Evaluating Large Language Models for Detecting Architectural Decision Violations
作者: Ruoyu Su, Alexander Bakhtin, Noman Ahmad, Matteo Esposito, Valentina Lenarduzzi, Davide Taibi
分类: cs.SE, cs.AI
发布日期: 2026-02-07
💡 一句话要点
利用大型语言模型检测软件架构决策违规
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件架构 决策违规检测 自动化推理 架构决策记录
📋 核心要点
- 软件架构决策违规难以被发现,原因是缺乏系统文档和自动检测机制,这损害了软件质量。
- 该研究利用大型语言模型(LLMs)自动化架构推理,以检测开源项目中的架构决策违规行为。
- 实验结果表明,LLMs在检测显式、可从代码推断的决策违规方面表现出较高准确性,但在隐式决策方面仍有局限。
📝 摘要(中文)
架构决策记录(ADRs)在维护软件架构质量方面起着核心作用,但由于项目缺乏系统的文档记录和自动检测机制,许多决策违规行为未被发现。大型语言模型(LLMs)的最新进展为大规模自动化架构推理开辟了新的可能性。我们研究了LLMs在识别开源系统中决策违规行为方面的有效性,考察了它们的一致性、准确性和内在局限性。我们的研究分析了109个GitHub仓库中的980个ADR,使用了一个多模型流水线,其中一个LLM主要筛选潜在的决策违规行为,另外三个LLM独立验证推理。我们评估了一致性、准确性、精确度和召回率,并用专家评估补充了定量结果。对于显式的、可从代码推断的决策,这些模型达到了相当高的一致性和很强的准确性。对于依赖于部署配置或组织知识的隐式或面向部署的决策,准确性有所下降。因此,LLMs可以有意义地支持架构决策合规性的验证;然而,对于非专注于代码的决策,它们还不能取代人类的专业知识。
🔬 方法详解
问题定义:论文旨在解决软件架构决策违规难以自动检测的问题。现有方法的痛点在于缺乏有效的自动化工具,导致架构决策与实际实现不一致,从而降低软件质量。人工审核成本高昂且容易出错。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的自然语言理解和推理能力,自动分析架构决策记录(ADRs),并检测代码实现是否违反了这些决策。通过让LLMs理解ADRs的语义,并将其与代码实现进行对比,可以实现自动化的决策违规检测。
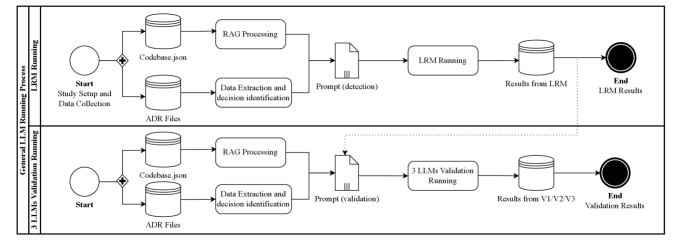
技术框架:该研究采用多模型流水线,包含以下主要阶段:1) 初筛:使用一个LLM筛选潜在的决策违规行为;2) 独立验证:使用三个额外的LLM独立验证初筛结果的推理过程;3) 评估:评估LLM的一致性、准确性、精确度和召回率,并进行专家评估。
关键创新:该研究的关键创新在于将大型语言模型应用于软件架构决策违规的自动检测。与传统的基于规则或静态分析的方法相比,LLMs能够理解自然语言描述的架构决策,并进行更灵活和智能的推理。
关键设计:研究中使用了多个LLM,具体模型未知。通过多模型投票的方式提高检测的准确性和鲁棒性。评估指标包括一致性(模型间)、准确性、精确度和召回率。研究还进行了专家评估,以验证LLM检测结果的可靠性。
🖼️ 关键图片
📊 实验亮点
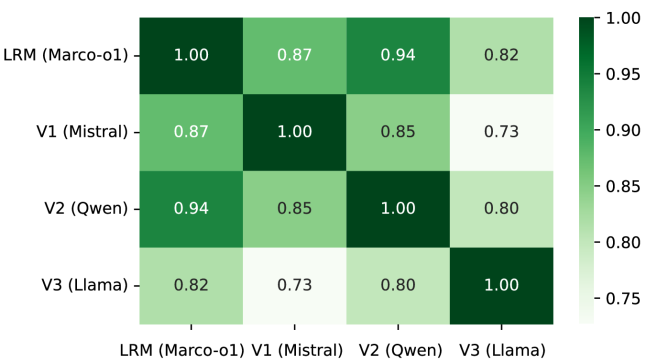
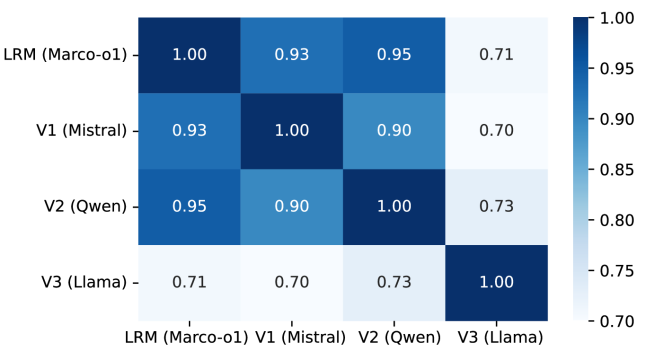
实验结果表明,对于显式的、可从代码推断的决策,LLMs达到了相当高的一致性和很强的准确性。这表明LLMs在特定类型的架构决策违规检测方面具有潜力。然而,对于隐式或面向部署的决策,准确性有所下降,提示LLMs在处理依赖于上下文知识的决策时仍有局限性。
🎯 应用场景
该研究成果可应用于软件开发过程的质量保证环节,帮助开发团队自动检测架构决策违规,提高软件质量和可维护性。此外,该方法还可用于架构知识的自动化管理和演化分析,为软件架构师提供决策支持。
📄 摘要(原文)
Architectural Decision Records (ADRs) play a central role in maintaining software architecture quality, yet many decision violations go unnoticed because projects lack both systematic documentation and automated detection mechanisms. Recent advances in Large Language Models (LLMs) open up new possibilities for automating architectural reasoning at scale. We investigated how effectively LLMs can identify decision violations in open-source systems by examining their agreement, accuracy, and inherent limitations. Our study analyzed 980 ADRs across 109 GitHub repositories using a multi-model pipeline in which one LLM primary screens potential decision violations, and three additional LLMs independently validate the reasoning. We assessed agreement, accuracy, precision, and recall, and complemented the quantitative findings with expert evaluation. The models achieved substantial agreement and strong accuracy for explicit, code-inferable decisions. Accuracy falls short for implicit or deployment-oriented decisions that depend on deployment configuration or organizational knowledge. Therefore, LLMs can meaningfully support validation of architectural decision compliance; however, they are not yet replacing human expertise for decisions not focused on code.