Are Reasoning LLMs Robust to Interventions on Their Chain-of-Thought?
作者: Alexander von Recum, Leander Girrbach, Zeynep Akata
分类: cs.AI
发布日期: 2026-02-07
备注: ICLR 2026
💡 一句话要点
研究推理LLM在思维链中受干扰时的鲁棒性,揭示其恢复机制与效率权衡。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链 鲁棒性 干预评估 推理恢复
📋 核心要点
- 现有推理LLM的思维链易受干扰,缺乏对中间推理步骤鲁棒性的系统评估。
- 提出受控干预框架,在思维链的不同阶段注入良性、中性和对抗性扰动,评估模型恢复能力。
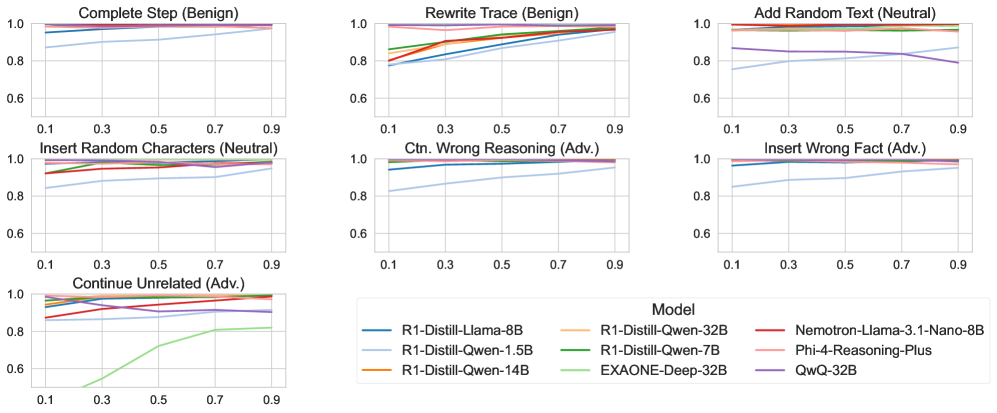
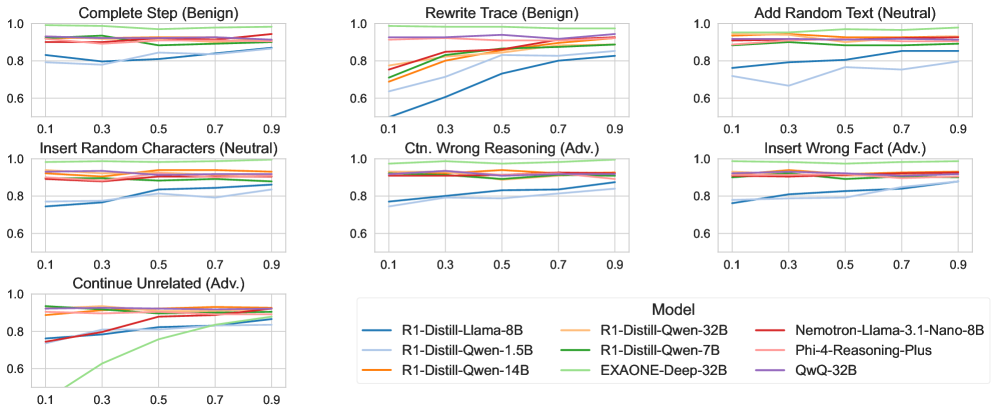
- 实验表明RLLM具有一定鲁棒性,但释义会降低性能,噪声会增加推理长度,揭示了鲁棒性与效率的权衡。
📝 摘要(中文)
推理大型语言模型(RLLM)通过生成逐步的思维链(CoT)来提高复杂任务的性能和推理透明度。本文研究了这些推理轨迹在受到干扰时的鲁棒性。为此,作者提出了一个受控评估框架,在固定的时间步长扰动模型自身的CoT。设计了七种干预措施(良性、中性和对抗性),并将它们应用于多个开放权重的RLLM,涵盖数学、科学和逻辑任务。结果表明,RLLM通常具有鲁棒性,能够可靠地从各种扰动中恢复,并且鲁棒性随着模型规模的增大而提高,而随着干预发生时间的提前而降低。然而,鲁棒性不是风格不变的:释义会抑制类似怀疑的表达并降低性能,而其他干预会触发怀疑并支持恢复。恢复也伴随着代价:中性和对抗性噪声会使CoT长度膨胀超过200%,而释义会缩短轨迹但损害准确性。这些发现为RLLM如何保持推理完整性提供了新的证据,将怀疑确定为一种核心恢复机制,并强调了未来训练方法应解决的鲁棒性和效率之间的权衡。
🔬 方法详解
问题定义:论文旨在研究推理大型语言模型(RLLM)在生成思维链(CoT)的过程中,当CoT受到各种干扰时,其推理的鲁棒性如何。现有方法缺乏对CoT中间步骤的鲁棒性评估,无法有效应对推理过程中可能出现的错误或噪声,导致最终答案的准确性下降。
核心思路:论文的核心思路是通过设计一个受控的干预框架,在RLLM生成CoT的过程中,人为地引入不同类型的扰动,然后观察模型是否能够从这些扰动中恢复,并最终给出正确的答案。通过这种方式,可以系统地评估RLLM对CoT中错误或噪声的鲁棒性。作者认为,理解RLLM的恢复机制有助于提升其在实际应用中的可靠性。
技术框架:该研究的技术框架主要包含以下几个阶段: 1. 任务选择:选择数学、科学和逻辑等需要复杂推理的任务。 2. 模型选择:选择多个开源的RLLM作为实验对象。 3. CoT生成:让RLLM生成解决任务的CoT。 4. 干预设计:设计七种不同类型的干预措施,包括良性、中性和对抗性干预。这些干预旨在模拟CoT中可能出现的各种错误或噪声。 5. 干预实施:在CoT的特定时间步长上实施干预。 6. 结果评估:评估RLLM在受到干预后,是否能够恢复并给出正确的答案。同时,还评估CoT的长度和模型对干预的置信度。
关键创新:该研究的关键创新在于提出了一个受控的干预框架,用于系统地评估RLLM对CoT中错误或噪声的鲁棒性。与以往的研究不同,该研究不是简单地评估RLLM在干净数据上的性能,而是关注其在受到干扰时的表现。此外,该研究还揭示了RLLM的恢复机制,例如“怀疑”在恢复过程中的作用。
