Debugging code world models
作者: Babak Rahmani
分类: cs.SE, cs.AI, cs.LG, cs.PL, cs.SC
发布日期: 2026-02-07 (更新: 2026-02-14)
备注: 8 pages, 4 figures, under review in conference
💡 一句话要点
研究代码世界模型的错误根源,提出改进监督和状态表示的建议。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码世界模型 程序执行 运行时状态 长时程推理 Transformer模型
📋 核心要点
- 代码世界模型在模拟程序执行时面临挑战,尤其是在处理长序列和复杂数据类型时。
- 该研究通过分析局部语义执行和长时程状态跟踪,揭示了CWMs的两种主要失败模式。
- 实验表明,token预算耗尽和字符串状态处理不当是主要瓶颈,为改进CWMs提供了方向。
📝 摘要(中文)
代码世界模型(CWMs)是一种通过预测每次执行命令后的显式运行时状态来模拟程序执行的语言模型。这种基于执行的世界建模实现了模型内部的验证,为自然语言的思维链推理提供了一种替代方案。然而,错误的来源和CWMs局限性的本质仍然知之甚少。我们从两个互补的角度研究CWMs:局部语义执行和长时程状态跟踪。在真实代码基准测试中,我们确定了两种主要的失败模式。首先,密集的运行时状态会产生token密集的执行轨迹,导致具有长执行历史的程序耗尽token预算。其次,失败不成比例地集中在字符串值状态中,我们将其归因于子词token化的局限性,而不是程序结构。为了研究长时程行为,我们使用了一个受控的排列跟踪基准,该基准隔离了动作执行下的状态传播。我们表明,长时程退化主要由不正确的动作生成驱动:当动作被替换为ground-truth命令时,基于Transformer的CWM可以在长时程上准确地传播状态,尽管Transformer在长时程状态跟踪方面存在已知局限性。这些发现为CWMs中更有效的监督和状态表示指明了方向,这些监督和状态表示与程序执行和数据类型更好地对齐。
🔬 方法详解
问题定义:代码世界模型(CWMs)旨在通过预测程序执行的每一步的运行时状态来模拟程序执行。现有的CWMs在处理具有长执行历史的程序时,由于token预算的限制,以及在处理字符串类型的数据时,由于子词token化的局限性,表现出明显的不足。这些问题限制了CWMs在复杂程序理解和调试方面的应用。
核心思路:该研究的核心思路是通过深入分析CWMs在局部语义执行和长时程状态跟踪两个方面的表现,来识别其错误的根本原因。通过有针对性地分析CWMs在不同类型程序和不同执行阶段的失败模式,从而为改进CWMs的架构和训练方法提供指导。
技术框架:该研究的技术框架主要包括两个部分:一是局部语义执行分析,通过在真实代码基准上运行CWMs,并分析其在每一步执行中的错误;二是长时程状态跟踪分析,通过设计一个受控的排列跟踪基准,来评估CWMs在长时间序列上的状态传播能力。通过这两个部分的分析,可以全面了解CWMs的优缺点。
关键创新:该研究的关键创新在于,它揭示了CWMs在处理长序列和字符串类型数据时的局限性,并将其归因于token预算的限制和子词token化的不足。此外,该研究还发现,CWMs的长时程退化主要由不正确的动作生成驱动,而不是Transformer本身的长时程状态跟踪能力。
关键设计:在局部语义执行分析中,研究人员使用了真实的代码基准,并仔细分析了CWMs在不同类型的程序和不同执行阶段的错误。在长时程状态跟踪分析中,研究人员设计了一个受控的排列跟踪基准,通过替换ground-truth命令来评估CWMs的状态传播能力。这些设计使得研究人员能够准确地识别CWMs的局限性,并为改进CWMs提供了有价值的见解。
🖼️ 关键图片

📊 实验亮点
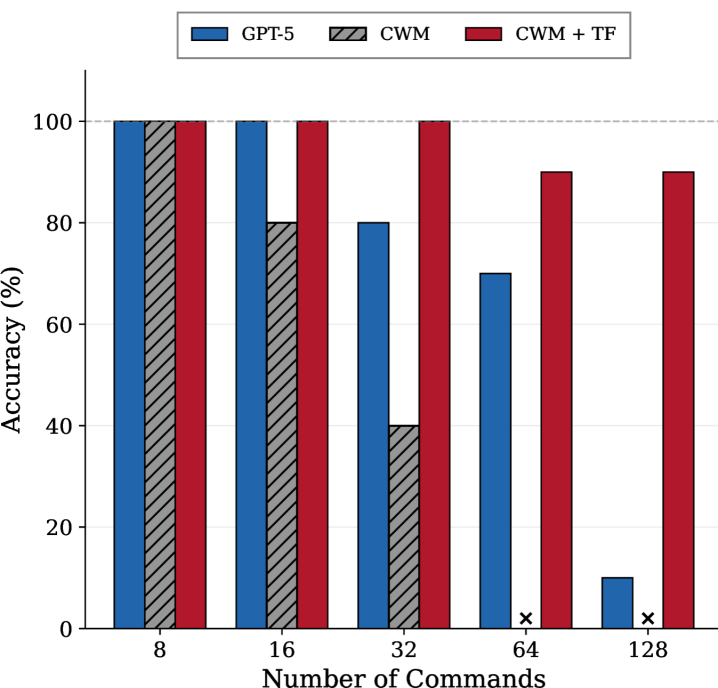
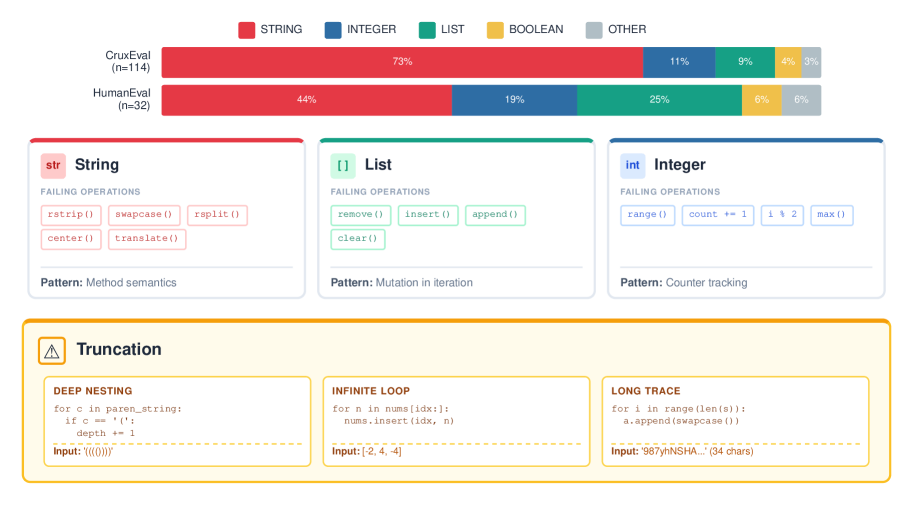
