Joint Reward Modeling: Internalizing Chain-of-Thought for Efficient Visual Reward Models
作者: Yankai Yang, Yancheng Long, Hongyang Wei, Wei Chen, Tianke Zhang, Kaiyu Jiang, Haonan Fan, Changyi Liu, Jiankang Chen, Kaiyu Tang, Bin Wen, Fan Yang, Tingting Gao, Han Li, Shuo Yang
分类: cs.AI
发布日期: 2026-02-07
💡 一句话要点
提出联合奖励建模(JRM),提升视觉奖励模型在图像编辑等复杂任务中的效率和语义理解能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 强化学习 图像编辑 视觉语言模型 联合训练
📋 核心要点
- 现有奖励模型在图像编辑等复杂任务中,难以兼顾推理能力和计算效率,限制了其应用。
- JRM通过联合优化偏好学习和语言建模,将生成模型的语义推理能力融入高效的判别式模型中。
- 实验表明,JRM在多个基准测试中达到SOTA,并显著提升了下游强化学习的稳定性和性能。
📝 摘要(中文)
奖励模型对于从人类反馈中进行强化学习至关重要,它决定了生成模型的一致性和可靠性。对于图像编辑等复杂任务,奖励模型需要捕捉全局语义一致性和隐式逻辑约束,而不仅仅是局部相似性。现有的奖励建模方法存在明显的局限性。判别式奖励模型与人类偏好对齐较好,但由于推理监督有限,难以处理复杂的语义。生成式奖励模型提供更强的语义理解和推理能力,但推理成本高昂,难以直接与人类偏好对齐。为此,我们提出了联合奖励建模(JRM),它在共享的视觉-语言骨干网络上联合优化偏好学习和语言建模。这种方法将生成模型的语义和推理能力内化到高效的判别式表示中,从而实现快速而准确的评估。JRM在MMRB2和EditReward-Bench上取得了最先进的结果,并显著提高了下游在线强化学习的稳定性和性能。这些结果表明,联合训练有效地弥合了奖励建模中的效率和语义理解之间的差距。
🔬 方法详解
问题定义:现有判别式奖励模型虽然效率高,但缺乏足够的推理能力来捕捉图像编辑等复杂任务中的全局语义一致性和隐式逻辑约束。而生成式奖励模型虽然具有更强的语义理解能力,但计算成本高昂,难以直接与人类偏好对齐。因此,如何在保证效率的同时,提升奖励模型的语义理解和推理能力,是本文要解决的核心问题。
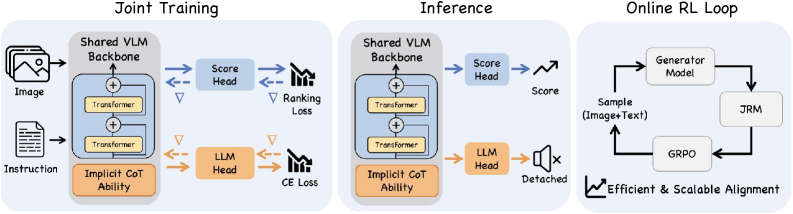
核心思路:本文的核心思路是利用联合训练的方式,将生成式模型的语义和推理能力“内化”到判别式模型中。具体来说,通过在共享的视觉-语言骨干网络上同时进行偏好学习(模仿人类偏好)和语言建模(学习图像的语义描述),使得判别式模型能够学习到生成式模型所具备的语义理解和推理能力,从而在保证效率的同时,提升奖励模型的性能。
技术框架:JRM的技术框架主要包含一个共享的视觉-语言骨干网络,以及两个并行的训练目标:偏好学习和语言建模。视觉-语言骨干网络负责提取图像的视觉特征和文本的语义特征,偏好学习模块负责学习人类对不同图像编辑结果的偏好,语言建模模块负责学习图像的语义描述。通过联合优化这两个目标,使得骨干网络能够学习到既能反映人类偏好,又能捕捉图像语义的表示。
关键创新:JRM最重要的技术创新点在于其联合训练的框架。与传统的先训练生成式模型再训练判别式模型的方法不同,JRM通过同时优化偏好学习和语言建模,使得判别式模型能够直接从生成式模型的监督信号中学习,从而避免了信息损失和训练难度。此外,JRM还通过共享视觉-语言骨干网络,进一步提升了模型的效率和泛化能力。
关键设计:在具体实现上,JRM采用了Transformer作为视觉-语言骨干网络,并使用了对比学习损失来优化偏好学习模块,以及交叉熵损失来优化语言建模模块。此外,为了进一步提升模型的性能,JRM还采用了数据增强、正则化等技术。
🖼️ 关键图片


📊 实验亮点
JRM在MMRB2和EditReward-Bench两个基准测试中取得了SOTA结果,表明其在图像编辑奖励建模方面的优越性。此外,JRM还显著提高了下游在线强化学习的稳定性和性能,验证了其在实际应用中的有效性。具体性能提升数据需要在论文中查找。
🎯 应用场景
JRM可广泛应用于图像编辑、图像生成、视频生成等领域,通过更准确地评估生成结果的质量,提升生成模型的性能和用户体验。此外,JRM还可以应用于机器人控制、自动驾驶等需要从人类反馈中进行学习的领域,提高系统的智能化水平。
📄 摘要(原文)
Reward models are critical for reinforcement learning from human feedback, as they determine the alignment quality and reliability of generative models. For complex tasks such as image editing, reward models are required to capture global semantic consistency and implicit logical constraints beyond local similarity. Existing reward modeling approaches have clear limitations. Discriminative reward models align well with human preferences but struggle with complex semantics due to limited reasoning supervision. Generative reward models offer stronger semantic understanding and reasoning, but they are costly at inference time and difficult to align directly with human preferences. To this end, we propose Joint Reward Modeling (JRM), which jointly optimizes preference learning and language modeling on a shared vision-language backbone. This approach internalizes the semantic and reasoning capabilities of generative models into efficient discriminative representations, enabling fast and accurate evaluation. JRM achieves state-of-the-art results on MMRB2 and EditReward-Bench, and significantly improves stability and performance in downstream online reinforcement learning. These results show that joint training effectively bridges efficiency and semantic understanding in reward modeling.