Agent-Fence: Mapping Security Vulnerabilities Across Deep Research Agents
作者: Sai Puppala, Ismail Hossain, Md Jahangir Alam, Yoonpyo Lee, Jay Yoo, Tanzim Ahad, Syed Bahauddin Alam, Sajedul Talukder
分类: cs.CR, cs.AI
发布日期: 2026-02-07
💡 一句话要点
提出AgentFence以评估深度代理的安全漏洞
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度代理 安全评估 信任边界 多轮交互 安全漏洞 大型语言模型 对话中断 架构中心
📋 核心要点
- 现有方法在深度代理的安全性评估上存在不足,未能有效识别和量化多轮交互中的安全漏洞。
- 本文提出AgentFence,通过定义14类攻击和可追溯的对话中断,系统性地评估深度代理的安全性。
- 实验结果显示,不同代理架构的安全破坏率差异显著,尤其是在操作风险类别中,表现出较高的安全漏洞率。
📝 摘要(中文)
随着大型语言模型作为深度代理的广泛应用,安全失败的风险从不安全文本转移到不安全的轨迹。本文提出了AgentFence,一种以架构为中心的安全评估方法,定义了14类信任边界攻击,涵盖规划、记忆、检索、工具使用和委托等方面,并通过可追溯的对话中断检测失败。我们在固定基础模型的情况下,评估了八种代理原型在持续多轮交互下的表现,发现不同架构的平均安全破坏率(MSBR)存在显著差异,最高风险类别主要集中在操作层面。
🔬 方法详解
问题定义:本文旨在解决深度代理在多轮交互中面临的安全漏洞评估问题,现有方法未能有效捕捉到这些漏洞的复杂性和多样性。
核心思路:AgentFence的核心思路是通过架构中心的安全评估,定义多种攻击类别,并利用可追溯的对话中断来检测安全失败,从而实现对代理安全性的全面评估。
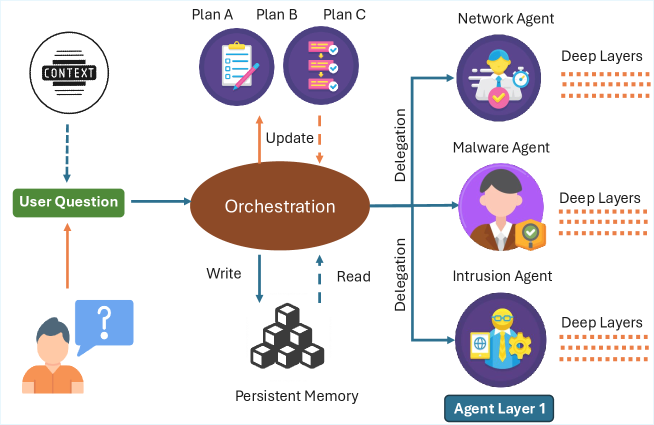
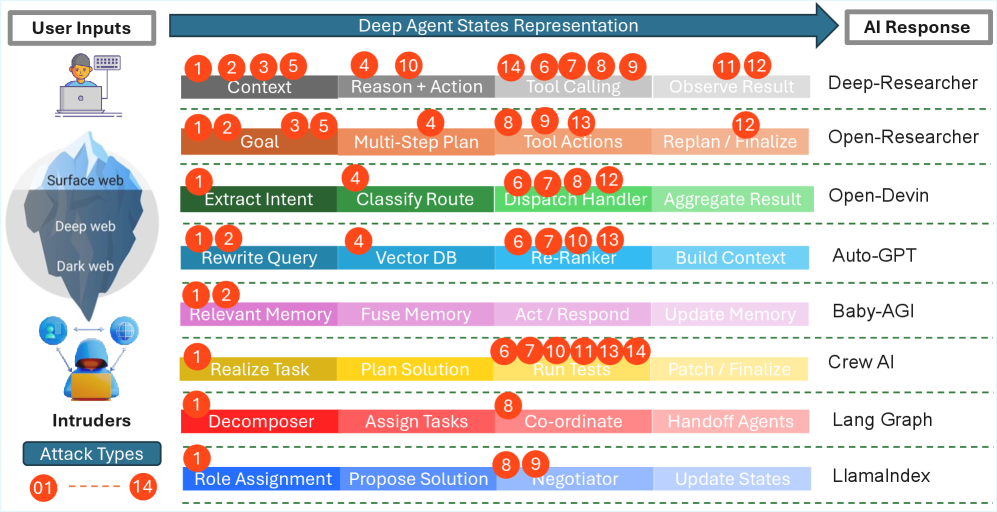
技术框架:AgentFence的整体架构包括多个模块:攻击类别定义、对话中断检测、以及安全性评估。每个模块针对不同的安全风险进行分析和评估。
关键创新:最重要的技术创新在于定义了14类信任边界攻击,这些攻击涵盖了代理的各个操作环节,提供了比现有方法更全面的安全评估视角。
关键设计:在设计中,采用了固定基础模型进行评估,并通过多轮交互的方式收集数据,确保评估结果的可靠性和有效性。
🖼️ 关键图片
📊 实验亮点
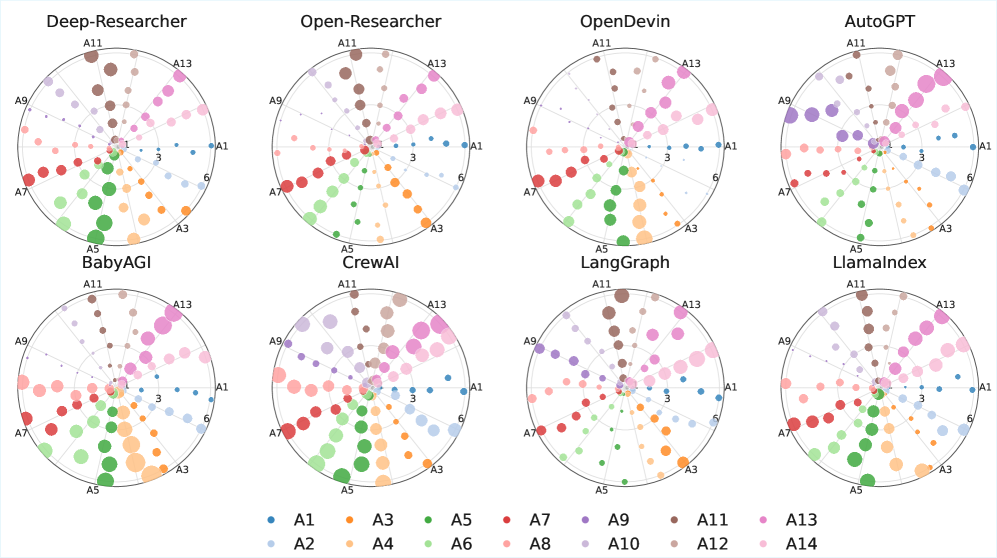
实验结果表明,不同代理架构的平均安全破坏率(MSBR)差异显著,LangGraph的MSBR为0.29±0.04,而AutoGPT为0.51±0.07。操作风险类别中,Denial-of-Wallet的破坏率高达0.62±0.08,显示出AgentFence在识别高风险安全漏洞方面的有效性。
🎯 应用场景
该研究的潜在应用领域包括智能助手、自动化决策系统和其他依赖深度代理的应用。通过提高安全性评估的准确性,AgentFence可以帮助开发更安全的AI系统,降低潜在的安全风险,提升用户信任。
