Geo-Code: A Code Framework for Reverse Code Generation from Geometric Images Based on Two-Stage Multi-Agent Evolution
作者: Zhenyu Wu, Yanxi Long, Jian Li, Hua Huang
分类: cs.AI
发布日期: 2026-02-08
备注: ICML2026
💡 一句话要点
Geo-Code:基于多智能体演化的几何图像逆向代码生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 逆向代码生成 几何图像 多智能体系统 视觉反馈 多模态推理 几何建模 代码演化 程序代码
📋 核心要点
- 现有逆向图形方法难以精确重建复杂几何细节,导致关键几何约束丢失或结构扭曲。
- Geo-Code通过像素级锚定进行几何建模,并引入合成-渲染-验证闭环,利用双向视觉反馈驱动代码自校正。
- 实验表明,Geo-Code在几何重建精度和视觉一致性方面显著领先,重建图像在多模态推理任务中与原图性能相当。
📝 摘要(中文)
本文提出Geo-Code,一种基于多智能体系统的几何图像逆向编程框架,旨在解决现有逆向图形方法在精确重建复杂几何细节方面的挑战,这些方法常常导致关键几何约束的丢失或结构扭曲。Geo-Code创新性地将过程解耦为:第一阶段,通过像素级锚定进行几何建模,利用视觉算子和大模型的互补优势,精确捕获像素坐标和视觉属性;第二阶段,引入合成-渲染-验证的闭环,通过双向视觉反馈驱动代码的自我校正。实验表明,Geo-Code在几何重建精度和视觉一致性方面均取得了显著领先。重建图像在多模态推理任务中表现出与原始图像相当的性能,验证了框架的鲁棒性。此外,本文开源了基于GeoCode框架构建的包含超过1500个样本的Geo-coder数据集和GeocodeLM模型。
🔬 方法详解
问题定义:论文旨在解决从几何图像中逆向生成程序代码的问题。现有方法在处理复杂几何图形时,难以精确捕捉几何细节,导致重建后的图像丢失关键的几何约束或出现结构性扭曲。这限制了这些方法在需要精确几何信息的应用场景中的使用,例如多模态推理。
核心思路:Geo-Code的核心思路是将逆向代码生成过程分解为两个阶段:几何建模和代码演化。几何建模阶段负责精确地提取图像中的几何信息,代码演化阶段则负责根据这些信息生成相应的程序代码。通过这种解耦,可以更好地利用视觉算子和大模型的优势,并引入视觉反馈机制来不断优化生成的代码。
技术框架:Geo-Code框架包含两个主要阶段: 1. 几何建模阶段:利用视觉算子和大模型,通过像素级锚定来精确捕获图像中的像素坐标和视觉属性。 2. 代码演化阶段:引入一个合成-渲染-验证的闭环。在这个闭环中,生成的代码会被渲染成图像,然后与原始图像进行比较。根据比较结果,利用双向视觉反馈来驱动代码的自我校正。
