Linguistic properties and model scale in brain encoding: from small to compressed language models
作者: Subba Reddy Oota, Vijay Rowtula, Satya Sai Srinath Namburi, Khushbu Pahwa, Anant Khandelwal, Manish Gupta, Tanmoy Chakraborty, Bapi S. Raju
分类: q-bio.NC, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-07
备注: 40 pages, 33 figures
💡 一句话要点
研究表明:3B规模语言模型在脑编码预测中可媲美更大模型,且对压缩具有鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑编码 语言模型 模型压缩 fMRI 神经预测 语言表征 模型规模 量化
📋 核心要点
- 大型语言模型与人脑活动的对齐程度随模型规模增大而提高,但驱动因素和关键表征属性尚不明确。
- 该研究系统性地考察了模型规模和数值精度对大脑对齐的影响,旨在确定捕获大脑相关表征所需的最小模型容量。
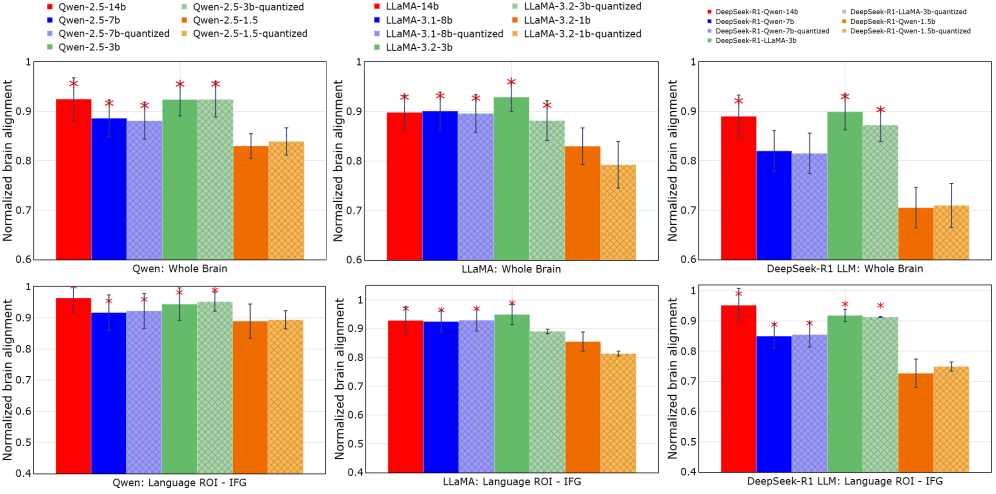
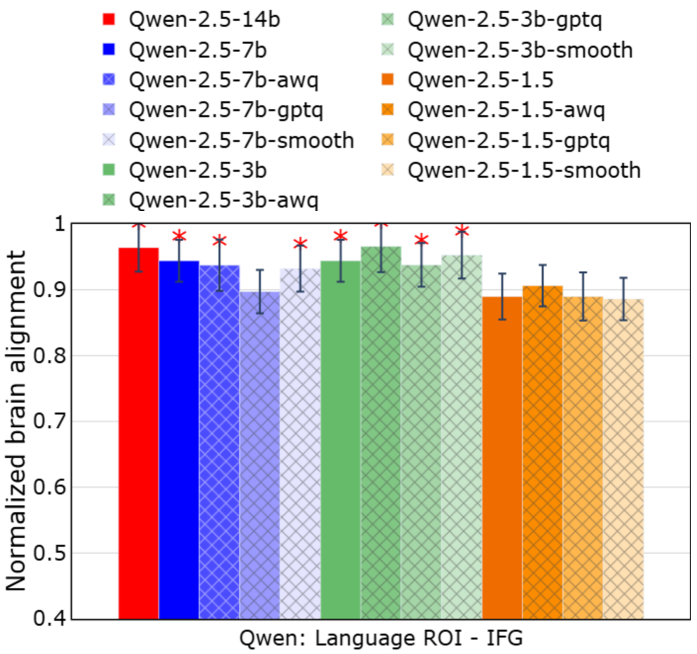
- 实验表明,3B规模的SLM可实现与更大LLM相当的大脑预测能力,且大脑对齐对压缩具有很强的鲁棒性。
📝 摘要(中文)
最近的研究表明,扩展大型语言模型(LLM)可以提高其与人类大脑活动的对齐程度,但尚不清楚是什么驱动了这些改进以及哪些表征属性是关键。虽然更大的模型通常产生更好的任务性能和大脑对齐,但对其进行机制分析越来越困难。这就提出了一个根本问题:捕获与大脑相关的表征所需的最小模型容量是多少?为了解决这个问题,我们系统地研究了约束模型规模和数值精度如何影响大脑对齐。我们通过预测自然语言理解过程中的fMRI响应来比较全精度LLM、小型语言模型(SLM)和压缩变体(量化和剪枝)。在高达14B参数的模型系列中,我们发现3B SLM实现了与更大LLM无法区分的大脑预测能力,而1B模型则显著下降,尤其是在语义语言区域。大脑对齐对压缩具有显著的鲁棒性:大多数量化和剪枝方法都保留了神经预测能力,但GPTQ是一个持续的例外。语言探测揭示了任务性能和大脑预测能力之间的分离:压缩会降低语篇、语法和形态,但大脑预测能力在很大程度上保持不变。总的来说,大脑对齐在适度的模型规模下饱和,并且对压缩具有弹性,这挑战了关于神经缩放的常见假设,并激发了用于大脑对齐语言建模的紧凑模型。
🔬 方法详解
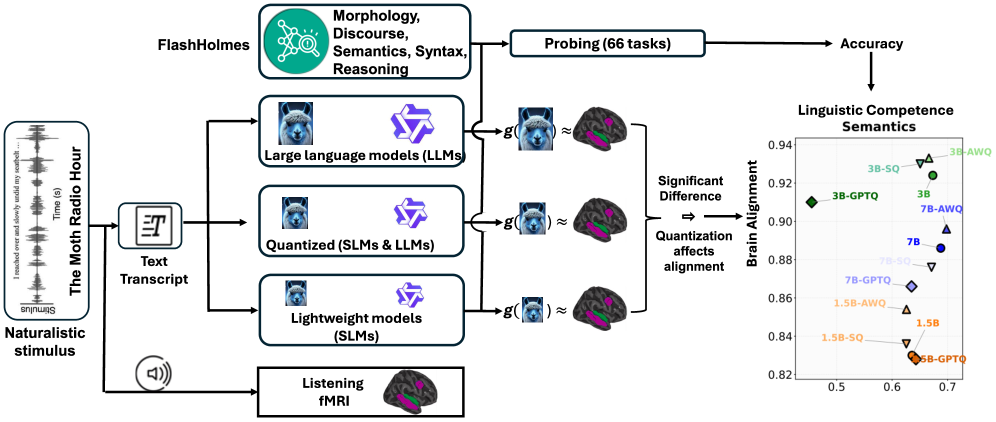
问题定义:现有研究表明,更大的语言模型通常能更好地与人脑活动对齐,但对其进行机制分析变得困难。因此,需要确定捕获大脑相关表征所需的最小模型容量,并理解哪些因素影响大脑对齐。
核心思路:通过系统地约束模型规模和数值精度,研究不同规模和压缩程度的模型在预测fMRI响应时的表现,从而评估它们与大脑活动的对齐程度。核心在于找到一个在保持大脑预测能力的同时,尽可能小的模型。
技术框架:该研究比较了全精度LLM、小型语言模型(SLM)以及压缩变体(量化和剪枝)。使用这些模型预测受试者在进行自然语言理解任务时的fMRI响应。通过比较不同模型的预测准确性,评估它们与大脑活动的对齐程度。同时,使用语言探测技术分析模型的语言表征能力。
关键创新:该研究表明,大脑对齐在适度的模型规模下饱和,并且对压缩具有弹性。这挑战了关于神经缩放的常见假设,并为开发用于大脑对齐语言建模的紧凑模型提供了依据。此外,研究还揭示了任务性能和大脑预测能力之间的分离,即压缩可能降低任务性能,但对大脑预测能力影响不大。
关键设计:研究中使用了不同规模的语言模型,包括高达14B参数的模型。采用了多种压缩方法,包括量化和剪枝。使用fMRI数据评估模型与大脑活动的对齐程度。通过语言探测技术分析模型的语言表征能力,包括语篇、语法和形态等方面。
🖼️ 关键图片
📊 实验亮点