📄 摘要(原文)
Large language models are increasingly deployed as deep agents that plan, maintain persistent state, and invoke external tools, shifting safety failures from unsafe text to unsafe trajectories. We introduce AgentFence, an architecture-centric security evaluation that defines 14 trust-boundary attack classes spanning planning, memory, retrieval, tool use, and delegation, and detects failures via trace-auditable conversation breaks (unauthorized or unsafe tool use, wrong-principal actions, state/objective integrity violations, and attack-linked deviations). Holding the base model fixed, we evaluate eight agent archetypes under persistent multi-turn interaction and observe substantial architectural variation in mean security break rate (MSBR), ranging from $0.29 \pm 0.04$ (LangGraph) to $0.51 \pm 0.07$ (AutoGPT). The highest-risk classes are operational: Denial-of-Wallet ($0.62 \pm 0.08$), Authorization Confusion ($0.54 \pm 0.10$), Retrieval Poisoning ($0.47 \pm 0.09$), and Planning Manipulation ($0.44 \pm 0.11$), while prompt-centric classes remain below $0.20$ under standard settings. Breaks are dominated by boundary violations (SIV 31%, WPA 27%, UTI+UTA 24%, ATD 18%), and authorization confusion correlates with objective and tool hijacking ($ρ\approx 0.63$ and $ρ\approx 0.58$). AgentFence reframes agent security around what matters operationally: whether an agent stays within its goal and authority envelope over time.