VGAS: Value-Guided Action-Chunk Selection for Few-Shot Vision-Language-Action Adaptation
作者: Changhua Xu, Jie Lu, Junyu Xuan, En Yu
分类: cs.AI, cs.CV
发布日期: 2026-02-07
备注: Preprint
🔗 代码/项目: GITHUB
💡 一句话要点
VGAS:面向少样本视觉-语言-动作自适应的价值引导动作块选择
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 少样本学习 动作块选择 几何推理 Transformer 机器人操作 价值函数学习
📋 核心要点
- 现有VLA模型在少样本自适应中,易受几何歧义影响,导致执行失败。
- VGAS框架通过生成-选择策略,利用几何感知的Transformer评论器筛选动作块。
- 实验表明,VGAS在少样本和分布偏移下,显著提升了VLA模型的成功率和鲁棒性。
📝 摘要(中文)
视觉-语言-动作(VLA)模型将多模态推理与物理控制相结合,但将其应用于少量演示的新任务仍然不可靠。微调的VLA策略通常产生语义上合理的轨迹,但失败通常源于未解决的几何歧义,在有限的监督下,近似动作候选会导致不同的执行结果。我们从“生成-选择”的角度研究少样本VLA自适应,并提出了一个新的框架VGAS(价值引导动作块选择)。它执行推理时best-of-N选择,以识别在语义上忠实且在几何上精确的动作块。具体来说,VGAS采用微调的VLA作为高召回率的提议生成器,并引入了Q-Chunk-Former,这是一个几何接地的Transformer评论器,用于解决细粒度的几何歧义。此外,我们提出了显式几何正则化(EGR),它显式地塑造了一个区分性的价值景观,以在近似候选者之间保持动作排序分辨率,同时减轻在稀缺监督下的价值不稳定性。实验和理论分析表明,VGAS在有限的演示和分布偏移下,始终提高成功率和鲁棒性。
🔬 方法详解
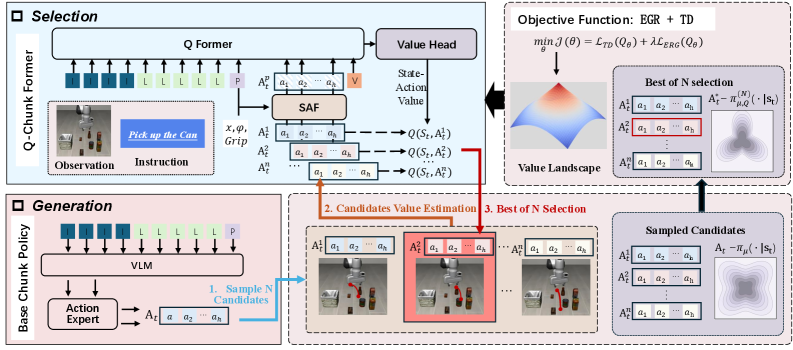
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在少样本学习场景下的自适应问题。现有方法,特别是微调后的VLA策略,虽然能生成语义上合理的轨迹,但由于几何歧义的存在,导致模型在执行过程中容易失败。具体来说,当存在多个近似的动作候选时,模型难以区分它们在几何上的细微差异,从而导致执行结果的显著偏差。这种问题在监督数据有限的情况下尤为突出。
核心思路:论文的核心思路是将少样本VLA自适应问题分解为“生成-选择”两个阶段。首先,利用一个微调的VLA模型作为提议生成器,生成多个候选动作块。然后,引入一个几何感知的评论器(Q-Chunk-Former)来评估这些候选动作块的质量,并选择最优的动作块执行。通过这种方式,论文旨在利用VLA模型的高召回率和评论器的几何精确性,从而提高模型在少样本场景下的自适应能力。
技术框架:VGAS框架主要包含以下几个模块: 1. VLA提议生成器:使用微调的VLA模型,根据视觉和语言输入,生成多个候选动作块。 2. Q-Chunk-Former:一个几何感知的Transformer评论器,用于评估候选动作块的质量。它以动作块和环境状态作为输入,输出一个Q值,表示该动作块的预期回报。 3. 显式几何正则化(EGR):一种正则化方法,用于塑造Q-Chunk-Former的价值景观,使其能够更好地区分近似的动作候选,并提高价值估计的稳定性。 4. Best-of-N选择:在推理时,从生成的N个候选动作块中选择Q值最高的动作块执行。
关键创新:论文的关键创新点在于以下几个方面: 1. 生成-选择框架:将少样本VLA自适应问题分解为生成和选择两个阶段,从而能够更好地利用VLA模型和几何感知的评论器。 2. Q-Chunk-Former:一个几何感知的Transformer评论器,能够有效地解决几何歧义问题。 3. 显式几何正则化(EGR):一种正则化方法,能够提高价值估计的稳定性和区分能力。
关键设计: * Q-Chunk-Former结构:采用Transformer结构,输入包括动作块和环境状态,通过自注意力机制学习动作块和环境状态之间的关系,输出Q值。 * 显式几何正则化(EGR):通过添加额外的损失函数,显式地约束Q-Chunk-Former的输出,使其能够更好地区分近似的动作候选。具体来说,EGR鼓励Q值高的动作块与Q值低的动作块之间保持一定的差距,从而提高价值估计的区分能力。 * Best-of-N选择:选择N个候选动作块中Q值最高的动作块执行,N是一个超参数,需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
