Time Series Reasoning via Process-Verifiable Thinking Data Synthesis and Scheduling for Tailored LLM Reasoning
作者: Jiahui Zhou, Dan Li, Boxin Li, Xiao Zhang, Erli Meng, Lin Li, Zhuomin Chen, Jian Lou, See-Kiong Ng
分类: cs.AI
发布日期: 2026-02-08
💡 一句话要点
VeriTime:通过可验证过程的思维数据合成与调度,为时序推理定制LLM
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列推理 大型语言模型 强化学习 数据合成 数据调度 链式思维 多模态学习
📋 核心要点
- 现有方法缺乏精心策划的时间序列CoT数据,数据效率低,且缺少为时序CoT数据定制的强化学习算法。
- VeriTime框架通过数据合成构建多模态数据集,设计数据调度机制,并采用两阶段强化微调来提升LLM的时序推理能力。
- 实验表明,VeriTime显著提升了LLM在多种时序推理任务上的性能,使小型模型达到或超过大型专有LLM的水平。
📝 摘要(中文)
时间序列是各种应用领域中普遍存在的数据类型,因此合理地解决各种时间序列任务是一个长期目标。大型语言模型(LLM)的最新进展,特别是通过强化学习(RL)解锁的推理能力,为处理具有长链式思维(CoT)推理的任务开辟了新的机会。然而,利用LLM进行时间序列推理仍处于起步阶段,这受到缺乏精心策划的用于训练的时间序列CoT数据、因数据调度未被充分探索而导致的数据效率有限,以及缺乏为利用此类时间序列CoT数据而定制的RL算法的阻碍。在本文中,我们介绍VeriTime,一个通过数据合成、数据调度和RL训练为时间序列推理定制LLM的框架。首先,我们提出了一个数据合成管道,该管道构建了一个具有过程可验证注释的TS-text多模态数据集。其次,我们设计了一种数据调度机制,该机制根据难度和任务分类的原则性层次结构来安排训练样本。第三,我们开发了一个两阶段强化微调,其特点是利用可验证的过程级CoT数据的细粒度、多目标奖励。大量的实验表明,VeriTime大大提高了LLM在各种时间序列推理任务中的性能。值得注意的是,它使紧凑的3B、4B模型能够实现与更大的专有LLM相当或超过的推理能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在时间序列推理任务中表现不佳的问题。现有方法面临三大痛点:一是缺乏高质量的时间序列链式思维(CoT)训练数据;二是数据调度策略不合理,导致数据利用率不高;三是缺乏专门为时间序列CoT数据设计的强化学习算法。
核心思路:VeriTime的核心思路是通过数据合成、数据调度和强化学习微调三个关键步骤,为LLM量身定制时间序列推理能力。数据合成解决了数据匮乏的问题,数据调度提高了训练效率,强化学习微调则进一步提升了模型的推理能力。
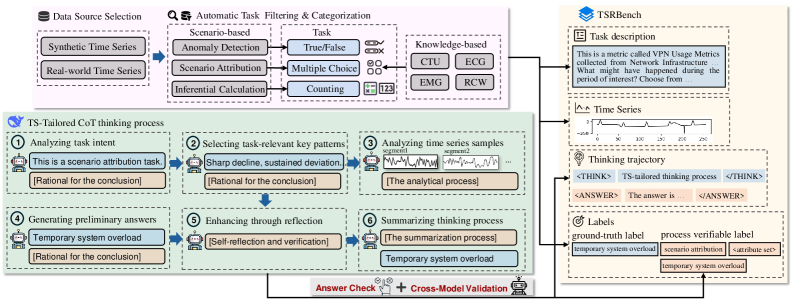
技术框架:VeriTime框架包含三个主要模块:1) 数据合成管道:用于构建TS-text多模态数据集,并提供过程可验证的标注信息。2) 数据调度机制:根据任务难度和类型,对训练样本进行分层排序,并按优先级进行训练。3) 两阶段强化微调:利用可验证的过程级CoT数据,设计细粒度的多目标奖励函数,对LLM进行强化学习微调。
关键创新:VeriTime的关键创新在于其端到端的时序推理LLM定制框架,特别是:1) 过程可验证的数据合成:确保生成的数据质量和可靠性。2) 基于难度和任务类型的数据调度:优化训练过程,提高数据利用率。3) 细粒度多目标强化学习:更有效地利用CoT数据,提升推理能力。
关键设计:在数据合成方面,采用了TS-text多模态数据生成方法,并对生成过程进行标注,以确保数据的可验证性。在数据调度方面,设计了基于难度和任务类型的分层调度策略,优先训练难度较高或重要的任务。在强化学习方面,设计了细粒度的多目标奖励函数,包括过程奖励和结果奖励,以引导模型学习正确的推理路径。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VeriTime显著提升了LLM在各种时间序列推理任务上的性能。例如,在某些任务上,使用VeriTime训练的3B或4B模型能够达到甚至超过大型专有LLM的性能水平。这表明VeriTime能够有效地利用数据和计算资源,提升LLM的时序推理能力。
🎯 应用场景
VeriTime框架可广泛应用于金融预测、医疗诊断、工业监控等领域。通过提升LLM在时间序列推理方面的能力,可以更准确地预测股票价格、诊断疾病、优化生产流程,从而带来巨大的经济和社会价值。未来,该研究有望推动LLM在更多时间序列相关领域的应用。
📄 摘要(原文)
Time series is a pervasive data type across various application domains, rendering the reasonable solving of diverse time series tasks a long-standing goal. Recent advances in large language models (LLMs), especially their reasoning abilities unlocked through reinforcement learning (RL), have opened new opportunities for tackling tasks with long Chain-of-Thought (CoT) reasoning. However, leveraging LLM reasoning for time series remains in its infancy, hindered by the absence of carefully curated time series CoT data for training, limited data efficiency caused by underexplored data scheduling, and the lack of RL algorithms tailored for exploiting such time series CoT data. In this paper, we introduce VeriTime, a framework that tailors LLMs for time series reasoning through data synthesis, data scheduling, and RL training. First, we propose a data synthesis pipeline that constructs a TS-text multimodal dataset with process-verifiable annotations. Second, we design a data scheduling mechanism that arranges training samples according to a principled hierarchy of difficulty and task taxonomy. Third, we develop a two-stage reinforcement finetuning featuring fine-grained, multi-objective rewards that leverage verifiable process-level CoT data. Extensive experiments show that VeriTime substantially boosts LLM performance across diverse time series reasoning tasks. Notably, it enables compact 3B, 4B models to achieve reasoning capabilities on par with or exceeding those of larger proprietary LLMs.