关键设计:干预措施的设计是关键。七种干预包括: 1. Paraphrase: 使用释义模型改写CoT步骤。 2. Insert Fact: 插入一个与任务相关的正确事实。 3. Insert Noise: 插入随机噪声。 4. Insert Contradiction: 插入一个与CoT步骤矛盾的陈述。 5. Delete Sentence: 删除CoT步骤中的一个句子。 6. Swap Sentences: 交换CoT步骤中的两个句子。 7. Repeat Sentence: 重复CoT步骤中的一个句子。 干预位置的选择也很重要,论文在CoT的不同阶段进行干预,以评估鲁棒性随时间的变化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RLLM通常具有鲁棒性,能够从各种扰动中恢复。鲁棒性随着模型规模的增大而提高,但随着干预发生时间的提前而降低。释义会抑制类似怀疑的表达并降低性能,而其他干预会触发怀疑并支持恢复。中性和对抗性噪声会使CoT长度膨胀超过200%,而释义会缩短轨迹但损害准确性。
🎯 应用场景
该研究成果可应用于提升RLLM在实际应用中的可靠性和鲁棒性,例如在智能客服、自动驾驶、医疗诊断等领域。通过理解RLLM的恢复机制,可以设计更有效的训练方法,提高模型在噪声环境下的性能。此外,该研究还可以帮助开发更安全的AI系统,防止模型受到恶意攻击。
📄 摘要(原文)
Reasoning LLMs (RLLMs) generate step-by-step chains of thought (CoTs) before giving an answer, which improves performance on complex tasks and makes reasoning more transparent. But how robust are these reasoning traces to disruptions that occur within them? To address this question, we introduce a controlled evaluation framework that perturbs a model's own CoT at fixed timesteps. We design seven interventions (benign, neutral, and adversarial) and apply them to multiple open-weight RLLMs across Math, Science, and Logic tasks. Our results show that RLLMs are generally robust, reliably recovering from diverse perturbations, with robustness improving with model size and degrading when interventions occur early. However, robustness is not style-invariant: paraphrasing suppresses doubt-like expressions and reduces performance, while other interventions trigger doubt and support recovery. Recovery also carries a cost: neutral and adversarial noise can inflate CoT length by more than 200%, whereas paraphrasing shortens traces but harms accuracy. These findings provide new evidence on how RLLMs maintain reasoning integrity, identify doubt as a central recovery mechanism, and highlight trade-offs between robustness and efficiency that future training methods should address.