Reverse-Engineering Model Editing on Language Models
作者: Zhiyu Sun, Minrui Luo, Yu Wang, Zhili Chen, Tianxing He
分类: cs.CR, cs.AI, cs.CL
发布日期: 2026-02-07
🔗 代码/项目: GITHUB
💡 一句话要点
揭示模型编辑漏洞:提出KSTER攻击以逆向工程语言模型编辑数据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 模型编辑 逆向工程 侧信道攻击 安全性 隐私保护
📋 核心要点
- 现有模型编辑方法存在漏洞,参数更新会泄露编辑数据,攻击者可利用此侧信道恢复敏感信息。
- 提出KSTER攻击,利用更新矩阵的低秩结构,通过密钥空间重建和熵减少两阶段恢复编辑数据。
- 实验证明KSTER攻击能高成功率恢复编辑数据,并提出子空间伪装防御策略,有效降低重建风险。
📝 摘要(中文)
大型语言模型(LLMs)在包含数万亿token的语料库上进行预训练,不可避免地会记忆敏感信息。定位-编辑方法作为模型编辑的主流范式,通过修改模型参数而无需重新训练,提供了一种有希望的解决方案。然而,本文揭示了这种范式的一个关键漏洞:参数更新无意中充当了侧信道,使攻击者能够恢复编辑后的数据。我们提出了一种名为KSTER(密钥空间重建-然后-熵减少)的两阶段逆向工程攻击,该攻击利用了这些更新的低秩结构。首先,我们从理论上证明了更新矩阵的行空间编码了编辑对象的“指纹”,从而可以通过谱分析准确地恢复对象。其次,我们引入了一种基于熵的提示恢复攻击,该攻击重建了编辑的语义上下文。在多个LLM上的大量实验表明,我们的攻击可以高成功率地恢复编辑后的数据。此外,我们提出了一种名为子空间伪装的防御策略,该策略使用语义诱饵来混淆更新指纹。这种方法有效地降低了重建风险,而不会影响编辑效用。我们的代码可在https://github.com/reanatom/EditingAtk.git上找到。
🔬 方法详解
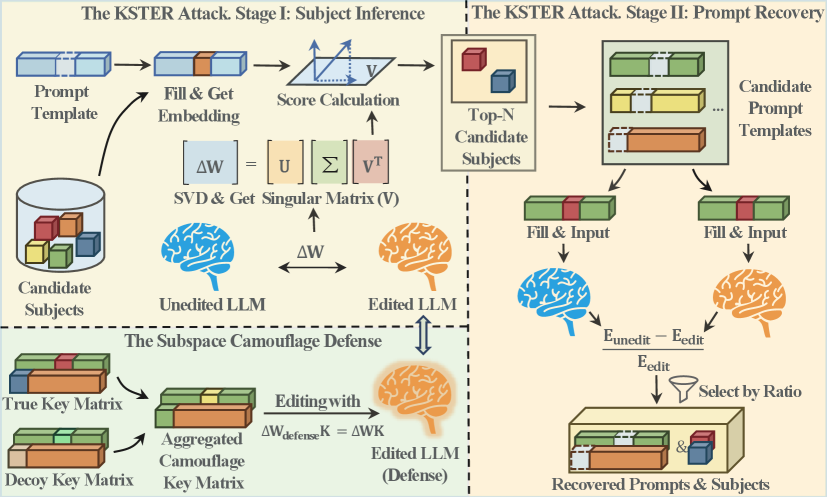
问题定义:论文旨在解决大型语言模型(LLMs)中模型编辑操作的安全性问题。现有的模型编辑方法,如locate-then-edit,虽然能够在不重新训练模型的情况下修改模型参数,但其参数更新过程存在安全隐患,可能被攻击者利用来恢复编辑过的数据。这种数据泄露风险是现有方法的痛点。
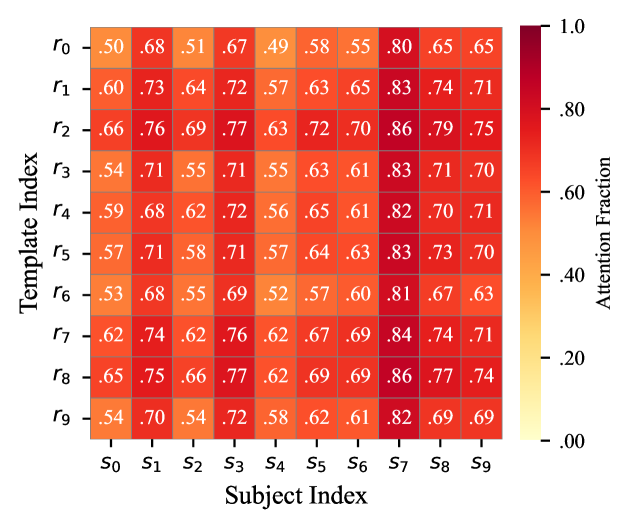
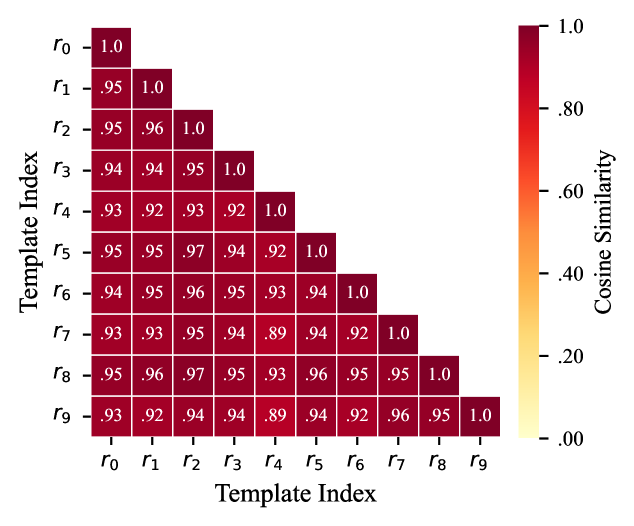
核心思路:论文的核心思路是利用模型编辑过程中参数更新的低秩特性,将其视为一种侧信道,通过分析这些更新来逆向工程出被编辑的数据。具体来说,更新矩阵的行空间包含了编辑对象的“指纹”,而编辑的语义上下文可以通过熵减少的方法进行重建。
技术框架:KSTER攻击包含两个主要阶段:密钥空间重建(KeySpaceReconstruction)和熵减少(EntropyReduction)。在密钥空间重建阶段,通过谱分析提取更新矩阵行空间的特征向量,从而恢复编辑对象。在熵减少阶段,利用恢复的编辑对象作为提示,通过迭代优化降低提示的熵,从而重建编辑的语义上下文。
关键创新:该论文的关键创新在于发现了模型编辑操作的参数更新过程可以作为侧信道被利用,并提出了相应的攻击方法KSTER。KSTER攻击能够有效地利用更新矩阵的低秩结构,通过谱分析和熵减少来恢复编辑数据。此外,论文还提出了一种防御策略,即子空间伪装,通过添加语义诱饵来混淆更新指纹。