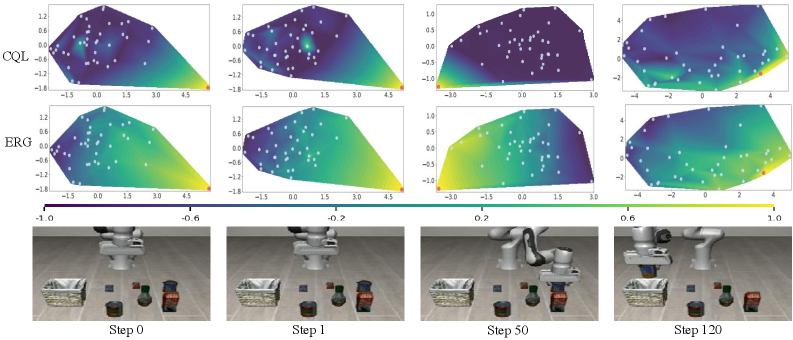
实验结果表明,VGAS框架在多个VLA任务上取得了显著的性能提升。例如,在少样本操作任务中,VGAS的成功率比基线方法提高了10%-20%。此外,VGAS在分布偏移的情况下也表现出更强的鲁棒性,表明其具有良好的泛化能力。消融实验验证了Q-Chunk-Former和显式几何正则化(EGR)的有效性。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、智能家居等领域。例如,在机器人操作中,可以利用VGAS框架使机器人能够快速适应新的操作任务,即使只有少量的演示数据。在自动驾驶中,可以提高自动驾驶系统在复杂环境下的决策能力和安全性。此外,该研究还可以促进人机协作的发展,使人类能够更方便地指导机器人完成任务。
📄 摘要(原文)
Vision--Language--Action (VLA) models bridge multimodal reasoning with physical control, but adapting them to new tasks with scarce demonstrations remains unreliable. While fine-tuned VLA policies often produce semantically plausible trajectories, failures often arise from unresolved geometric ambiguities, where near-miss action candidates lead to divergent execution outcomes under limited supervision. We study few-shot VLA adaptation from a \emph{generation--selection} perspective and propose a novel framework \textbf{VGAS} (\textbf{V}alue-\textbf{G}uided \textbf{A}ction-chunk \textbf{S}election). It performs inference-time best-of-$N$ selection to identify action chunks that are both semantically faithful and geometrically precise. Specifically, \textbf{VGAS} employs a finetuned VLA as a high-recall proposal generator and introduces the \textrm{Q-Chunk-Former}, a geometrically grounded Transformer critic to resolve fine-grained geometric ambiguities. In addition, we propose \textit{Explicit Geometric Regularization} (\texttt{EGR}), which explicitly shapes a discriminative value landscape to preserve action ranking resolution among near-miss candidates while mitigating value instability under scarce supervision. Experiments and theoretical analysis demonstrate that \textbf{VGAS} consistently improves success rates and robustness under limited demonstrations and distribution shifts. Our code is available at https://github.com/Jyugo-15/VGAS.