VERIFY-RL: Verifiable Recursive Decomposition for Reinforcement Learning in Mathematical Reasoning
作者: Kaleem Ullah Qasim, Jiashu Zhang, Hao Li, Muhammad Kafeel Shaheen
分类: cs.AI, cs.CC, math.NA
发布日期: 2026-02-07
备注: 13 pages
💡 一句话要点
VERIFY-RL:基于可验证递归分解的强化学习方法,提升数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 数学推理 符号微分 问题分解 可验证性 语言模型 递归分解
📋 核心要点
- 现有数学问题求解的分解方法依赖启发式,无法保证子问题更简单、有助于父任务,或关系具有数学依据。
- VERIFY-RL利用符号微分提供天然结构进行可验证分解,微积分规则明确定义表达式如何简化为具有可证明性质的组件。
- 实验表明,消除无效分解能显著提高性能,最难问题准确率从32%提升至68%,整体相对提升40%。
📝 摘要(中文)
本文提出了一种名为VERIFY-RL的框架,用于训练语言模型解决复杂的数学问题。该框架利用符号微分为基础,进行可验证的递归分解。与现有的启发式分解方法不同,VERIFY-RL确保每次父子分解都满足三个可验证的条件:严格递减的结构复杂性、解的包含性以及形式化的规则推导。这些属性可以通过符号计算进行自动验证,实现“通过构造进行验证”。实验结果表明,消除无效分解可以显著提高性能,在最难问题上的准确率从32%提高到68%,总体准确率相对提高了40%。
🔬 方法详解
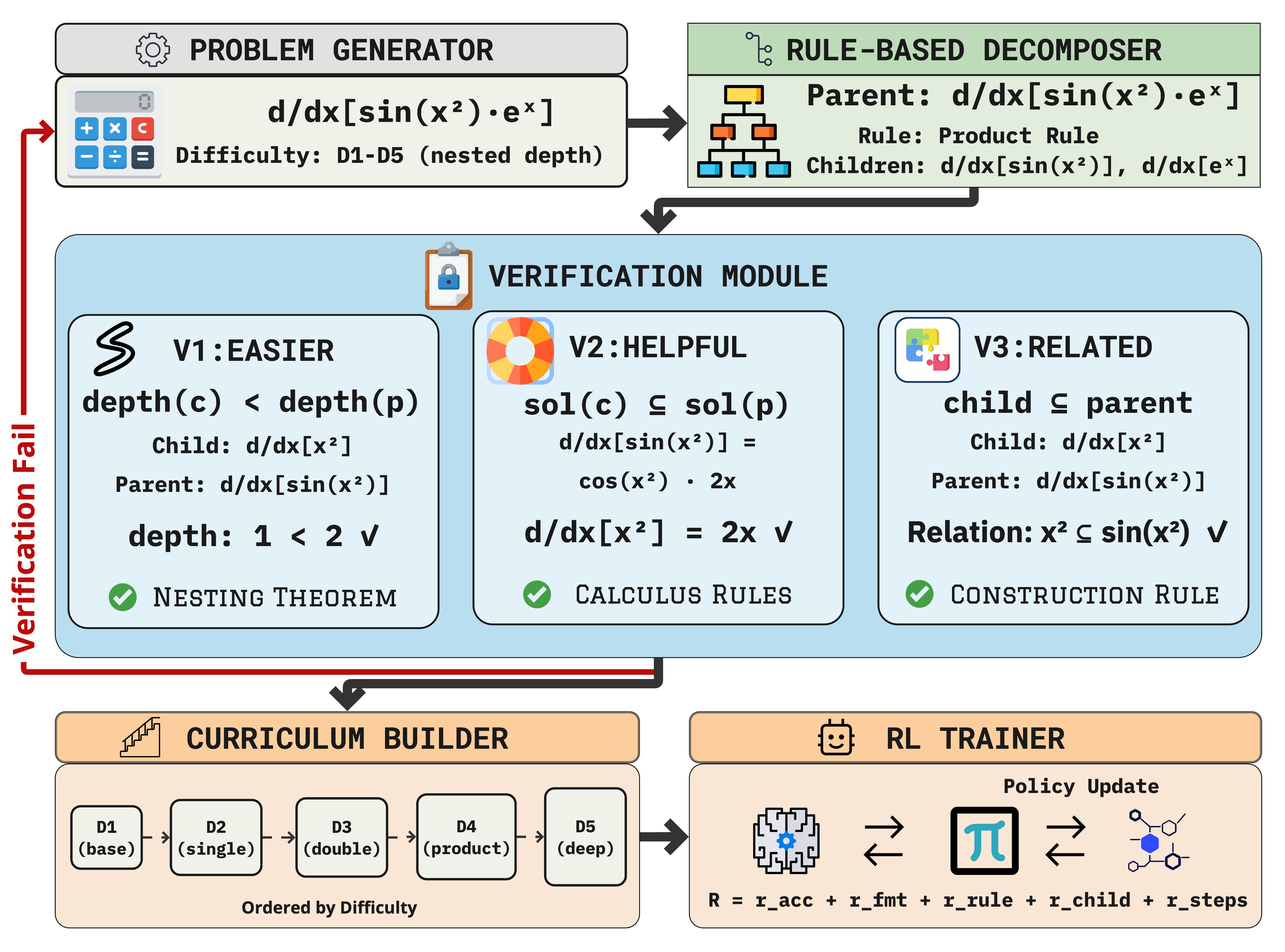
问题定义:现有方法在将复杂数学问题分解为子问题时,通常采用启发式方法。这些方法缺乏严格的数学保证,无法确保分解后的子问题确实比原始问题更简单,或者解决子问题能够帮助解决原始问题。此外,子问题之间的关系也可能缺乏明确的数学依据,导致分解过程不可靠,最终影响问题求解的准确性。
核心思路:VERIFY-RL的核心思路是利用符号微分的特性,将数学表达式的分解过程与微积分规则相结合。符号微分提供了一种天然的结构,可以将复杂的表达式分解为更简单的组件,并且这些分解过程具有可证明的数学性质。通过确保每次分解都满足严格递减的结构复杂性、解的包含性以及形式化的规则推导,VERIFY-RL可以实现可验证的递归分解。
技术框架:VERIFY-RL框架包含以下主要阶段:1) 问题分解:利用符号微分规则将原始数学问题分解为一系列子问题。2) 验证:对每次分解进行验证,确保满足三个关键条件:结构复杂性递减、解的包含性以及形式化规则推导。如果分解不满足这些条件,则将其视为无效分解并排除。3) 强化学习:使用强化学习算法训练语言模型,使其能够有效地解决分解后的子问题,并将这些子问题的解组合起来以解决原始问题。4) 迭代优化:通过迭代地进行问题分解、验证和强化学习,不断优化模型的性能。
关键创新:VERIFY-RL最重要的技术创新点在于其可验证的分解方法。与传统的启发式分解方法不同,VERIFY-RL通过符号计算自动验证每次分解的有效性,确保分解后的子问题确实比原始问题更简单,并且解决子问题能够帮助解决原始问题。这种“通过构造进行验证”的方法可以显著提高问题求解的准确性和可靠性。