关键设计:KSTER攻击的关键设计包括:1) 利用奇异值分解(SVD)进行谱分析,提取更新矩阵行空间的主要特征向量;2) 设计基于熵的提示恢复算法,通过迭代优化降低提示的熵,从而重建编辑的语义上下文;3) 提出子空间伪装防御策略,通过添加语义诱饵来混淆更新指纹,具体实现方式未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,KSTER攻击在多个LLM上能够以高成功率恢复编辑后的数据。具体性能数据未知,但论文强调了攻击的有效性。此外,提出的子空间伪装防御策略能够有效降低重建风险,而不会显著影响编辑效用。这些实验结果验证了攻击的威胁性和防御策略的有效性。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,尤其是在模型编辑场景下。通过揭示模型编辑的漏洞,可以促进更安全的模型编辑方法的设计,保护用户隐私和敏感信息,避免恶意攻击者利用模型编辑进行数据窃取或篡改。该研究对提升AI系统的可靠性和安全性具有重要意义。
📄 摘要(原文)
Large language models (LLMs) are pretrained on corpora containing trillions of tokens and, therefore, inevitably memorize sensitive information. Locate-then-edit methods, as a mainstream paradigm of model editing, offer a promising solution by modifying model parameters without retraining. However, in this work, we reveal a critical vulnerability of this paradigm: the parameter updates inadvertently serve as a side channel, enabling attackers to recover the edited data. We propose a two-stage reverse-engineering attack named \textit{KSTER} (\textbf{K}ey\textbf{S}paceRecons\textbf{T}ruction-then-\textbf{E}ntropy\textbf{R}eduction) that leverages the low-rank structure of these updates. First, we theoretically show that the row space of the update matrix encodes a ``fingerprint" of the edited subjects, enabling accurate subject recovery via spectral analysis. Second, we introduce an entropy-based prompt recovery attack that reconstructs the semantic context of the edit. Extensive experiments on multiple LLMs demonstrate that our attacks can recover edited data with high success rates. Furthermore, we propose \textit{subspace camouflage}, a defense strategy that obfuscates the update fingerprint with semantic decoys. This approach effectively mitigates reconstruction risks without compromising editing utility. Our code is available at https://github.com/reanatom/EditingAtk.git.