Can LLMs Truly Embody Human Personality? Analyzing AI and Human Behavior Alignment in Dispute Resolution
作者: Deuksin Kwon, Kaleen Shrestha, Bin Han, Spencer Lin, James Hale, Jonathan Gratch, Maja Matarić, Gale M. Lucas
分类: cs.AI, cs.CL
发布日期: 2026-02-07
备注: AAAI 2026 (Special Track: AISI)
💡 一句话要点
评估LLM在冲突解决中模拟人类个性的能力,揭示其与人类行为的差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人格模拟 冲突解决 行为评估 人机交互
📋 核心要点
- 现有方法难以验证LLM在模拟人类社会行为时,能否准确反映人格特质对行为的影响。
- 论文提出一个评估框架,通过比较LLM和人类在冲突解决中的行为,分析人格与行为的关联。
- 实验结果表明,当前LLM在模拟人格驱动的冲突行为时,与人类数据存在显著差异。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于模拟法律调解、谈判和争端解决等社会环境中的人类行为。然而,这些模拟是否能重现人类的个性-行为模式仍不清楚。例如,人类的个性会影响个体在社会互动中的行为方式,包括在情绪激动的互动中的策略选择和行为。本文旨在探讨:当被赋予人格特质时,LLM是否能重现人格驱动的人类冲突行为差异?为此,我们引入了一个评估框架,该框架能够直接比较人与人以及LLM与LLM在争端解决对话中的行为,并结合大五人格量表(BFI)的人格特质。该框架提供了一组与战略行为和冲突结果相关的可解释指标。此外,我们还贡献了一种新颖的数据集创建方法,用于生成具有匹配场景和人格特质的LLM争端解决对话,并与人类对话进行比较。最后,我们使用三个闭源LLM展示了我们的评估框架,并表明与人类数据相比,不同LLM中人格在冲突中的表现存在显著差异,这挑战了人格提示代理可以作为具有社会影响力的应用中可靠的行为代理的假设。我们的工作强调了在实际应用之前,AI模拟需要心理学基础和验证。
🔬 方法详解
问题定义:论文旨在解决LLM是否能够准确地模拟人类在冲突解决场景中,由人格特质驱动的行为差异这一问题。现有方法缺乏有效的评估框架,无法直接比较LLM和人类在冲突解决中的行为模式,从而难以验证LLM作为人类行为代理的可靠性。
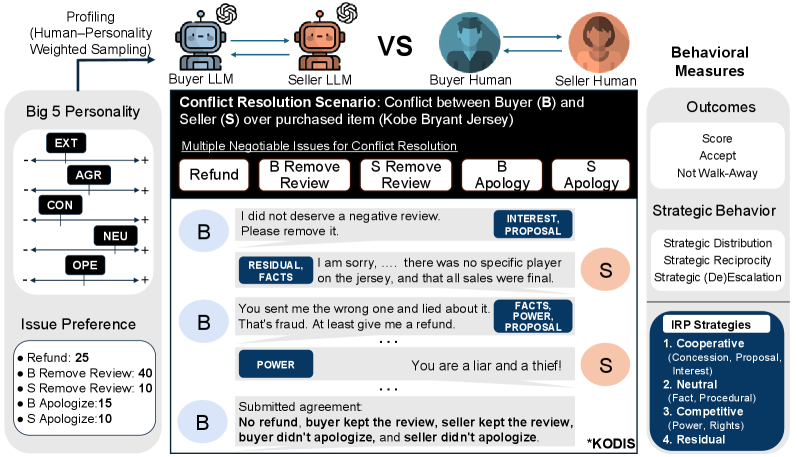
核心思路:论文的核心思路是构建一个评估框架,该框架能够量化和比较LLM和人类在冲突解决对话中的行为,并结合大五人格量表(BFI)的人格特质进行分析。通过比较LLM和人类在战略行为和冲突结果方面的差异,评估LLM模拟人格驱动行为的能力。
技术框架:该研究的技术框架主要包含以下几个阶段:1) 数据集构建:创建包含人类对话和LLM生成对话的数据集,其中对话场景和参与者的人格特质相匹配。2) 行为指标提取:从对话中提取与战略行为和冲突结果相关的可解释指标,例如让步程度、威胁使用频率等。3) 评估框架应用:使用评估框架比较LLM和人类在这些指标上的表现,分析人格特质对行为的影响。4) 结果分析:分析LLM和人类在人格驱动的冲突行为方面的差异,评估LLM作为人类行为代理的可靠性。
关键创新:论文的关键创新在于:1) 提出了一个用于评估LLM在冲突解决中模拟人类个性的评估框架。2) 贡献了一种新颖的数据集创建方法,用于生成具有匹配场景和人格特质的LLM争端解决对话。3) 通过实验验证了当前LLM在模拟人格驱动的冲突行为时,与人类数据存在显著差异。
关键设计:论文的关键设计包括:1) 使用大五人格量表(BFI)来定义人格特质。2) 设计了一系列可解释的行为指标,用于量化和比较LLM和人类在冲突解决中的行为。3) 采用配对实验设计,确保LLM和人类在相同的场景和人格特质下进行对话。
🖼️ 关键图片

📊 实验亮点
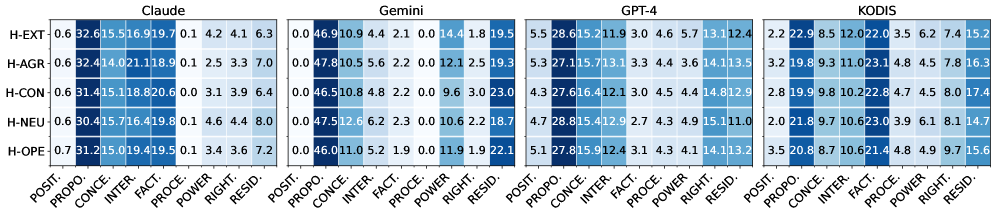