关键创新:Geo-Code的关键创新在于其多智能体演化框架,该框架通过解耦几何建模和代码演化,并引入视觉反馈机制,实现了对复杂几何图像的精确逆向代码生成。与现有方法相比,Geo-Code能够更好地保留图像中的几何语义,从而提高重建图像在多模态推理任务中的性能。
关键设计: * 像素级锚定:使用视觉算子和大模型来精确捕获图像中的像素坐标和视觉属性。 * 合成-渲染-验证闭环:通过不断地合成、渲染和验证生成的代码,利用视觉反馈来驱动代码的自我校正。 * 多智能体系统:使用多个智能体协同工作,每个智能体负责不同的任务,例如几何建模、代码生成和代码验证。
🖼️ 关键图片
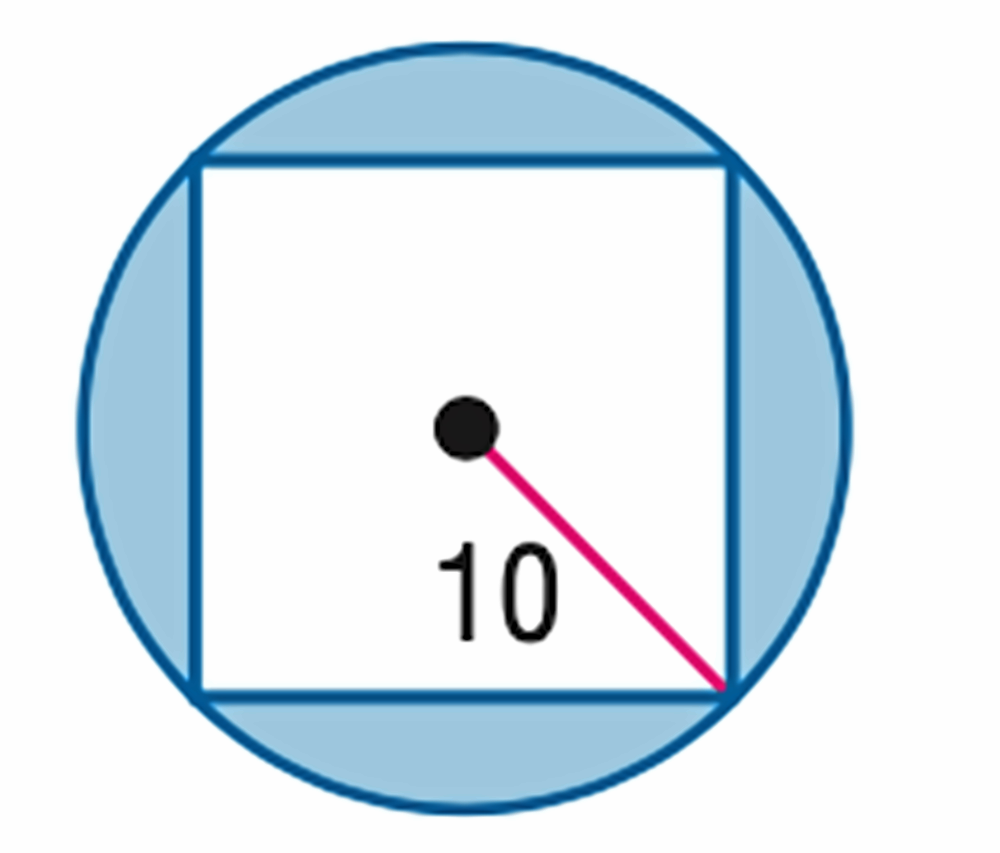
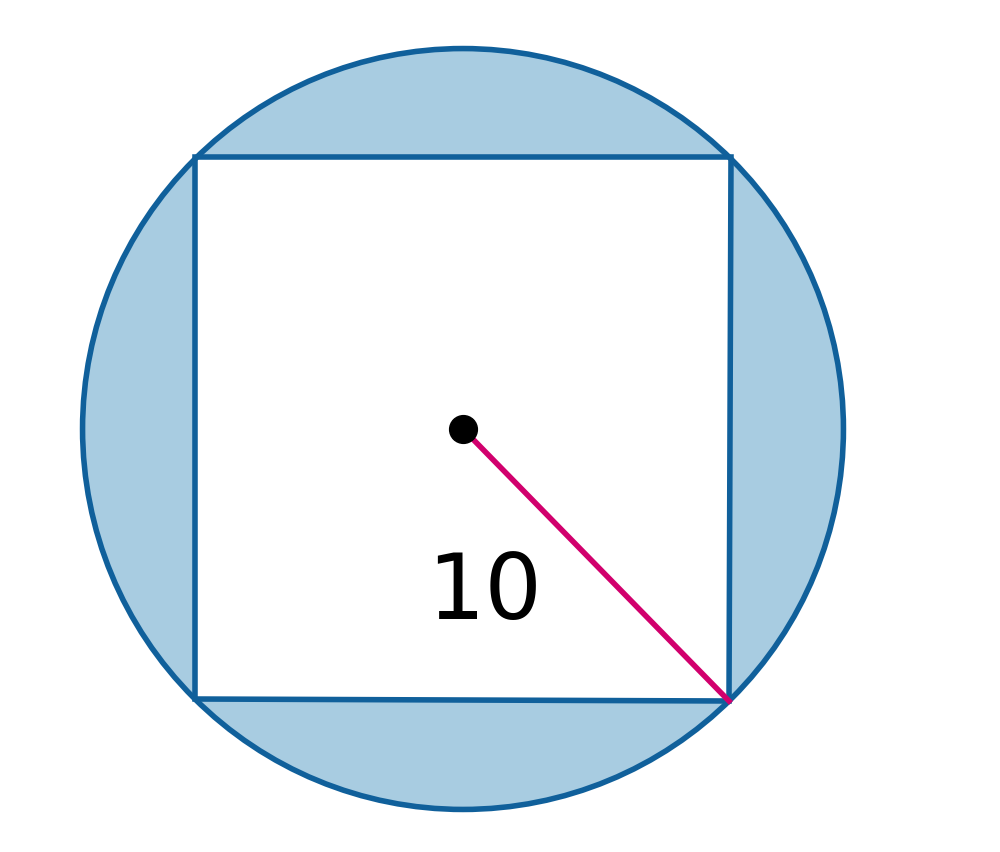
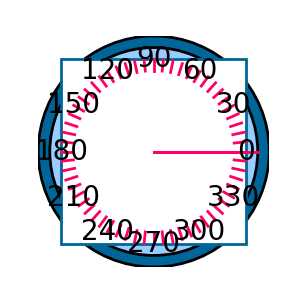
📊 实验亮点
实验结果表明,Geo-Code在几何重建精度和视觉一致性方面均取得了显著领先。重建图像在多模态推理任务中表现出与原始图像相当的性能,验证了框架的鲁棒性。此外,论文还开源了包含超过1500个样本的Geo-coder数据集和GeocodeLM模型,为后续研究提供了数据和模型基础。
🎯 应用场景
Geo-Code在多模态推理、视觉内容编辑、几何图形理解等领域具有广泛的应用前景。它可以用于增强大型模型的多模态推理能力,实现基于几何约束的图像编辑,以及提高计算机对几何图形的理解能力。此外,该框架还可以应用于教育领域,帮助学生更好地理解几何概念。
📄 摘要(原文)
Program code serves as a bridge linking vision and logic, providing a feasible supervisory approach for enhancing the multimodal reasoning capability of large models through geometric operations such as auxiliary line construction and perspective transformation. Nevertheless, current inverse graphics methods face tremendous challenges in accurately reconstructing complex geometric details, which often results in the loss of key geometric constraints or structural distortion. To address this bottleneck, we propose Geo-coder -- the first inverse programming framework for geometric images based on a multi-agent system. Our method innovatively decouples the process into geometric modeling via pixel-wise anchoring and metric-driven code evolution: Stage 1 leverages the complementary advantages of visual operators and large models to achieve precise capture of pixel coordinates and visual attributes; Stage 2 introduces a synthesis-rendering-validation closed loop, where bidirectional visual feedback drives the self-correction of code. Extensive experiments demonstrate that Geo-coder achieves a substantial lead in both geometric reconstruction accuracy and visual consistency. Notably, by effectively preserving the core geometric semantics, the images reconstructed with our method exhibit equivalent performance to the original ones in multimodal reasoning tasks, which fully validates the robustness of the framework. Finally, to further reduce research costs, we have open-sourced the Geo-coder dataset constructed on the GeoCode framework, which contains more than 1,500 samples. On this basis, we have also open-sourced the GeocodeLM model, laying a solid data and model foundation for subsequent research in this field.