实验结果表明,3B规模的SLM在预测fMRI响应方面可以达到与更大LLM相当的水平,而1B模型则表现显著下降。此外,大脑对齐对压缩具有很强的鲁棒性,大多数量化和剪枝方法都能保持神经预测能力,但GPTQ除外。语言探测显示,压缩会降低语篇、语法和形态等方面的性能,但对大脑预测能力影响不大。
🎯 应用场景
该研究成果可应用于开发更高效、更易于分析的脑启发式语言模型。通过理解大脑对齐所需的最小模型容量和关键表征,可以设计出更紧凑的模型,用于自然语言处理、人机交互等领域。此外,该研究还有助于深入理解大脑如何处理语言,为认知科学研究提供新的视角。
📄 摘要(原文)
Recent work has shown that scaling large language models (LLMs) improves their alignment with human brain activity, yet it remains unclear what drives these gains and which representational properties are responsible. Although larger models often yield better task performance and brain alignment, they are increasingly difficult to analyze mechanistically. This raises a fundamental question: what is the minimal model capacity required to capture brain-relevant representations? To address this question, we systematically investigate how constraining model scale and numerical precision affects brain alignment. We compare full-precision LLMs, small language models (SLMs), and compressed variants (quantized and pruned) by predicting fMRI responses during naturalistic language comprehension. Across model families up to 14B parameters, we find that 3B SLMs achieve brain predictivity indistinguishable from larger LLMs, whereas 1B models degrade substantially, particularly in semantic language regions. Brain alignment is remarkably robust to compression: most quantization and pruning methods preserve neural predictivity, with GPTQ as a consistent exception. Linguistic probing reveals a dissociation between task performance and brain predictivity: compression degrades discourse, syntax, and morphology, yet brain predictivity remains largely unchanged. Overall, brain alignment saturates at modest model scales and is resilient to compression, challenging common assumptions about neural scaling and motivating compact models for brain-aligned language modeling.