How does longer temporal context enhance multimodal narrative video processing in the brain?
作者: Prachi Jindal, Anant Khandelwal, Manish Gupta, Bapi S. Raju, Subba Reddy Oota, Tanmoy Chakraborty
分类: q-bio.NC, cs.AI, cs.CV, cs.LG
发布日期: 2026-02-07
备注: 22 pages, 15 figures
💡 一句话要点
研究视频时序上下文长度如何影响大脑对多模态叙事视频的处理,并与模型对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 叙事视频理解 多模态学习 大脑-模型对齐 时序上下文 fMRI 大型语言模型 神经科学 视频处理
📋 核心要点
- 现有方法在理解人类如何处理长时序叙事视频,以及如何与人工智能模型对齐方面存在不足。
- 该研究通过改变视频片段的时序上下文长度和叙事任务提示,来探索大脑与模型之间的对齐关系。
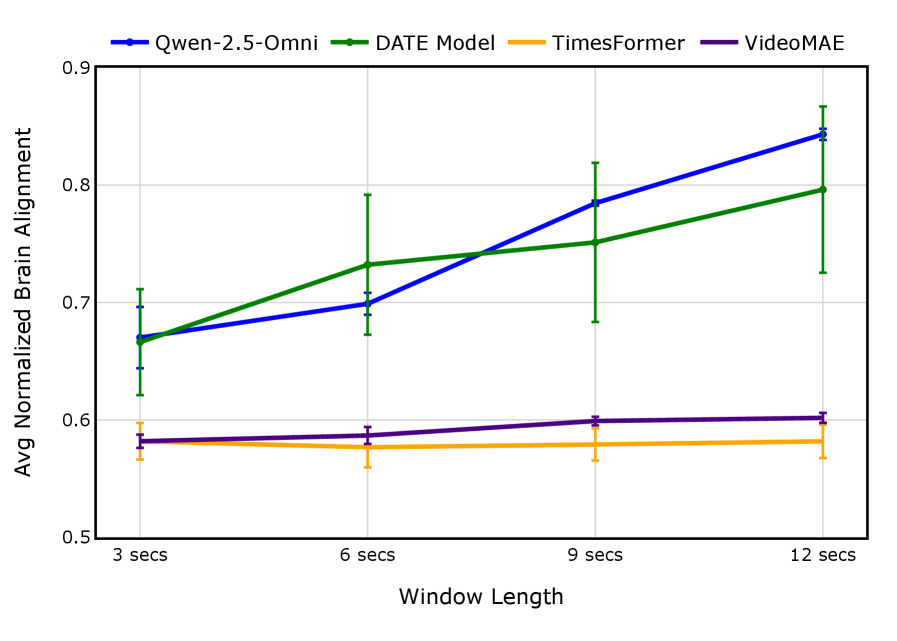
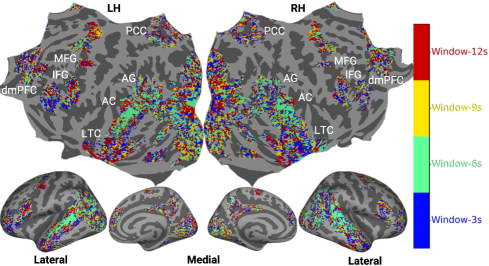
- 实验结果表明,增加片段时长显著提升了多模态大型语言模型的大脑对齐,并揭示了不同大脑区域对不同时序信息的处理偏好。
📝 摘要(中文)
本研究旨在探索人类和人工智能系统如何处理复杂的叙事视频,这是神经科学和机器学习交叉领域的一个根本性挑战。研究考察了视频片段的时序上下文长度(3-12秒)和叙事任务提示如何影响自然观看电影时的大脑-模型对齐。利用参与者观看完整电影时的fMRI记录,我们研究了对叙事上下文敏感的大脑区域如何在不同的时间尺度上动态地表示信息,以及这些神经模式如何与模型导出的特征对齐。研究发现,增加片段时长可以显著提高多模态大型语言模型(MLLM)的大脑对齐,而单模态视频模型几乎没有提升。此外,较短的时间窗口与感知和早期语言区域对齐,而较长的时间窗口优先与高阶整合区域对齐,这反映在MLLM中的层级结构。最后,叙事任务提示(多场景摘要、叙事摘要、角色动机和事件边界检测)引发了任务特定的、区域依赖性的大脑对齐模式,以及高阶区域中片段级别调整的上下文依赖性变化。总而言之,我们的结果将长篇叙事电影定位为探索长上下文MLLM中具有生物学相关性的时间整合和可解释表示的原则性测试平台。
🔬 方法详解
问题定义:该论文旨在研究人类大脑如何处理长时序的叙事视频,并探究大脑的神经活动模式与人工智能模型(特别是多模态大型语言模型MLLM)的特征表示之间的对应关系。现有方法在理解长时序上下文对大脑处理叙事视频的影响,以及如何利用模型来解释大脑活动方面存在不足。
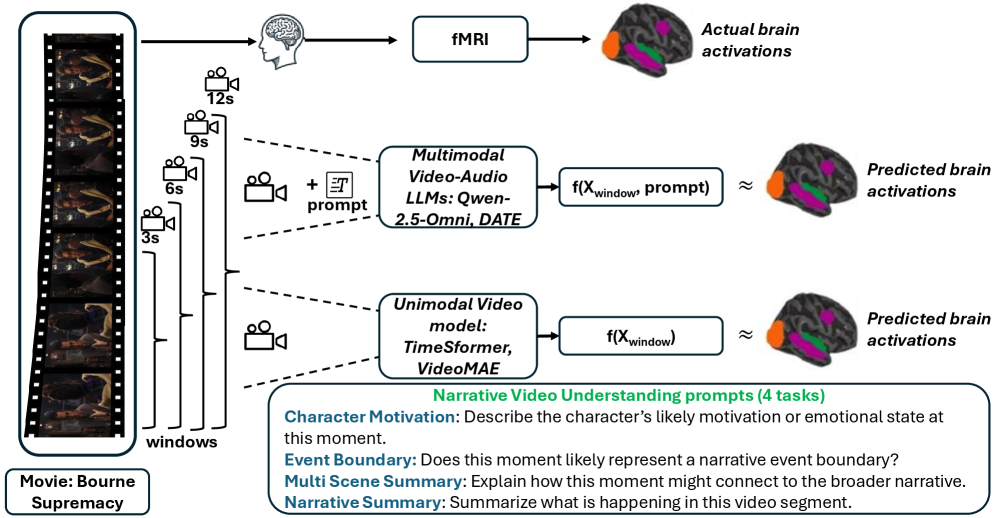
核心思路:核心思路是通过操纵视频片段的时序上下文长度(3-12秒)和引入不同的叙事任务提示,来观察大脑fMRI信号的变化,并将其与不同类型的AI模型(包括单模态视频模型和多模态大型语言模型)的特征表示进行比较。通过这种方式,揭示大脑不同区域对不同时序信息的处理偏好,以及模型如何捕捉这些信息。
技术框架:整体框架包括以下几个主要步骤:1) 使用fMRI记录参与者观看完整电影时的脑活动;2) 将电影分割成不同时长的片段(3-12秒);3) 使用不同的叙事任务提示引导参与者观看;4) 提取大脑fMRI信号,并将其与不同AI模型的特征表示进行对齐;5) 分析大脑区域对不同时序长度和任务提示的响应模式。
关键创新:该研究的关键创新在于:1) 系统地研究了时序上下文长度对大脑处理叙事视频的影响;2) 揭示了多模态大型语言模型在捕捉大脑对长时序信息的处理方面优于单模态视频模型;3) 探索了不同叙事任务提示对大脑活动的影响,并发现了任务特定的脑区激活模式;4) 将长篇叙事电影定位为一个测试长上下文MLLM中生物学相关的时间整合和可解释表示的原则性测试平台。
