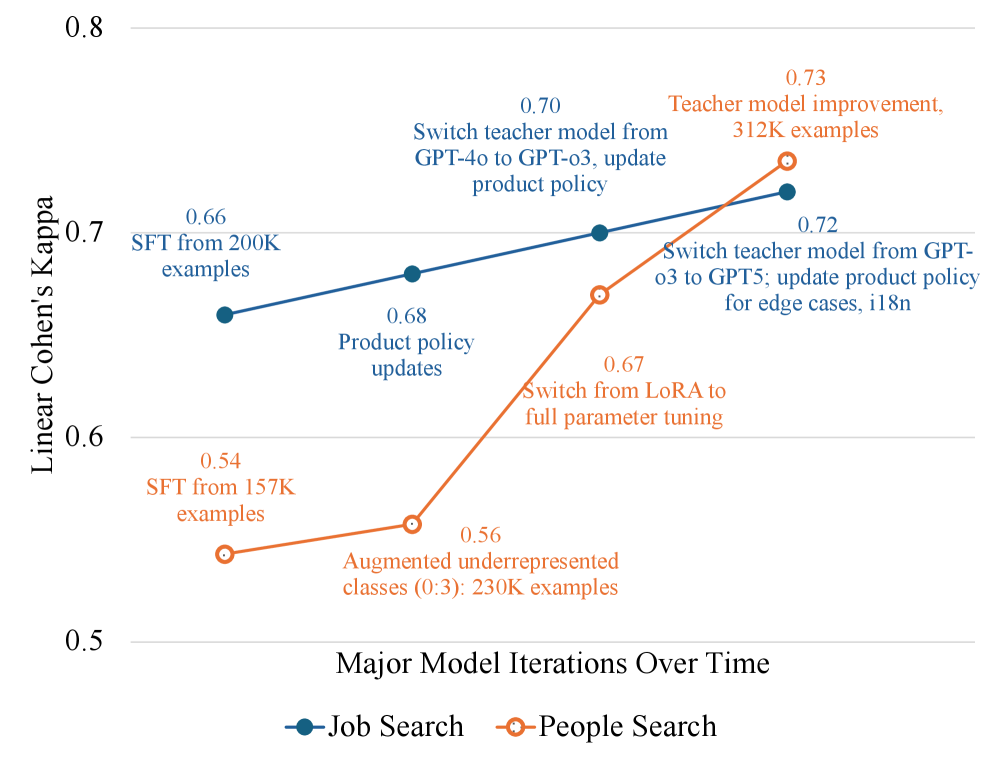
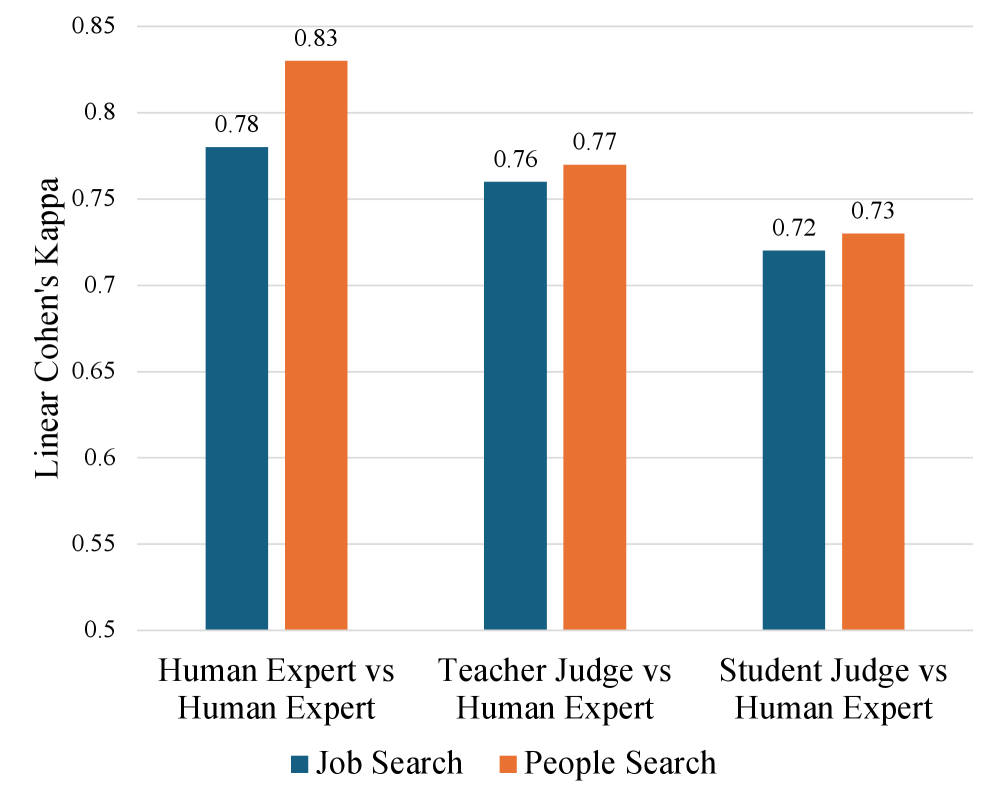
SAGE在LinkedIn搜索生态系统中部署后,通过模拟驱动的开发指导模型迭代,为在线服务提炼策略对齐的模型,并实现快速离线评估。在生产环境中,SAGE能够检测到参与度指标无法发现的回归,并最终推动LinkedIn每日活跃用户数提升0.25%。同时,通过师生蒸馏,SAGE将推理成本降低了92倍。
🎯 应用场景
SAGE框架可应用于各种需要大规模相关性评估的场景,例如搜索引擎、推荐系统、广告系统等。它可以帮助提高搜索结果、推荐内容和广告的相关性,从而提升用户体验和业务指标。此外,SAGE还可以用于模型监控和调试,及时发现和解决相关性问题。未来,SAGE可以扩展到其他领域,例如内容审核、风险控制等。
📄 摘要(原文)
Evaluating relevance in large-scale search systems is fundamentally constrained by the governance gap between nuanced, resource-constrained human oversight and the high-throughput requirements of production systems. While traditional approaches rely on engagement proxies or sparse manual review, these methods often fail to capture the full scope of high-impact relevance failures. We present \textbf{SAGE} (Scalable AI Governance \& Evaluation), a framework that operationalizes high-quality human product judgment as a scalable evaluation signal. At the core of SAGE is a bidirectional calibration loop where natural-language \emph{Policy}, curated \emph{Precedent}, and an \emph{LLM Surrogate Judge} co-evolve. SAGE systematically resolves semantic ambiguities and misalignments, transforming subjective relevance judgment into an executable, multi-dimensional rubric with near human-level agreement. To bridge the gap between frontier model reasoning and industrial-scale inference, we apply teacher-student distillation to transfer high-fidelity judgments into compact student surrogates at \textbf{92$\times$} lower cost. Deployed within LinkedIn Search ecosystems, SAGE guided model iteration through simulation-driven development, distilling policy-aligned models for online serving and enabling rapid offline evaluation. In production, it powered policy oversight that measured ramped model variants and detected regressions invisible to engagement metrics. Collectively, these drove a \textbf{0.25\%} lift in LinkedIn daily active users.