实验结果表明,三个闭源LLM在模拟人格驱动的冲突行为时,与人类数据存在显著差异。具体而言,LLM在某些行为指标上表现出与人类不同的模式,例如,在让步程度和威胁使用频率方面。这些差异表明,当前LLM在理解和模拟人类人格对行为的影响方面仍存在局限性,挑战了人格提示代理可以作为可靠行为代理的假设。
🎯 应用场景
该研究成果可应用于开发更可靠的AI行为模拟器,用于培训、决策支持和人机交互等领域。例如,可以利用该框架评估和改进AI在谈判、调解和客户服务等场景中的表现,使其更好地理解和适应人类的情感和行为模式。此外,该研究也为AI伦理和安全提供了重要参考,强调了在实际应用之前,对AI模拟进行心理学验证的必要性。
📄 摘要(原文)
Large language models (LLMs) are increasingly used to simulate human behavior in social settings such as legal mediation, negotiation, and dispute resolution. However, it remains unclear whether these simulations reproduce the personality-behavior patterns observed in humans. Human personality, for instance, shapes how individuals navigate social interactions, including strategic choices and behaviors in emotionally charged interactions. This raises the question: Can LLMs, when prompted with personality traits, reproduce personality-driven differences in human conflict behavior? To explore this, we introduce an evaluation framework that enables direct comparison of human-human and LLM-LLM behaviors in dispute resolution dialogues with respect to Big Five Inventory (BFI) personality traits. This framework provides a set of interpretable metrics related to strategic behavior and conflict outcomes. We additionally contribute a novel dataset creation methodology for LLM dispute resolution dialogues with matched scenarios and personality traits with respect to human conversations. Finally, we demonstrate the use of our evaluation framework with three contemporary closed-source LLMs and show significant divergences in how personality manifests in conflict across different LLMs compared to human data, challenging the assumption that personality-prompted agents can serve as reliable behavioral proxies in socially impactful applications. Our work highlights the need for psychological grounding and validation in AI simulations before real-world use.