研究表明,CWMs在处理具有长执行历史的程序时,会因token预算耗尽而失败。此外,CWMs在处理字符串值状态时表现不佳,这归因于子词token化的局限性。当使用ground-truth命令时,基于Transformer的CWM可以在长时程上准确地传播状态,表明动作生成是长时程退化的主要原因。
🎯 应用场景
该研究成果可应用于程序自动调试、代码理解和生成等领域。通过改进代码世界模型的监督方式和状态表示,可以提高其在复杂程序中的推理能力,从而帮助开发者更高效地进行软件开发和维护。未来的研究可以探索更有效的token化方法和更适合程序执行的状态表示方式。
📄 摘要(原文)
Code World Models (CWMs) are language models trained to simulate program execution by predicting explicit runtime state after every executed command. This execution-based world modeling enables internal verification within the model, offering an alternative to natural language chain-of-thought reasoning. However, the sources of errors and the nature of CWMs' limitations remain poorly understood. We study CWMs from two complementary perspectives: local semantic execution and long-horizon state tracking. On real-code benchmarks, we identify two dominant failure regimes. First, dense runtime state reveals produce token-intensive execution traces, leading to token-budget exhaustion on programs with long execution histories. Second, failures disproportionately concentrate in string-valued state, which we attribute to limitations of subword tokenization rather than program structure. To study long-horizon behavior, we use a controlled permutation-tracking benchmark that isolates state propagation under action execution. We show that long-horizon degradation is driven primarily by incorrect action generation: when actions are replaced with ground-truth commands, a Transformer-based CWM propagates state accurately over long horizons, despite known limitations of Transformers in long-horizon state tracking. These findings suggest directions for more efficient supervision and state representations in CWMs that are better aligned with program execution and data types.