关键设计:关键设计包括:1) 使用fMRI技术获取高精度的大脑活动数据;2) 精心设计的叙事任务提示,包括多场景摘要、叙事摘要、角色动机和事件边界检测;3) 使用多种AI模型,包括单模态视频模型和多模态大型语言模型,进行对比分析;4) 使用脑-模型对齐方法,量化大脑活动与模型特征之间的对应关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,增加视频片段的时序上下文长度(3-12秒)可以显著提高多模态大型语言模型(MLLM)的大脑对齐程度,而单模态视频模型的提升不明显。此外,研究发现较短的时间窗口与感知和早期语言区域对齐,而较长的时间窗口优先与高阶整合区域对齐。叙事任务提示也能够引发任务特定的脑区激活模式。
🎯 应用场景
该研究成果可应用于开发更智能的视频理解系统,例如,提升视频摘要、情节分析和情感识别的准确性。此外,该研究有助于理解人类大脑如何处理复杂信息,为神经疾病的诊断和治疗提供新的思路。未来,可以结合脑机接口技术,实现人机协同的视频内容创作和分析。
📄 摘要(原文)
Understanding how humans and artificial intelligence systems process complex narrative videos is a fundamental challenge at the intersection of neuroscience and machine learning. This study investigates how the temporal context length of video clips (3--12 s clips) and the narrative-task prompting shape brain-model alignment during naturalistic movie watching. Using fMRI recordings from participants viewing full-length movies, we examine how brain regions sensitive to narrative context dynamically represent information over varying timescales and how these neural patterns align with model-derived features. We find that increasing clip duration substantially improves brain alignment for multimodal large language models (MLLMs), whereas unimodal video models show little to no gain. Further, shorter temporal windows align with perceptual and early language regions, while longer windows preferentially align higher-order integrative regions, mirrored by a layer-to-cortex hierarchy in MLLMs. Finally, narrative-task prompts (multi-scene summary, narrative summary, character motivation, and event boundary detection) elicit task-specific, region-dependent brain alignment patterns and context-dependent shifts in clip-level tuning in higher-order regions. Together, our results position long-form narrative movies as a principled testbed for probing biologically relevant temporal integration and interpretable representations in long-context MLLMs.