关键设计:VERIFY-RL的关键设计包括:1) 结构复杂性度量:定义了一种用于衡量数学表达式复杂性的度量标准,确保每次分解都能够降低表达式的复杂性。2) 解的包含性验证:验证子问题的解是否包含在原始问题的解空间中,确保解决子问题能够帮助解决原始问题。3) 形式化规则推导:使用形式化的微积分规则进行问题分解,确保分解过程具有明确的数学依据。4) 强化学习算法:选择合适的强化学习算法来训练语言模型,使其能够有效地解决分解后的子问题。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VERIFY-RL在数学问题求解任务上取得了显著的性能提升。在最困难的问题上,VERIFY-RL的准确率从32%提高到68%,总体准确率相对提高了40%。这些结果表明,通过消除无效分解,VERIFY-RL可以显著提高语言模型解决复杂数学问题的能力,验证了该方法的可行性和有效性。
🎯 应用场景
VERIFY-RL具有广泛的应用前景,可应用于自动化数学推理、科学发现、程序合成等领域。通过提高语言模型解决复杂数学问题的能力,VERIFY-RL可以帮助研究人员和工程师更有效地进行数学建模、仿真和优化,从而加速科学研究和工程开发的进程。此外,该方法还可以应用于教育领域,帮助学生更好地理解和掌握数学知识。
📄 摘要(原文)
Training language models to solve complex mathematical problems benefits from curriculum learning progressively training on simpler subproblems. However, existing decomposition methods are often heuristic, offering no guarantees that subproblems are simpler, that solving them aids the parent task, or that their relationships are mathematically grounded. We observe that symbolic differentiation provides a natural structure for verified decomposition: calculus rules explicitly define how expressions reduce to simpler components with provable properties. We introduce Verify-RL, a framework where every parent-child decomposition satisfies three verifiable conditions: strictly decreasing structural complexity, solution containment, and formal rule derivation. Unlike heuristic methods where a significant fraction of decompositions are invalid our properties admit automatic verification through symbolic computation, achieving "verification by construction" Experiments demonstrate that eliminating invalid decompositions yields sizable gains, accuracy on the hardest problems more than doubles from 32% to 68%, with a 40% relative improvement overall.